
SQL Server 2019: Celebrating 25 years of SQL Server Database Engine and the path forward
This post is authored by Amit Banerjee, Principal PM Manager, SQL Server and Bob Ward, Principal Architect, Microsoft SQL Server Data Services.
SQL Server has provided enterprises the capability to manage all facets of their relational data. Over the years, we have increasingly seen a convergence for the need of combining heterogenous sets of relational and non-relational data to meet the needs of business scenarios. This requires setting up a unified data platform that transcends the boundaries of all types of data. Incidentally, we are also celebrating 25 years since SQL Server first shipped on Windows NT in 1993. The heart of SQL Server is mission critical performance, security, and availability and the use of our database platform in mission-critical environments is a testament to that fact. The SQL Server 2019 preview relational engine will deliver new and enhanced features in the areas of mission-critical performance, security and compliance, and database availability, as well as additional features for developers, SQL Server on Linux and containers, and general engine enhancements.
Earlier at Ignite, Microsoft announced the first public Community Technology Preview (CTP 2.0) of SQL Server 2019. For the first time, SQL Server 2019 comes with big data capabilities built-in, with Apache Spark and Hadoop Distributed File System (HDFS) in the box—extending SQL Server beyond a traditional relational database. This blog post covers the database engine features that are available in first public Community Technology Preview (CTP 2.0) of SQL Server 2019.
An Intelligent database providing Industry-leading performance
The Intelligent Query Processing suite builds on hands-free performance tuning features of Adaptive Query Processing in SQL Server 2017 like row mode memory grant feedback, batch mode on rowstore, table variable deferred compilation. We have identified common classes of query performance problems which could benefit from automatic corrective approaches during runtime based on changes in cardinality or through leveraging a feedback loop based on statistics from past executions. These are features that we have already started leveraging in Azure SQL Database and remain a top investment area for SQL Server 2019.
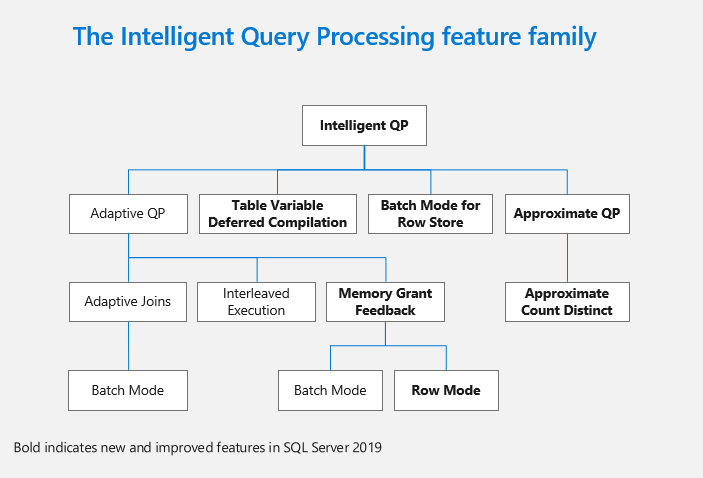
These are new changes to our query processor which are available with database compatibility level = 150 keeping in line with our database compatibility based upgrade promise. Database compatibility level provides an easy certification path for an existing application which helps with future upgrades to new releases where the database compatibility mode remains the same. This allows our customers to reduce the effort require to leverage capabilities in latest releases for availability, performance and security without having to worry about re-certifying the entire application on a newer release.
Persistent memory support is improved in this release with a new, optimized I/O path available for interacting with persistent memory storage. Any SQL Server file that is placed on a persistent memory device allows SQL Server to directly accesses the device, bypassing the storage stack of the operating system. This mode improves performance by significantly improving low latency input/output without any change to your application or database design. The ability for an existing database schema to leverage significant throughput gains allows existing applications with I/O bound bottlenecks.
The lightweight query profiling infrastructure is now enabled by default to provide per query operator statistics anytime and anywhere you need it. This provides the ability to look back in time and investigate query performance issues. We also decided to extend this capability to queries that are running on the server. This allows SQL Server administrators the ability to leverage Management Studio’s Live Query Statistics or the new DMF, sys.dm_exec_query_statistics_xml, to perform live troubleshooting of a current performance problem without needing to turn on any diagnostic data collection.
Enhanced security enabling Confidential Computing
Earlier this year, we announced Confidential Computing with Always Encrypted using Enclaves for Azure SQL Database. Now we have Always Encrypted with secure enclaves for SQL Server 2019 preview which extends the client-side encryption technology introduced in SQL Server 2016. Secure enclaves protect sensitive data in a hardware or software-created enclave inside the database, securing it from malware and privileged users during advanced operations on encrypted data.
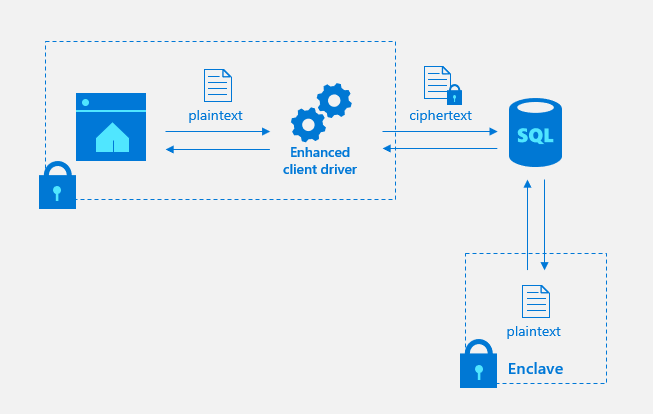
SQL Data Discovery and Classification is now built into the SQL Server engine with new metadata and auditing support which allows you to create solutions for key compliance requirements. We now have the ability for SQL Server catalog metadata to persist information about user-defined data classification labels.
Certificate management is now integrated into the SQL Server Configuration Manager, simplifying common tasks like deploying certificates across machines participating in a failover cluster instance or availability group. This removes the overhead of managing certificates separately on each node of the SQL Server failover cluster or availability group instance.
Mission-critical availability to keep your SQL Server running
Always On Availability Groups have been enhanced to include automatic redirection of connections based on read/write intent. This capability allows applications to be redirected to the primary replica without requiring a listener for handling scenarios where creation of a listener is not possible. This gives an opportunity for legacy applications which depend on a hard-coded server/host name but can still leverage Availability Groups on upgrade by redirection to the original replica after a failover.
High availability configurations for SQL Server running in containers can be enabled with Always On Availability Groups using Kubernetes as an orchestration layer. A Kubernetes operator deploys a Stateful Set including a container with mssql-server container and a health monitor. This introduces a tighter integration between SQL Server availability groups and Kubernetes. The operator will be available in the Microsoft Container Registry for SQL Server 2019 preview.

SQL Server Always On availability groups will support up to 5 synchronous replicas (1 primary and 4 synchronous secondary) with automatic failover support. This increases your ability to sustain simultaneous failures within or across data centers using SQL Server’s high availability and disaster recovery features.
We are enhancing the capability of resumable online index DDL by allowing users to restart from the last point the rowstore index create was paused or failed. This allows you the ability to continue an online index build after an outage, database failover or even stopping the operation to free up resources on the SQL Server instance.
Clustered Columnstore indexes can now be created and rebuilt online to help improve uptime for hybrid transaction analytical processing (HTAP) environments.
SQL Server Machine Learning Services will now support clustering which allows you to have a highly available intelligent database for both OLTP and Machine Learning scenarios.
Enhancing the developer experience
We are introducing UTF-8 support, a widely used character encoding format, which can provide significant storage savings up to 50 percent for your character data. This allows you to compress your existing character data without the need to write additional routines and leverage external software to compress existing data. The ability to convert existing data to UTF-8 collations will allow existing databases to leverage this new capability for storage savings.
Enhancements to SQL Graph include match support with T-SQL MERGE and edge constraints.
We are extending the ability for SQL Server to leverage common programming languages by adding Java. We already have the ability for customers to leverage CLR, R and Python in earlier releases of SQL Server. The new Java language extension will allow you to call a pre-compiled Java program and securely execute Java code on the same server with SQL Server. This reduces the need to move data and improves application performance by bringing your workloads closer to your data. This extension is installed when you add the feature ‘Machine Learning Services (in-database)’ to your SQL Server instance. And since SQL Server on Linux uses the same database engine code, you can execute the same compiled Java classes on both SQL Server on Linux and Windows.
Machine Learning Services has several enhancements for partitioned models, and support for SQL Server on Linux. We now have the ability to process external scripts per partition which supports training many small models (one model per partition of data) instead of one large model and there by providing the ability to leverage SQL Server machine learning services across your partitions. This allows you to create a partitioned training strategy across archived data sets without having to incur the performance cost of training over all your data in a single monolithic operation.
Azure Data Studio, previously SQL Operations Studio, is now generally available. Azure Data Studio is a free tool that runs on Windows, macOS, and Linux, for managing SQL Server, Azure SQL Database, and Azure SQL Data Warehouse; wherever they’re running. SQL Server Management Studio 18.0 Preview will also be available for customers to continue managing SQL Servers with the support for SQL Server 2019 Public Preview.
Platform of choice
The preview container images of SQL Server will be available on the Microsoft Container Registry along with the new certified RHEL-based SQL Server container image available on the Red Hat Container Catalog. This allows users to leverage well known commands to setup a RHEL image with SQL Server running on it in a matter of seconds improving the ability to deploy and manage their environment where SQL Server running on Red Hat is a requirement.
We are introducing new connectors for PolyBase to external data for SQL Server, Oracle, Teradata, and MongoDB which allows you to create a unified data platform using the SQL Server database engine. We have redesigned PolyBase to allow you to connect to ODBC sources, other relational databases, NoSQL and Big Data environments which enables scenarios like building new application capabilities using SQL Server as a data hub without duplicating data and system of records.
Additional capabilities for SQL Server on Linux include distributed transactions, replication, Machine Learning Services, and OpenLDAP support. These features are driven by customer demand from customer running or evaluating SQL Server on Linux for production use.

We continue to listen to customer feedback and provide features, enhancements and innovation which help our customers run mission and business critical environments on SQL Server. Our new capabilities on SQL Server on Linux along with engine enhancements in SQL Server 2019 Preview features like columnstore statistics support for DBCC CLONEDATABASE, compression estimates for columnstore indexes, and new T-SQL built-in functions to discover details for page resource waits are examples of such customer driven engineering
We also wanted to point out that SQL Server 2008 and SQL Server 2008 R2 will be approaching end of support during July 2019. Microsoft is making options available for you to successfully modernize your data platform while staying secure on your existing environment. Please read about SQL Server 2008 and 2008 R2 End of Extended Support for more information.
Get started now
- Preview SQL Server 2019 for Windows, Linux, or Docker.
- Sign up for the Early Adoption Program to get advice and support for your project from SQL Server engineering, or to try SQL Server 2019 big data clusters.
- Download Azure Data Studio to get started with new SQL Server big data features like data virtualizations and notebooks.
