

Introducing Microsoft SQL Server 2019 Big Data Clusters
Yesterday at the Microsoft Ignite conference, we announced that SQL Server 2019 is now in preview and that SQL Server 2019 will include Apache Spark and Hadoop Distributed File System (HDFS) for scalable compute and storage. This new architecture that combines together the SQL Server database engine, Spark, and HDFS into a unified data platform is called a “big data cluster.”
For 25 years, Microsoft SQL Server has been powering data-driven organizations. As the variety of types of data and the volume of that data has risen, the number of types of databases has risen dramatically. Over the years, SQL Server has kept pace by adding support for XML, JSON, in-memory, and graph data in the database. It has become a flexible database engine that enterprises can count on for industry-leading performance, high availability, and security. However, a single instance of SQL Server was never designed or built to be a database engine for analytics on the scale of petabytes or exabytes. It also was not designed for scale-out compute for data processing or machine learning, nor for storing and analyzing data in unstructured formats, such as media files.
SQL Server 2019 preview extends its unified data platform to embrace big and unstructured data by deploying multiple instances of SQL Server together with Spark and HDFS as a big data cluster.
When Microsoft added support for Linux in SQL Server 2017, it opened the possibility of deeply integrating SQL Server with Spark, the HDFS, and other big data components that are primarily Linux-based. SQL Server 2019 big data clusters take that to the next step by fully embracing the modern architecture of deploying applications – even stateful ones like a database – as containers on Kubernetes. Deploying SQL Server 2019 big data clusters on Kubernetes ensures a predictable, fast, and elastically scalable deployment, regardless of where it is deployed. Big data clusters can be deployed in any cloud where there is a managed Kubernetes service, such as Azure Kubernetes Service (AKS), or in on-premises Kubernetes clusters, such as AKS on Azure Stack. Built-in management services in a big data cluster provide log analytics, monitoring, backup, and high availability through an administrator portal, ensuring a consistent management experience wherever a big data cluster is deployed.
The SQL Server 2019 relational database engine in a big data cluster leverages an elastically scalable storage layer that integrates SQL Server and HDFS to scale to petabytes of data storage. The Spark engine that is now part of SQL Server enables data engineers and data scientists to harness the power of open source data preparation and query programming libraries to process and analyze high-volume data in a scalable, distributed, in-memory compute layer.
 Figure 1: SQL Server and Spark are deployed together with HDFS creating a shared data lake
Figure 1: SQL Server and Spark are deployed together with HDFS creating a shared data lake
Data integration through data virtualization
While extract, transform, load (ETL) has its use cases, an alternative to ETL is data virtualization, which integrates data from disparate sources, locations, and formats, without replicating or moving the data, to create a single “virtual” data layer. Data virtualization enables unified data services to support multiple applications and users. The virtual data layer—sometimes referred to as a data hub—allows users to query data from many sources through a single, unified interface. Access to sensitive data sets can be controlled from a single location. The delays inherent to ETL need not apply; data can always be up to date. Storage costs and data governance complexity are minimized.
SQL Server 2019 big data clusters with enhancements to PolyBase act as a data hub to integrate structured and unstructured data from across the entire data estate–SQL Server, Azure SQL Database, Azure SQL Data Warehouse, Azure Cosmos DB, MySQL, PostgreSQL, MongoDB, Oracle, Teradata, , HDFS, and more – using familiar programming frameworks and data analysis tools.
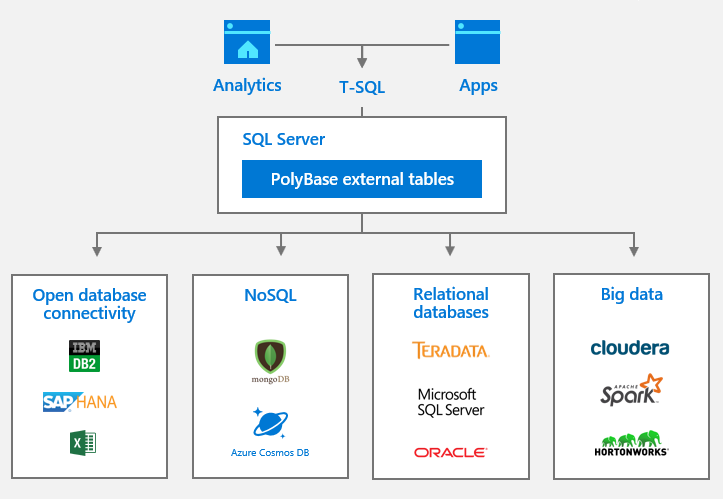 Figure 2: Data sources that can be integrated by PolyBase in SQL Server 2019
Figure 2: Data sources that can be integrated by PolyBase in SQL Server 2019
In SQL Server 2019 big data clusters, the SQL Server engine has gained the ability to natively read HDFS files, such as CSV and parquet files, by using SQL Server instances collocated on each of the HDFS data nodes to filter and aggregate data locally in parallel across all of the HDFS data nodes.
Performance of PolyBase queries in SQL Server 2019 big data clusters can be boosted further by distributing the cross-partition aggregation and shuffling of the filtered query results to “compute pools” comprised of multiple SQL Server instances that work together.
When you combine the enhanced PolyBase connectors with SQL Server 2019 big data clusters data pools, data from external data sources can be partitioned and cached across all the SQL Server instances in a data pool, creating a “scale-out data mart”. There can be more than one scale-out data mart in a given data pool, and a data mart can combine data from multiple external data sources and tables, making it easy to integrate and cache combined data sets from multiple external sources.
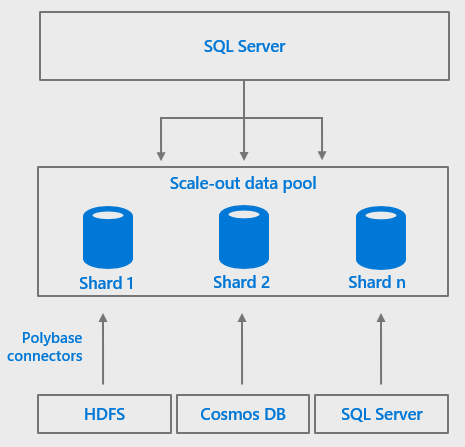
Figure 3: Using a scale-out data pool to cache data from external data sources for better performance
A complete AI platform built on a shared data lake with SQL Server, Spark, and HDFS
SQL Server 2019 big data clusters make it easier for big data sets to be joined to the dimensional data typically stored in the enterprise relational database, enabling people and apps that use SQL Server to query big data more easily. The value of the big data greatly increases when it is not just in the hands of the data scientists and big data engineers but is also included in reports, dashboards, and applications. At the same time, the data scientists can continue to use big data ecosystem tools while also utilizing easy, real-time access to the high-value data in SQL Server because it is all part of one integrated, complete system.
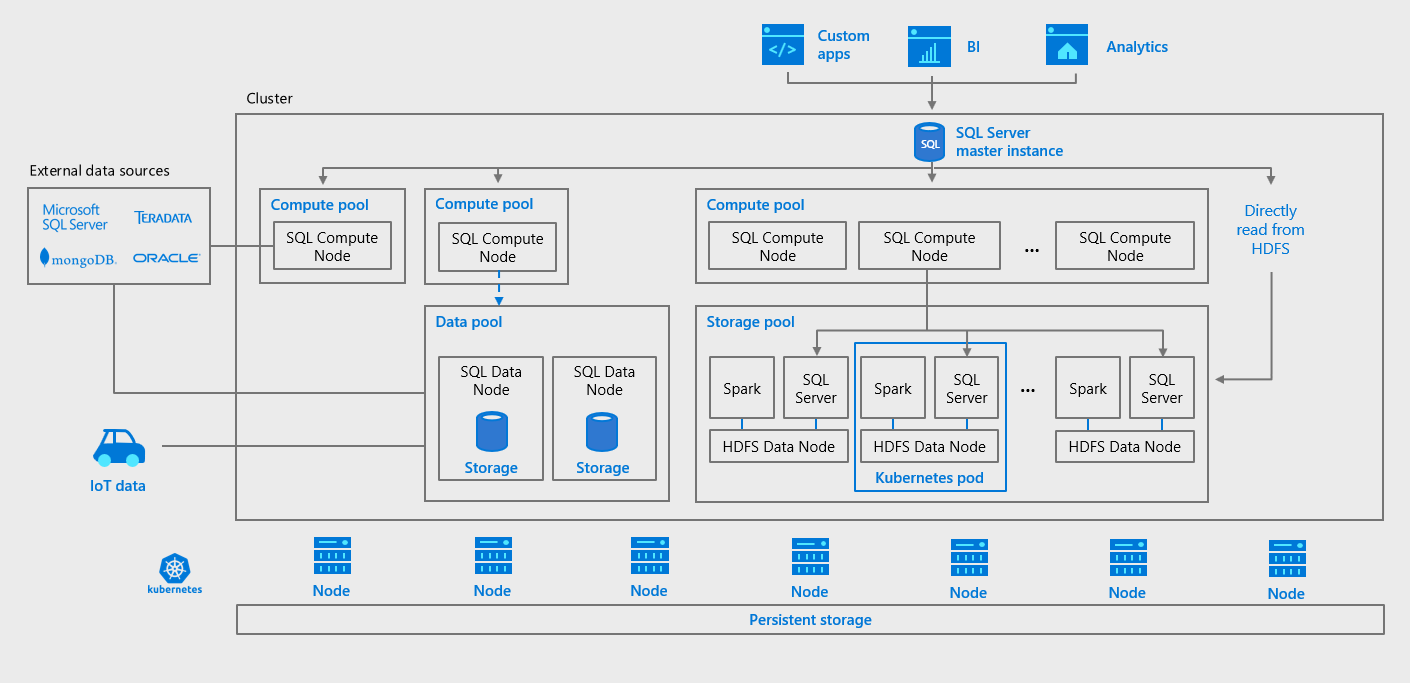 Figure 4: A scalable compute and storage architecture in SQL Server 2019 big data cluster
Figure 4: A scalable compute and storage architecture in SQL Server 2019 big data cluster
SQL Server 2019 big data clusters provide a complete AI platform. Data can be easily ingested via Spark Streaming or traditional SQL inserts and stored in HDFS, relational tables, graph, or JSON/XML. Data can be prepared by using either Spark jobs or Transact-SQL (T-SQL) queries and fed into machine learning model training routines in either Spark or the SQL Server master instance using a variety of programming languages, including Java, Python, R, and Scala. The resulting models can then be operationalized in batch scoring jobs in Spark, in T-SQL stored procedures for real-time scoring, or encapsulated in REST API containers hosted in the big data cluster.
SQL Server big data clusters provide all the tools and systems to ingest, store, and prepare data for analysis as well as to train the machine learning models, store the models, and operationalize them.
Data can be ingested using Spark Streaming, by inserting data directly to HDFS through the HDFS API, or by inserting data into SQL Server through standard T-SQL insert queries. The data can be stored in files in HDFS, or partitioned and stored in data pools, or stored in the SQL Server master instance in tables, graph, or JSON/XML. Either T-SQL or Spark can be used to prepare data by running batch jobs to transform the data, aggregate it, or perform other data wrangling tasks.
Data scientists can choose either to use SQL Server Machine Learning Services in the master instance to run R, Python, or Java model training scripts or to use Spark. In either case, the full library of open-source machine learning libraries, such as TensorFlow or Caffe, can be used to train models.
Lastly, once the models are trained, they can be operationalized in the SQL Server master instance using real-time, native scoring via the PREDICT function in a stored procedure in the SQL Server master instance; or you can use batch scoring over the data in HDFS with Spark. Alternatively, using tools provided with the big data cluster, data engineers can easily wrap the model in a REST API and provision the API + model as a container on the big data cluster as a scoring microservice for easy integration into any application.
Importantly, this entire pipeline all happens in the context of a SQL Server big data cluster. The data never leaves the security and compliance boundary to go to an external machine learning server or a data scientist’s laptop. The full power of the hardware underlying the big data cluster is available to process the data, and the compute resources can be elastically scaled up and down as needed.
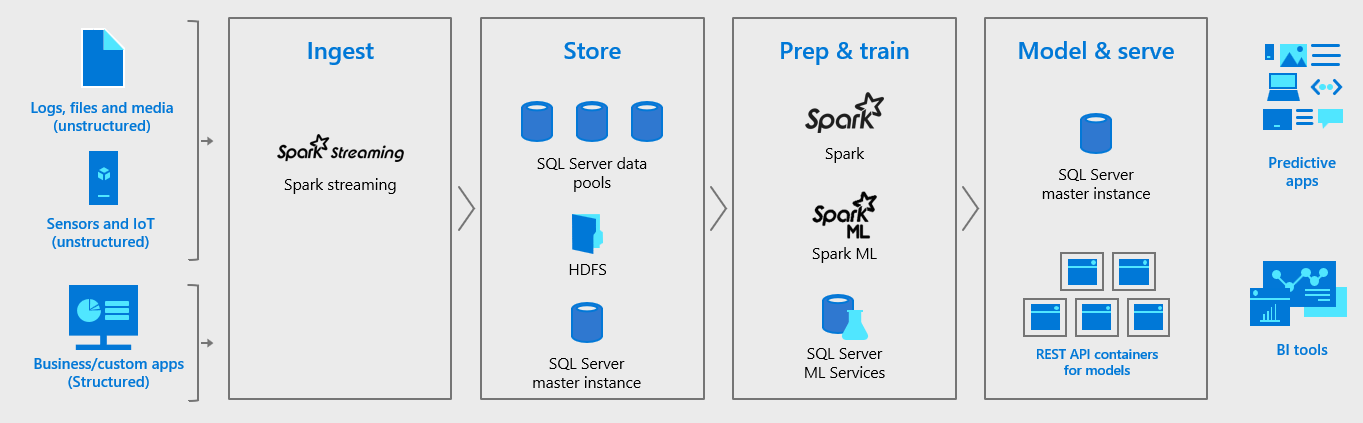 Figure 5: A complete AI platform: SQL Server 2019 big data cluster
Figure 5: A complete AI platform: SQL Server 2019 big data cluster
Azure Data Studio is an open-source, multi-purpose data management and analytics tool for DBAs, data scientists, and data engineers. New extensions for Azure Data Studio integrate the user experience for working with relational data in SQL Server with big data. The new HDFS browser lets analysts, data scientists, and data engineers easily view the HDFS files and directories in the big data cluster, upload/download files, open them, and delete them if needed. The new built-in notebooks in Azure Data Studio are built on Jupyter, enabling data scientists and engineers to write Python, R, or Scala code with Intellisense and syntax highlighting before submitting the code as Spark jobs and viewing the results inline. Notebooks facilitate collaboration between teammates working on a data analysis project together. Lastly, the External Table Wizard simplifies the process of creating external data sources and tables, including column mappings.
Conclusion
SQL Server 2019 big data clusters are a compelling new way to utilize SQL Server to bring high-value relational data and high-volume big data together on a unified, scalable data platform. Enterprises can leverage the power of PolyBase to virtualize their data stores, create data lakes, and create scalable data marts in a unified, secure environment without needing to implement slow, costly ETL pipelines. This makes data-driven applications and analysis more responsive and productive. SQL Server 2019 big data clusters provide a complete AI platform to deliver the intelligent applications that help make any organization more successful.
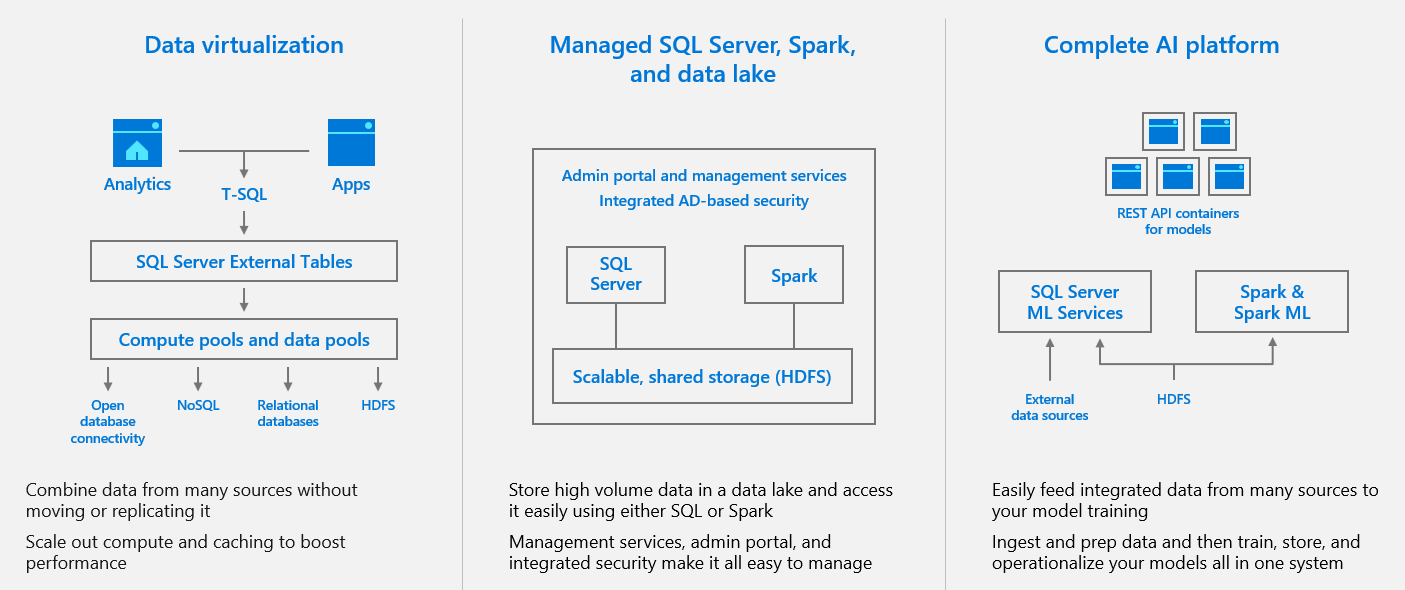
Figure 6: SQL Server 2019 big data cluster summary
Getting started
- Sign up for the Early Adoption Program if you would like to try out the new SQL Server 2019 big data clusters!
- Read more about the details of big data clusters in the SQL Server 2019 Big Data Clusters white paper.
