
Towards Explainable Collaborative Filtering with Taste Clusters Learning
- Yuntao Du ,
- Jianxun Lian ,
- Jing Yao ,
- Xiting Wang ,
- Mingqi Wu ,
- Lu Chen ,
- Yunjun Gao ,
- Xing Xie
the Web Conference 2023 |
Collaborative Filtering (CF) is a widely used and effective technique for recommender systems. In recent decades, there have been significant advancements in latent embedding-based CF methods for improved accuracy, such as matrix factorization, neural collaborative filtering, and LightGCN. However, the explainability of these models has not been fully explored. Adding explainability to recommendation models can not only increase trust in the decision-making process, but also have multiple benefits such as providing persuasive explanations for item recommendations, creating explicit profiles for users and items, and assisting item producers in design improvements.
In this paper, we propose a neat and effective Explainable Collaborative Filtering (ECF) model that leverages interpretable cluster learning to achieve the two most demanding objectives: (1) Precise – the model should not compromise accuracy in the pursuit of explainability; and (2) Self-explainable – the model’s explanations should truly reflect its decision-making process, not generated from post-hoc methods.
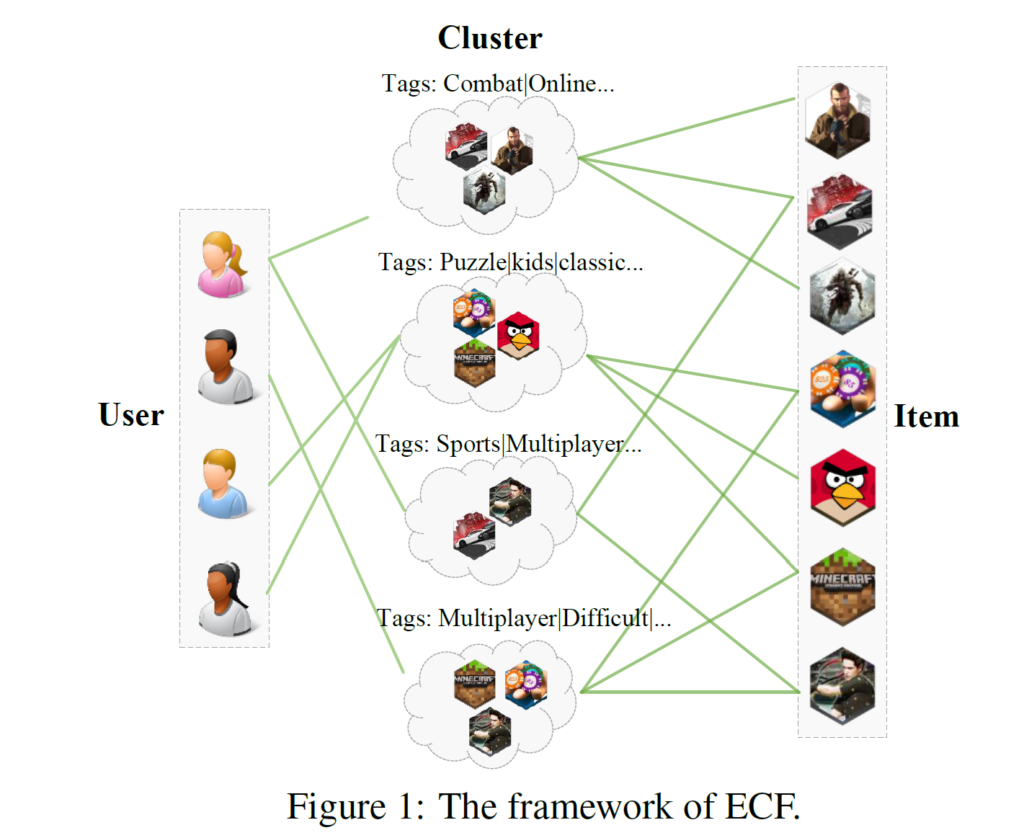
The core of ECF is mining taste clusters from user-item interactions and item profiles. We map each user and item to a sparse set of taste clusters, and taste clusters are distinguished by a few representative tags. The user-item preference, users/items’ cluster affiliations, and the generation of taste clusters are jointly optimized in an end-to-end manner. Additionally, we introduce a forest mechanism to ensure the model’s accuracy, explainability, and diversity. To comprehensively evaluate the explainability quality of taste clusters, we design several quantitative metrics, including in-cluster item coverage, tag utilization, silhouette, and informativeness. Our model’s effectiveness is demonstrated through extensive experiments on three real-world datasets.