

Introduction
In today’s data-driven world, organizations strive to leverage data to train and adapt AI models. However, this pursuit often faces an important challenge: balancing the value of data with the need to safeguard individuals’ right to privacy and comply with data privacy regulations like the General Data Protection Regulation (opens in new tab) (GDPR) and the EU AI Act (opens in new tab).
Synthetic data has emerged as a powerful solution to privacy and compliance challenges. It allows organizations to create realistic and useful datasets, tailored to specific use cases, without compromising individual privacy. This enables organizations to:
- Train and adapt AI models: Synthetic data can be used to train and adapt models to specific domains and industries, even when real-world data is limited, or privacy concerns exist.
- Comply with regulations: Since it doesn’t require user data, synthetic data generation helps organizations adhere to data privacy regulations.
- Unlock new possibilities: Synthetic data opens doors to innovative AI applications that were previously limited by data availability or privacy constraints.
Microsoft’s Phi-3 (opens in new tab) small language model (SLM) is a good example of how synthetic data can contribute to responsible AI development, enabling the creation of powerful language models without compromising privacy. Phi-3 leverages a combination of “textbook quality” web data and LLM-generated synthetic content, creating a strategic approach that doesn’t need real-world personal data.
Spotlight: On-demand video

AI Explainer: Foundation models and the next era of AI
Explore how the transformer architecture, larger models and more data, and in-context learning have helped advance AI from perception to creation.
However, synthetic data carries limitations. It can be difficult to artificially generate realistic data that anticipates a wide range of use cases and individual scenarios. Furthermore, synthetic data generated by pre-trained large-language models (LLMs) can sometimes reduce accuracy and increase bias on down-stream tasks (opens in new tab). So, how could we generate synthetic data that accurately captures the diversity and specificity of private data while maintaining strict privacy protections for data contributors?
Differential privacy: A bridge between innovation and privacy
Differentially private (DP) synthetic data generation is a promising solution. It allows developers to pursue innovations in machine learning while prioritizing privacy. The goal of synthetic data generation is to produce data statistically similar to real-world data sources. However, when the data is too similar, replicating uniquely identifying details of the source data, the promise of preserving privacy is compromised. This is where DP can help. DP is a mathematical framework for providing a guarantee that a particular computation is relatively invariant to the addition or removal of a single data contributor. Using DP techniques, researchers can generate synthetic datasets that retain the statistical properties of the original data while ensuring that information that could help identify data contributors remains obscured.
This blog post explores recent advancements in private synthetic data generation. We examine four recently published research papers that propose innovative techniques for generating synthetic data with strong privacy guarantees, while maintaining its usefulness for analytics, training AI models, and other tasks.
- Synthetic Text Generation with Differential Privacy: A Simple and Practical Recipe (opens in new tab) by Yue et al., which appeared at ACL 2023 (opens in new tab), proposes using DP in the fine-tuned training process of a generative LLM. This approach injects noise into the model’s updates during training, ensuring privacy guarantees while maintaining the model’s ability to generate realistic text.
- Differentially Private Synthetic Data via Foundation Model APIs 1: Images (opens in new tab) and Differentially Private Synthetic Data via Foundation Model APIs 2: Text (opens in new tab) by Lin, Xie, et al., which appeared at ICLR 2024 (opens in new tab) and ICML 2024 (opens in new tab), respectively, present an approach to data synthesis that focuses on leveraging pre-trained foundation models as black boxes. This method utilizes differentially private queries to the models’ inference APIs for data generation, offering an API-based, training-free approach.
- Privacy-Preserving In-Context Learning with Differentially Private Few-Shot Generation by Tang et al., which appeared at ICLR 2024, explores applying DP to the task of few-shot learning, where models are conditioned on a handful of synthetically generated demonstration examples at inference time. This approach is useful when only private labeled examples are available, and the generalizing power of an LLM can be leveraged to solve an in-context task.
In the remainder of this blog post, we describe each approach in more detail, and present experimental results illustrating their value.
Technical deep dive: Differentially private synthetic data generation
Synthetic Text Generation with Differential Privacy: A Simple and Practical Recipe
Generative LLMs offer the opportunity to produce synthetic text by sampling from LLM outputs. One avenue to generating realistic synthetic text is to fine-tune an LLM using representative data. For example, we could consider fine-tuning a pre-trained LLM on a corpus of scientific papers, enabling the model to more readily produce text that captures the knowledge and writing style used in scientific writing. Suppose, however, that we want to produce synthetic text based on a private corpus of documents. What steps can we take to protect the document authors and any sensitive information in their documents? For example, we may want to produce synthetic medical notes, or personal emails. LLMs have a well-known capacity to memorize training examples, and a model with the potential for reproducing samples from the training set might pose significant privacy risks.
In the paper Synthetic Text Generation with Differential Privacy: A Simple and Practical Recipe, researchers from Microsoft presented an approach to leveraging a private data corpus for synthetic generation, without compromising the privacy of the data subjects. This approach uses differentially private stochastic gradient descent (DP-SGD) to fine-tune an LLM on the private documents with a strong privacy guarantee. Differentially private model training provides a mathematical guarantee that the trained model parameters, and any subsequent model outputs, are relatively unaffected by the addition or removal of any single user’s training examples.
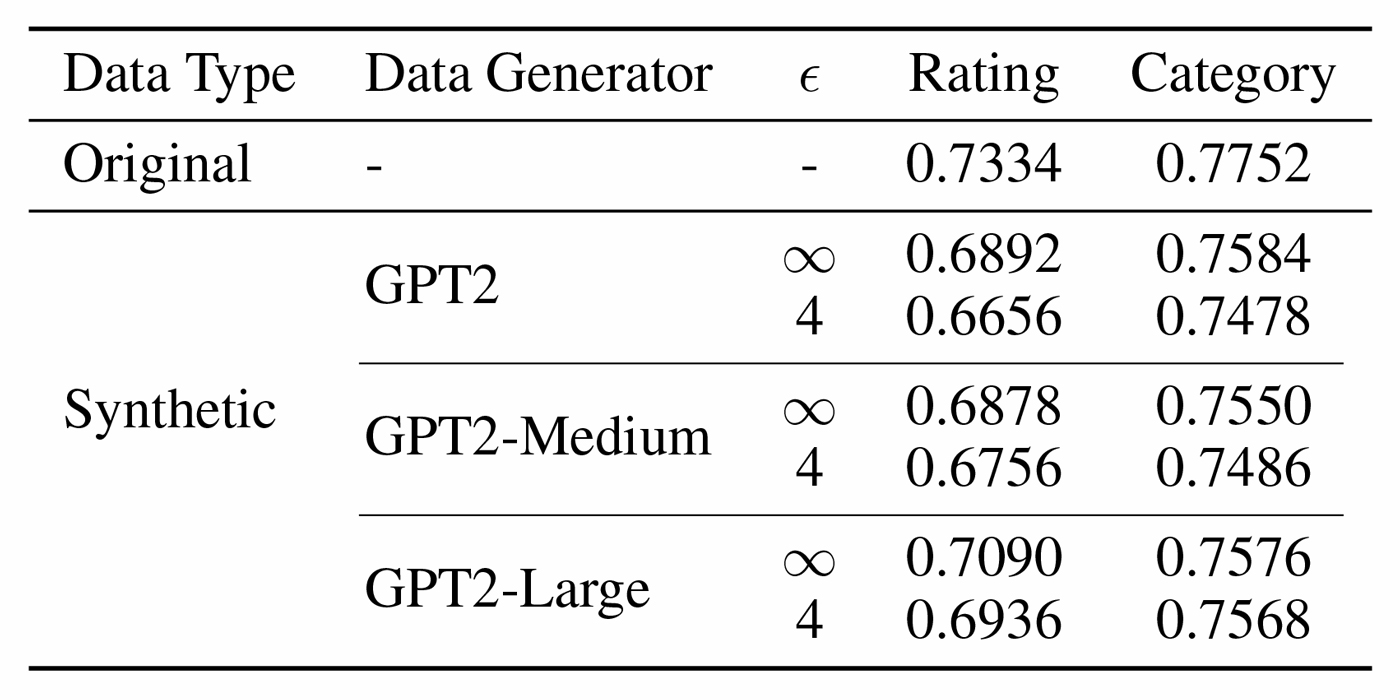
The synthetic generation approach described in this work was validated by training on restaurant reviews with varying levels of privacy protection, then prompting the model to generate novel reviews. These reviews were then used for downstream classification tasks, such as sentiment prediction and restaurant genre classification, and the results, which are shown in Table 1, demonstrated only small accuracy penalties compared to training on the raw private data. This approach unlocks a powerful way for realistic synthetic data to be generated from private data without compromising privacy or confidentiality.
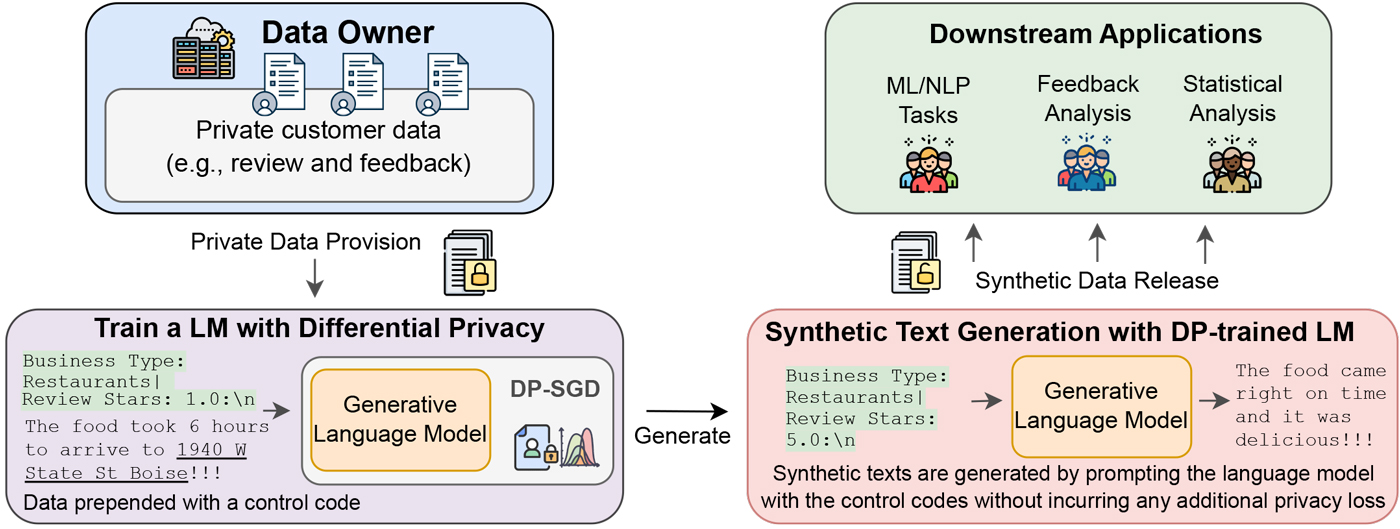
Differentially Private Synthetic Data via Foundation Model APIs
While the ACL paper demonstrated a robust approach to synthetic data generation, fine-tuning a large model can be impractical. Model training requires significant computing capacity and some of the most powerful models available are proprietary and not accessible for DP training. Recognizing this challenge, researchers at Microsoft explored whether synthetic data can be generated directly using only inference API access to a model, even while utilizing an untrusted model controlled by a third party. Crucially, the synthetic data should resemble a targeted private corpus, and yield a similar DP guarantee as was met in the previous work based on model training. In two separate papers, the authors demonstrate an approach to this problem using a differentially private sampling approach called Private Evolution (PE).
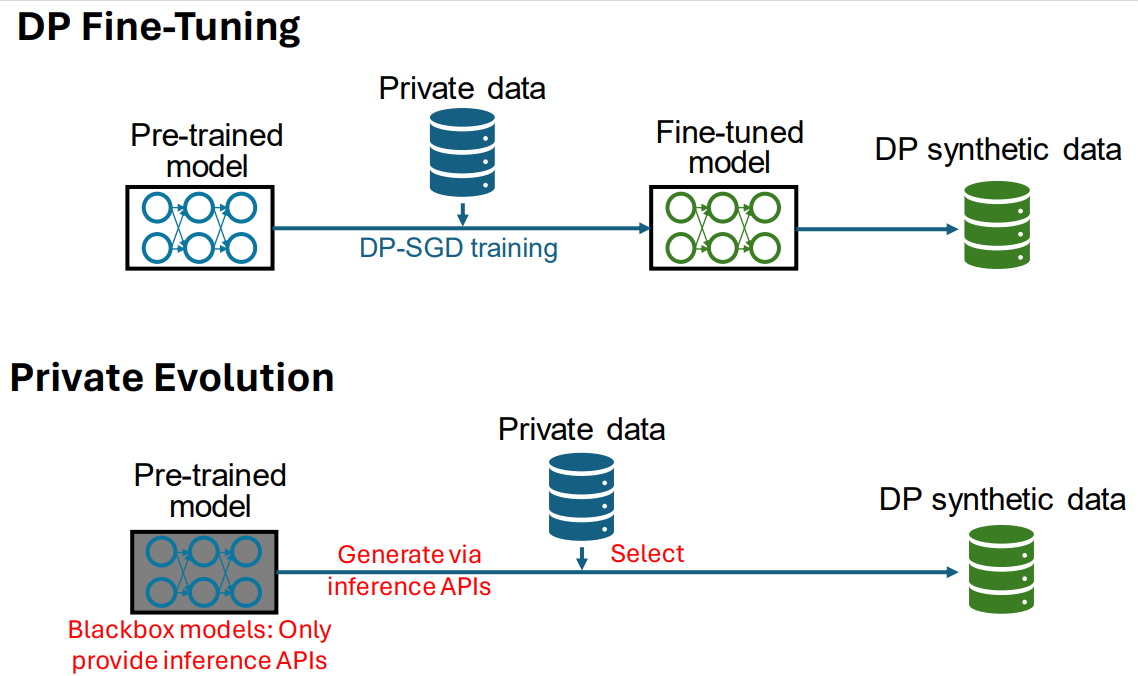
Synthetic image generation using foundation model APIs: In Differentially Private Synthetic Data via Foundation Model APIs 1: Images, the authors introduced Private Evolution (PE), an approach that enables DP image synthesis merely through inference APIs of a generative model. PE operates by sampling from a pre-trained diffusion model such as Stable Diffusion, which has no knowledge of the private corpus. PE then iteratively compares these samples to the private corpus, keeps the ones that are most similar to the private corpus, and uses the pre-trained model to generate more such samples. Crucially, the comparison to the private corpus is done with a DP guarantee, so that any information revealed about the private corpus is strictly bounded. Also, all the queries to the foundation model APIs satisfy the same DP guarantee, so that we can safely use APIs provided by (untrusted) third parties.
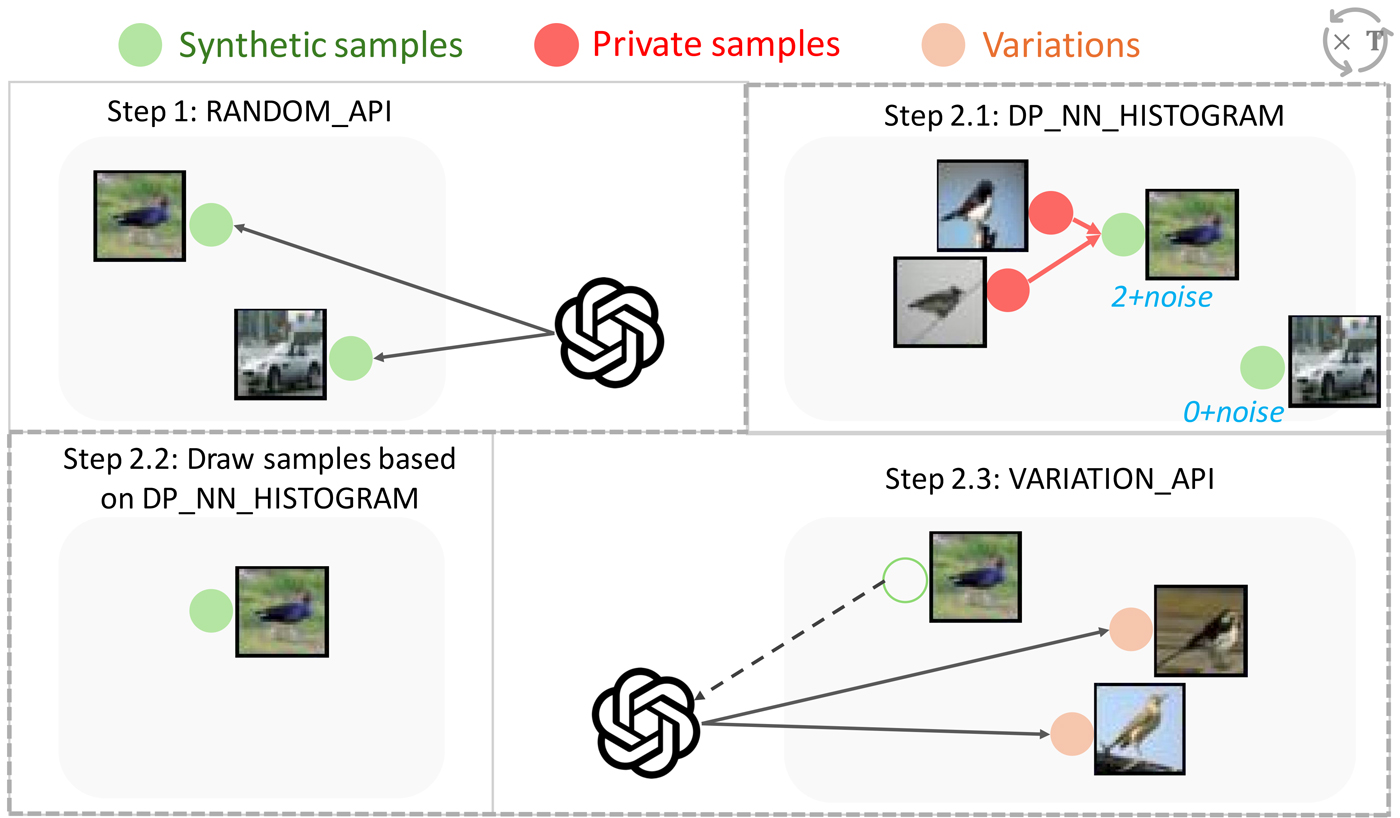
Even without doing any model training, PE significantly advances state-of-the-art results on some of the datasets. For example, on CIFAR10 dataset (opens in new tab), we achieve FID score (image quality measure, smaller is better) ≤ 7.9 with DP privacy cost ϵ = 0.67, significantly improving the previous SOTA from ϵ = 32. In the paper, we also show that PE requires less computational resource (GPU hours) than DP fine-tuning to achieve such results.
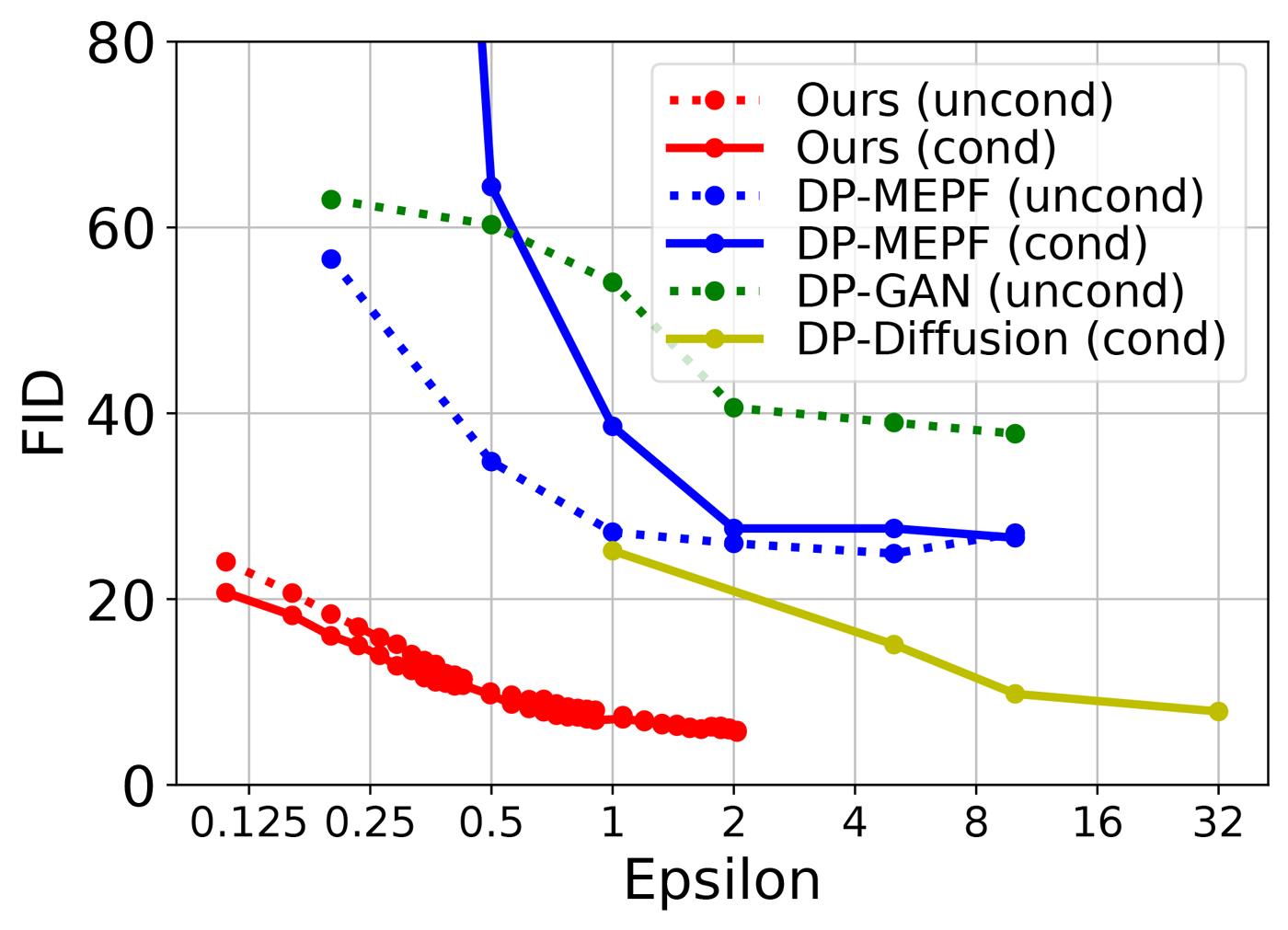

Synthetic Text Generation using foundation model APIs: the PE approach described above works well for images since it is easy to produce nearby perturbations of promising images. In Differentially Private Synthetic Data via Foundation Model APIs 2: Text, Microsoft researchers explored whether a similar approach could be applied to text. Their method, called Augmented Private Evolution (Aug-PE), operates similarly to the basic PE approach, but leverages the power of a pre-trained LLM to produce variations and re-wordings of input text. Aug-PE also proposes some fundamental algorithmic improvements that may benefit future development of PE.

Results show that Aug-PE is a promising alternative to DP-fine-tuning for DP text synthesis. With the same foundation model, PE can match or even beat DP-fine-tuning in terms of the trade-off between text quality and privacy. Moreover, as Aug-PE only requires inference APIs, Aug-PE can easily work with the most advanced LLMs such as GPT-3.5, LLaMA, and Mixtral to further improve the text quality. In terms of computational cost (GPU hours), PE can achieve up to 65.7x speedup compared to the DP fine-tuning approach.

Privacy-Preserving In-Context Learning with Differentially Private Few-Shot Generation
In-context learning is a technique for performing tasks with an LLM by providing a sample of demonstration examples in the prompt of the LLM before presenting it with a specific task. For example, we might show a few movie plots and their genre and ask the LLM to suggest the genre for a particular plot of interest. In-context learning harnesses the strong generalization capabilities of LLMs, but it requires a sample of labeled demonstration examples at inference time. How can we perform in-context learning when the only available labeled examples are private? A naïve solution might be to use the private examples but hide the demonstration prompt from the user. However, the threat posed by jailbreak attacks puts these examples at risk for exposure to a malicious user.
In Privacy-Preserving In-Context Learning with Differentially Private Few-Shot Generation, Microsoft researchers explored how demonstration examples can be synthesized from a private corpus with a privacy guarantee. The method operates by incrementally drawing samples from a token distribution defined by the private examples but with noise added to the distribution. The noise is calibrated to ensure a bound on the privacy lost with each sample. The research demonstrated that in-context learning can out-perform zero-shot learning (querying a model without any demonstration examples) and comes close to performing at the same level as the case with no privacy mitigations, as shown in Table 3.


Conclusion
Synthetic data generation presents enormous opportunities to develop AI systems without compromising end-user privacy. In this blog post, we have explored recent innovations in synthetic data generation with strong privacy guarantees. These approaches can enable practitioners to produce synthetic data from private entities, while mitigating the risk that private information might be revealed. While these approaches are highly promising, they do have limitations. For example, we are currently limited to producing relatively short text passages. Future work will continue to explore the opportunities presented by these approaches, with an aim to produce increasingly realistic data with strong privacy guarantees.
Acknowledgments: The authors are grateful for the contributions of the co-authors of the papers reviewed in this blog post: Xiang Yue, Xuechen Li, Girish Kumar, Julia McAnallen, Hoda Shajari, Huan Sun, David Levitan, Chulin Xie, Arturs Backurs, Sivakanth Gopi, Da Yu, Harsha Nori, Haotian Jiang, Huishuai Zhang, Yin Tat Lee, Bo Li, Janardhan Kulkarni, Xinyu Tang, Richard Shin, Andre Manoel, and Niloofar Mireshghallah.



