

Our work on Orca and Orca 2 demonstrated the power of using synthetic data for the post-training of small language models and getting them to levels of performance previously found only in much larger language models. Orca-AgentInstruct is another step in this direction, where we explore using agentic flows to generate diverse and high-quality data at scale. Orca-AgentInstruct is an agentic solution for synthetic-data generation. By leveraging an agentic framework, AgentInstruct can generate tailored datasets, comprising both prompts and responses, from raw data sources, paving the way to building a synthetic data factory for model fine-tuning.
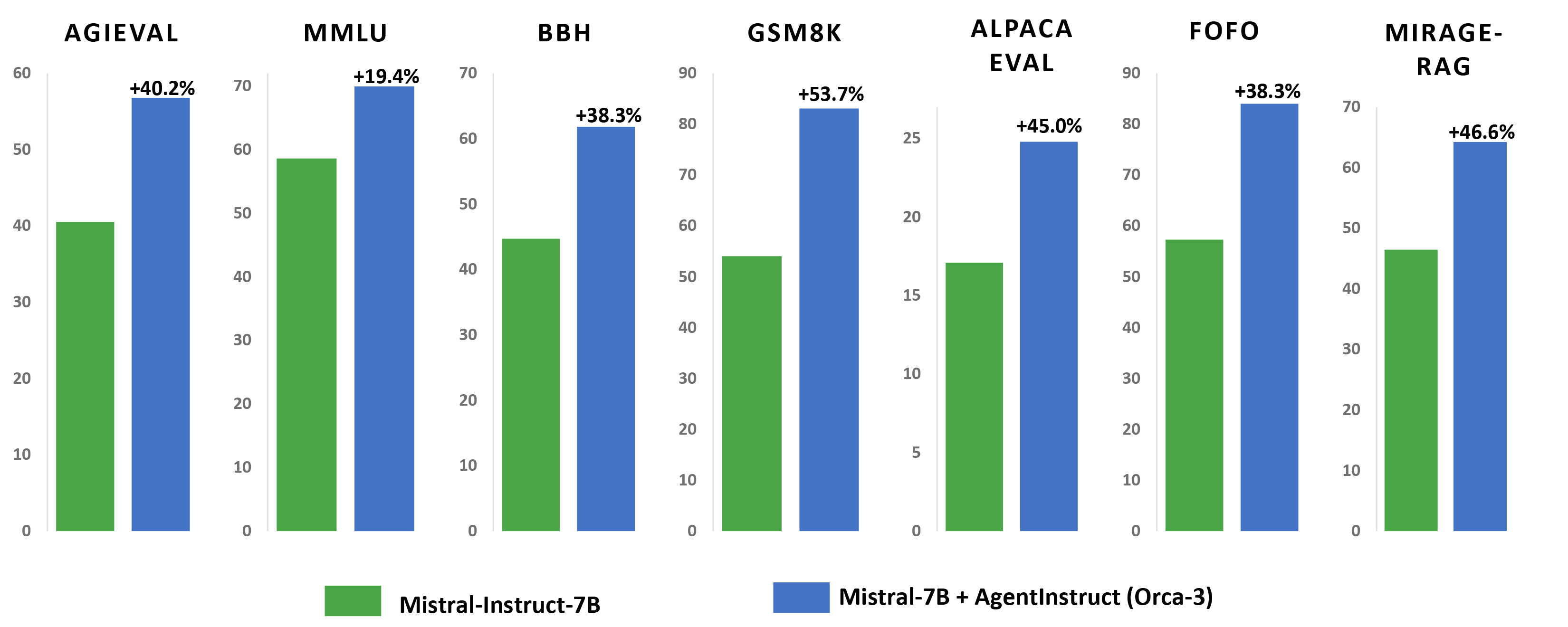
The efficacy of this approach is exemplified by the substantial improvement observed by fine-tuning a base Mistral 7-billion-parameter model and using AgentInstruct to generate a 25-million-pair dataset. The fine-tuned model (which we refer to as Orca-3-Mistral) showcases a notable performance gain across multiple benchmarks. For example, it shows 40% improvement on AGIEval, 19% improvement on MMLU, 54% improvement on GSM8K, 38% improvement on BBH, 45% improvement on AlpacaEval, and a 31.34% reduction of inaccurate or unreliable results across multiple summarization benchmarks.
We are making a 1-million-pair subset (orca-agentinstruct-1M) of this dataset publicly available, along with a report describing the data generation procedure, to encourage research on synthetic data generation and finetuning of language models.
Synthetic Data Accelerated LLM Development: Over the past year, using synthetic data has greatly advanced the training of large language models (LLMs). It sped up model training at all stages, from pre-training (e.g., Phi-3) to instruction-tuning (e.g., Orca and WizardLM) and reinforcement learning from human feedback (e.g., Direct Nash Optimization).
-
 Demo video
AgentInstruct Methodology
Demo video
AgentInstruct Methodology
Generating high-quality synthetic data is hard: On the other hand, research indicates that pre-training models on synthetic data produced by other models can result in model collapse, causing models to progressively degrade. Similar concerns have been raised regarding the use of synthetic data for post-training, suggesting that it might lead to an imitation process where the trained model learns only stylistic features rather than actual capabilities.
This discrepancy may be attributed to the challenge of generating high-quality and diverse synthetic data. Successful use of synthetic data involves significant human effort in curating and filtering the data to ensure high quality.
Synthetic data meets agents: Another major development we witnessed during the past year is the rise of agentic (especially multi-agent) workflows, such as with AutoGen. Agentic workflows can generate high-quality data, which surpasses the capabilities of the underlying LLMs, by using flows with reflection and iteration that enable agents to look back at solutions, generate critiques, and improve solutions. They can also use tools like search APIs, calculators, and code interpreters to address LLM limitations.
Multi-agent workflows bring in additional benefits as well, such as simulating scenarios where we can generate both new prompts and the corresponding responses. They also enable automation of data-generation workflows, reducing or eliminating the need for unnecessary human intervention on some tasks.
AgentInstruct: Generating synthetic data for post-training or finetuning often relies on an existing prompt set that is either used as is or as seeds for generating more instructions. In this work, we generalize the problem settings to a broader objective of generating an abundant amount of diverse, challenging, and high-quality data to teach a particular skill to an AI model. We refer to this setting as generative teaching.
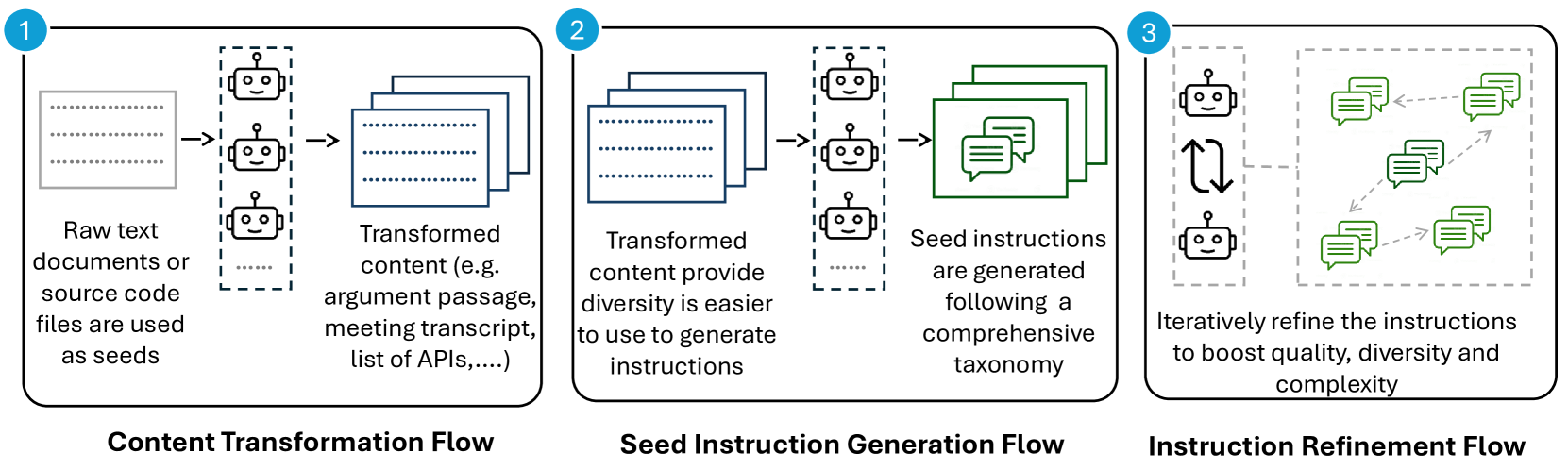
AgentInstruct is an agentic solution for generative teaching. AgentInstruct uses raw documents as input to create demonstration and feedback data. When generic data is used as seeds, AgentInstruct can be used to teach an LLM a general capability, such as writing, reasoning, or retrieval-augmented generation (RAG). Domain specific data, like retail or finance, can also be used as seeds to improve the model in a certain specialization. AgentInstruct can create:
- High-quality data: AgentInstruct uses GPT-4, coupled with tools like search and code interpreters, to create high-quality data.
- Diverse data: AgentInstruct creates prompts and responses using a set of specialized agents (with powerful LLMs, tools, and reflection flows) and a taxonomy (of more than 100 subcategories), , ensuring diversity and quality.
- Large quantities of data: AgentInstruct can run autonomously. and applyiflows for verification and data filtering. It does not require seed prompts and uses raw documents for seeding.
Using raw data as seeds offers two advantages: it is plentiful, allowing AgentInstruct to generate large-scale and diverse datasets, and it encourages learning general skills instead of benchmark-specific ones by avoiding using existing prompts.
Spotlight: Blog post

Research Focus: Week of September 9, 2024
Investigating vulnerabilities in LLMs; A novel total-duration-aware (TDA) duration model for text-to-speech (TTS); Generative expert metric system through iterative prompt priming; Integrity protection in 5G fronthaul networks.
We anticipate agentic flows becoming increasingly important throughout the model-training lifecycle, including pre-training, post-training, and specialization, and ultimately enabling the creation of a synthetic data factory for model customization and continuous improvement. This has the potential to drive AI advances across multiple industries by making high-quality model training more efficient and accessible.
Contributors:
Arindam Mitra, Luciano Del Corro, Guoqing Zheng, Shweti Mahajan, Dany Rouhana, Andres Codas, Yadong Lu, Wei-ge Chen, Olga Vrousgou, Corby Rosset, Fillipe Silva, Hamed Khanpour, Yash Lara, and Ahmed Awadallah



