Over the last decade, advances in machine learning coupled with the availability of large amounts of data have led to significant progress on long-standing AI challenges. In domains like computer vision, speech recognition, machine translation and image captioning, machines have reached and sometimes even exceeded human performance levels on specific problem sets. However, building end-to-end, multimodal interactive systems that bring together multiple AI technologies and interact with people in the open world remains an important challenge.
Challenges with Multimodal Interactive Systems
Consider a robot that can escort visitors from one location to another in a building, all the while interacting with them via natural language. Or consider a meeting room virtual assistant that tries to understand the dynamics of the human interactions and provide assistance on demand. These types of systems require assembling and coordinating a diverse set of AI technologies: localization and mapping, person detection and tracking, attention tracking, speech recognition, sound source localization, speech source and addressee detection, natural language processing, dialog management, natural language generation and more.
The sheer complexity of these systems creates significant engineering challenges that are further amplified by several unique attributes. These systems are highly multimodal; acting in the physical world requires that they process and fuse high density streams of data from multiple sensors. Multiple components need to process data in parallel, yet they also must be tightly coordinated to produce coherent internal states as well as timely results. Given the frequent use of machine learning and inference models, as well as interactivity needs, these systems often operate under uncertainty and under important latency constraints. Reasoning about time and uncertainty is therefore paramount. Unfortunately, these constructs are not yet core primitives in our programming languages and platforms.
Microsoft research podcast

Abstracts: August 15, 2024
Advanced AI may make it easier for bad actors to deceive others online. A multidisciplinary research team is exploring one solution: a credential that allows people to show they’re not bots without sharing identifying information. Shrey Jain and Zoë Hitzig explain.
Additional software engineering challenges arise in the realm of debugging and maintenance. Visualization tools for multimodal temporal data can be an important accelerator but also are largely missing. Interesting challenges also arise from the fact that these systems often couple human-authored deterministic components with multiple machine learning models that often are chained. We know a lot about how to solve individual inference problems via machine learning but not so much about how to resolve the software engineering and maintenance problems arising from integrating multiple such models in end-to-end systems.

At Microsoft Research, as part of the Situated Interaction (opens in new tab) research effort and in other robotics research teams, we have developed a host of physically situated, multimodal interactive systems, from robots that give directions, to embodied personal assistants, to elevators that recognize intentions to board versus walk by. In the process, we have experienced firsthand the challenges with building physically situated, multimodal interactive systems, and we have learned a number of important lessons. Given these challenges and the overhead involved, interesting research problems often are out of reach and remain unaddressed.
We believe that the right set of primitives and tools can significantly lower the barrier to entry for developing multimodal interactive systems and enable more researchers to tackle problems that only become evident when an end-to-end system is present and deployed in the real world. Over the last several years we’ve embarked on constructing a platform to help address these problems and we are now happy to announce the initial beta, open-source release of this framework, called Platform for Situated Intelligence (opens in new tab).
Platform for Situated Intelligence
Platform for Situated Intelligence is an open-source, extensible framework intended to enable the rapid development, fielding and study of situated, integrative AI systems.
The term situated refers to the fact that the framework primarily targets systems that sense and act in the physical world. This includes a broad class of applications, including various cyberphysical systems such as interactive robots, drones, embodied conversational agents, personal assistants, interactive instrumented meeting rooms, software systems that mesh human and machine intelligence and so on. Generally, any system that operates over streaming data and has low-latency constraints is a good candidate. The term integrative AI refers to the fact that the platform primarily targets systems that combine multiple, heterogeneous AI technologies and components.
The platform provides an infrastructure, a set of tools and an ecosystem of reusable components that aim to mitigate some of the challenges that arise in the development of these systems. The primary goal is to speed up and simplify the development, debugging, analysis, maintenance and continuous evolution of integrative systems by empowering developer-in-the-loop scenarios and rapid iteration.
The platform also aims to enable fundamental research and exploration into the science of integrative AI systems. Currently, these systems are typically constructed as a tapestry of heterogeneous technologies, which precludes studying and optimizing of the system as a whole. There are a number of interesting problems and opportunities in the space of integrative AI, which are very difficult to explore in real systems designed using current technologies. Platform for Situated Intelligence aims to provide the underlying set of abstractions that will enable meta-reasoning (or system-level reasoning) and foster research into this nascent science of integrative systems.
Finally, Platform for Situated Intelligence is open and extensible. We have released it (opens in new tab) as open-source because success ultimately depends on engaging the community and enabling contributions at all levels of the framework by creating a thriving ecosystem of reusable AI components.
The following sections present a brief introduction to each of the three major areas of the framework:
- the runtime provides a programming and execution model for parallel, coordinated computation
- a set of tools and APIs that enable visualization, data processing and machine learning scenarios
- an open ecosystem of components that encapsulate a variety of AI technologies
Runtime
The runtime provides a programming and execution model for parallel, coordinated computation based on time-aware data streams. The runtime is implemented on the .NET framework and aims to simplify authoring of complex applications and components while maintaining the performance characteristics of carefully tuned native code.
Applications are written by connecting components via streams of data. A typical application usually leverages several categories of components, including sensor components such as cameras and microphones act as stream producers, processing components such as speech recognizers and face trackers process the incoming data, and effector components ultimately control output and action in the world. The connections between components are realized via streams of data that are strongly typed and time aware.
The runtime provides a number of primitives and facilities that directly target and simplify the development of multimodal, integrative AI systems: time-aware data streams, scheduling and synchronization, isolated execution, automatic cloning and persistence, data replay and remoting. Many additional features are also in the works. While each of these topics deserves its own detailed writeup, in this initial blog post we simply highlight some of the main features.
Time-aware data streams – Components in a Platform for Situated Intelligence application are connected via strongly typed data streams. More importantly, time is a core construct in the runtime. The messages flowing through the streams are time stamped at origin with an originating time that is carried downstream through the application pipeline. Consider, for instance, a simple pipeline that performs face tracking: video frames are captured by a camera component and sent to a component that converts the images to grayscale and then to a tracking component that produces face tracking results. The video frames emitted by a camera component are time stamped with an originating time that corresponds to the moment the frame was captured. As the image is passed along to a grayscale component and to the face tracker, the same originating time is carried along with the resulting messages. In addition, each message carries the time when it was created. This mechanism gives all components in the pipeline access to information about latencies with respect to the real world for all messages. Furthermore, these timestamps enable efficient scheduling as well as correct and reproducible synchronization.
Time-based synchronization – Time and synchronization are paramount in any multimodal application working with streaming data. The temporal nature of the streams enables a time-algebra and set of synchronization primitives that simplify development. As a concrete example, suppose we want to correlate the face tracking results from the pipeline described above with sound source localization information to determine which one of multiple people present in front of a robot is talking. Because the speech source identification component has access to the originating times of the messages on both incoming streams, it can pair and synchronize them, according to when the events actually happened in the world (rather than according to when they arrived at the component). The runtime provides a stream join operator that enables reproducible synchronization, freeing up the developer from having to think through the intricacies of temporal reasoning. Other time-related primitives, like sampling and interpolation, are also available.
Time-based scheduling – The temporal nature of streams also enables efficient scheduling. The runtime implements a scheduler that controls the execution of the various components in the pipeline by paying attention to the originating times of the messages arriving at the components and giving priority to the oldest ones (that is, those with the earliest originating times). The developer has control over how messages flow through the streams via delivery policies that specify where and when it is OK to drop messages or that can describe throttling behaviors.
Isolated execution – Multimodal, integrative-AI applications generally involve a large array of components that need to execute in a concurrent yet coordinated manner. The programming model implemented by the runtime allows for developing components as if they were single-threaded. At runtime, it couples them via a streaming message-passing system that allows for concurrent execution of components while providing isolation and protecting state. This approach is made possible by an automatic deep cloning subsystem and frees the component developer from having to think through the intricacies of concurrent execution, simplifying development efforts.
Persistence and data replay – The development of multimodal, integrative AI systems is often data-driven. Typically, an initial prototype is constructed and deployed and components are iteratively refined and tuned based on the data collected with the running system. Data and experimentation play a central role in this process. The runtime enables automatic persistence of the data flowing through the streams. The persistence mechanism is optimized for throughput and allows a developer to log in a unified manner all relevant data flowing through the application. Furthermore, because timing information is also persisted, data can be replayed from a store in a variety of ways, enabling experimentation scenarios. For instance, in the example described above, once the video and audio streams were captured, the developer can easily re-run the application opening these streams from a store rather than from the sensors, enabling the exploration of how tuning various parameters in the downstream components (face tracking, sound source localization and so on) might change the final results. APIs and mechanisms for coupling multiple stores in larger datasets and operating over entire datasets are also available.
Remoting – Oftentimes, multimodal, multi-sensor applications need to run distributed across multiple machines. The runtime enables parallel, coordinated computation in a single process or in a distributed fashion across multiple processes.
Tools
In addition to the set of primitives and the core programming and execution model provided by the runtime, a number of specialized tools and APIs are available, further enabling and supporting the development process.
Visualization – Given the complexity and number of components involved, the temporal nature of the data streams and the highly parallel nature of execution, data visualization is critical to accelerating the development, debugging and tuning of multimodal, integrative-AI applications. The framework includes a sophisticated visualization tool for temporal, multimodal data: Platform for Situated Intelligence.
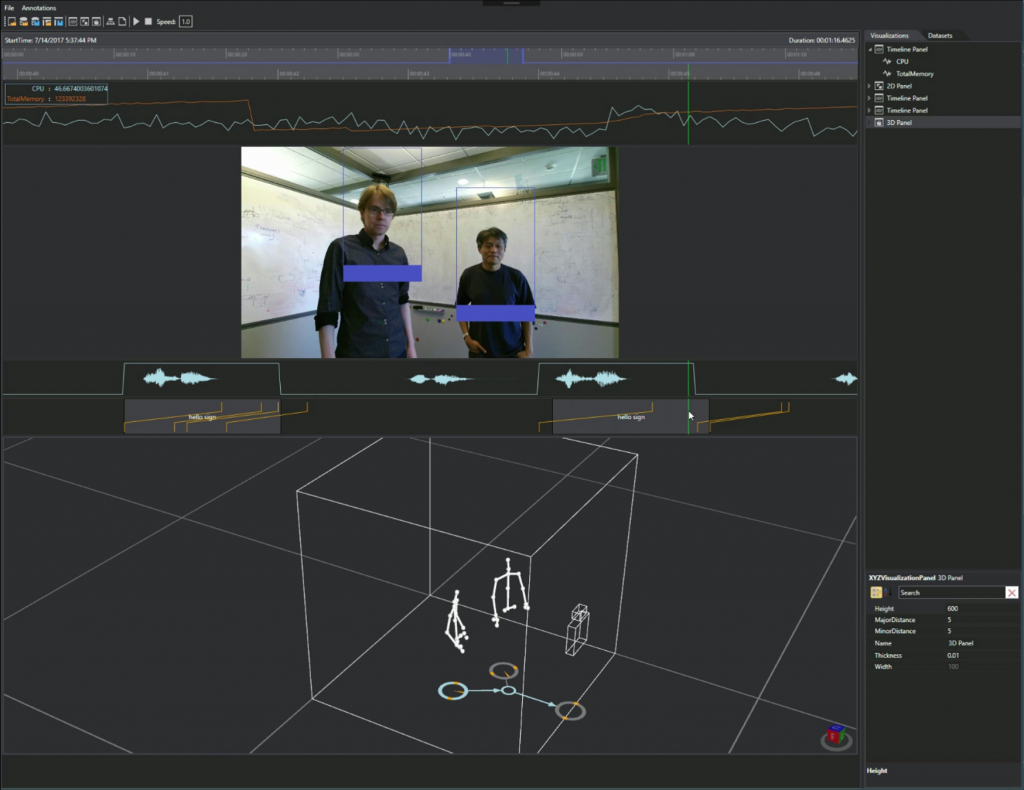
The tool allows for inspecting and visualizing the various streams persisted by a Platform for Situated Intelligence application. Multiple visualizers are available: timeline visualizers show various types of data over time (for example, numerical, audio, speech recognition results and so on); 2D and 3D instant visualizers can show the data corresponding to a certain time-point (for example, images from a video stream). The visualizers can be composited and overlaid in a variety of ways; for instance, the second panel in the video above shows an image stream visualizer overlaid with a visualizer for face tracking results. The tool enables temporal navigation (with panning and zooming over time) as well as working with datasets that encompass stores persisted from multiple runs of a system. It enables both offline and live visualization; in live-mode, the tool can be invoked from or can connect to a running Platform for Situated Intelligence application and enables visualization of the live streams flowing through the application.
Data processing – Data-driven experimentation plays a central role in the development and tuning of multimodal, integrative AI applications. Supported by the data replay abilities in the runtime, APIs are provided that enable developers to define datasets that wrap the data obtained from multiple runs of an application and process and analyze this data offline, generating relevant statistics, or running batch experiments. Data import/export is another important area we plan to provide additional tools for.
Machine learning – Finally, we plan to soon include a set of APIs and tools that aim to simplify and accelerate the end-to-end machine learning development loop in the context of multimodal interactive systems and temporally streaming data. The tools and APIs will include support for creating and manipulating datasets based on data logged by applications written using the platform, data annotation capabilities that are tightly integrated with visualization, support for feature engineering and development, integration for training with various ML frameworks and services, in-app evaluation and model deployment.
Components
Ultimately, we believe lowering the barrier to entry for development of multimodal, integrative AI applications will rest to a large degree on creating an open, extensible, thriving ecosystem of reusable components. Researchers should be able to easily componentize the various technologies they develop and find and easily reuse each other’s work.
In this initial, beta release of Platform for Situated Intelligence we are providing a set of components that facilitate multimodal interactive scenarios by enabling capture and processing of audio-visual data. We have included a number of sensor components for typical USB cameras and microphones. In the audio domain we have included components for basic acoustic feature extraction and for voice-activity detection. Components for speech recognition and language understanding are also provided, including wrappers around three different speech recognition systems – the windows desktop System.Speech recognizer, the Microsoft Speech SDK and the Bing Speech API – as well as the Language Understanding (LUIS) service provided by Microsoft’s Cognitive Services. In the imaging domain we have provided capabilities for basic image processing and components for making use of Microsoft’s Cognitive Services Face and Vision APIs. Finally, we also are providing tools to enable the easy construction of finite state machine controllers that can be helpful when prototyping interactives systems. In addition, a couple of example projects illustrate how to bridge to other ecosystems, like OpenCV and ROS.
For discoverability and ease of use, we also are releasing these components in the form of NuGet packages. These packages are easy to use on Windows and Linux platforms and can be found on http://www.nuget.org (opens in new tab), by searching for Microsoft.Psi.
Next Steps
We have made Platform for Situated Intelligence available as an open-source project at an early stage. In the near future, our roadmap includes further evolving the runtime by extending the time algebra and the set of primitives for synchronization, interpolation and sampling and by focusing more attention on the debugging experience. We plan to continue to extend the visualization capabilities and enable the visualization subsystem to run not only on Windows but also on Linux, like the rest of the framework. We plan to further enhance the data processing APIs and release the machine learning tools and APIs over the next few months. Finally, in terms of component ecosystem, we intend to improve and extend the current set of available components and develop and release an interaction toolkit that will provide representations and a set of configurable components geared towards physically situated language interaction, including reasoning from multiple sensors about people, groups, attention, conversational engagement, turn-taking and so on.
Various aspects of the platform are at different levels of completion and robustness. There are still probably bugs in the code and we will likely be making breaking API changes. We intend to engage the community early and incorporate feedback and contributions. We plan to listen closely and continuously improve the framework based on the feedback we receive and foster an ecosystem of components. We believe the runtime, tools, and component ecosystem will in the long run significantly lower the barrier to entry for developing multimodal interactive systems and will act as a basis for research and exploration in the nascent science of integrative-AI systems.
Acknowledgements
Many people have been involved in and have contributed to Platform for Situated Intelligence, from envisioning and guidance, to development, support, testing and feedback. We would like to thank Sean Andrist, John Elliott, Ashley Feniello, Don Gillett, Eric Horvitz, Mihai Jalobeanu, Anne Loomis-Thompson, Nick Saw and Patrick Sweeney for their contributions. We also thank our internal and external early adopters for the feedback they have provided.