
A team of researchers from the Natural Language Processing (NLP) Group at Microsoft Research Asia (MSRA) and the Speech Dialog Research Group at Microsoft Redmond are currently leading in the Conversational Question Answering (CoQA) Challenge organized by Stanford University. In this challenge, machines are measured by their ability to understand a text passage and answer a series of interconnected questions that appear in a conversation. Microsoft is currently the only team to have reached human parity in its model performance.
CoQA is a large-scale conversational question-answering dataset that is made up of conversational questions on a set of articles from different domains. The MSRA NLP team previously reached the human parity milestone on single-round question answering using the Stanford Question Answering Dataset (SQuAD). Compared with SQuAD, the questions in CoQA are more conversational and the answers can be free-form text to ensure the naturalness of answers in a conversation.
The questions in CoQA are very short, to mimic human conversation. In addition, every question after the first is dependent on the conversational history, which makes the short questions even more difficult for machines to parse. For example, suppose you asked a system, “Who is the founder of Microsoft?” You need it to understand that you were still speaking on the same subject when you ask the follow-up question, “When was he born?”


About Microsoft Research
Advancing science and technology to benefit humanity
A Conversation from the CoQA Dataset. CoQA Paper: https://arxiv.org/abs/1808.07042
To better test the generalization ability of existing models, CoQA collected data from seven different domains: children’s stories, literature, middle and high school English exams, news, Wikipedia, Reddit, and science. The first five are used in the training, development, and test sets, and the last two are used only for the test set. CoQA uses the F1 metric to evaluate performance. The F1 metric measures the average word overlap between the prediction and ground truth answers. In-domain F1 is scored on test data from the same domain as the training set; and out-of-domain F1 is scored on test data from different domains. Overall F1 is the final score on the whole test set.
The method used by the Microsoft researchers employs a special strategy, in which information learned from several related tasks is used to improve the target machine reading comprehension (MRC) tasks. In this multistage, multitask, fine-tuning method, researchers first learn MRC-relevant background information from related tasks under a multitask setting, and then fine-tune the model on the target task. Language modeling is additionally used as an auxiliary task in both stages to help reduce the over-fitting of the conversational question-answering model. Experiments have supported the effectiveness of this method, which is further demonstrated by its strong performance in the CoQA Challenge.
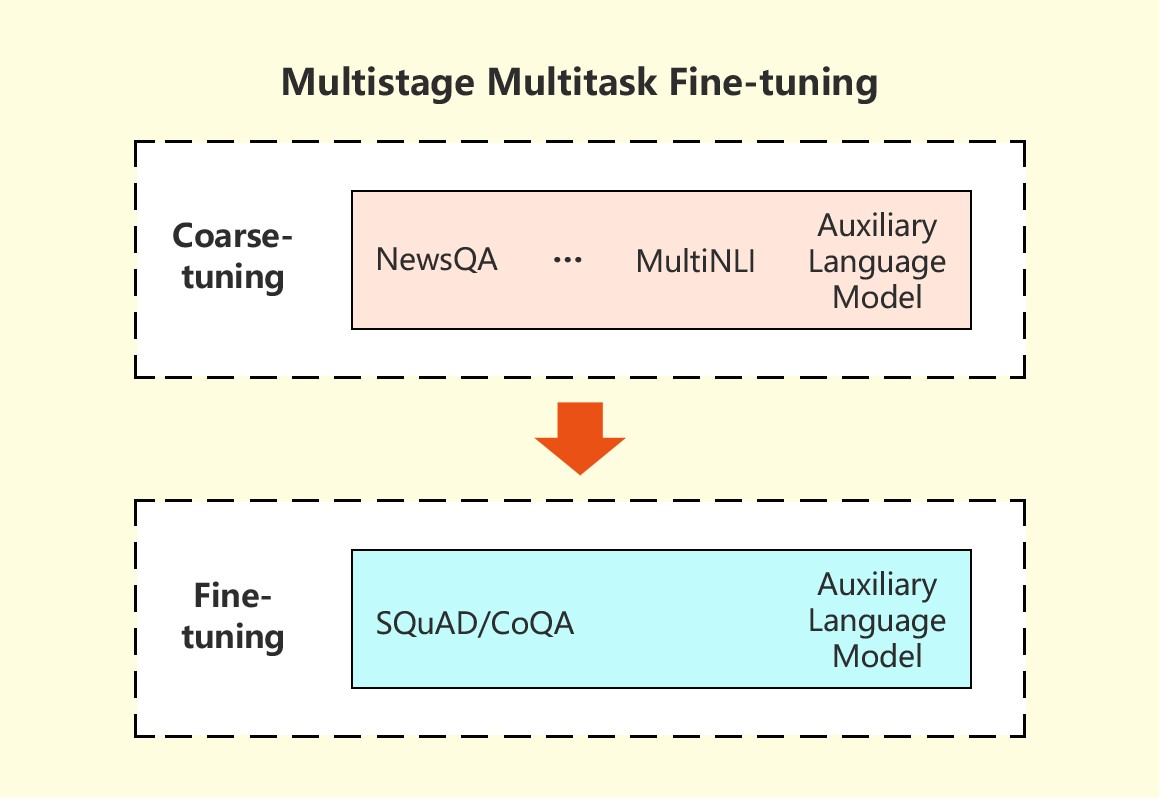
Overview of the multistage multitask fine-tuning model
According to the CoQA leaderboard, the ensemble system that Microsoft researchers submitted on March 29, 2019 reached 89.9/88.0/89.4 as its respective in-domain, out-of-domain, and overall F1 scores. Human performance on the same set of conversational questions and answers stands at 89.4/87.4/88.8.
This achievement marks a major advance in the effort to have search engines such as Bing and intelligent assistants such as Cortana interact with people and provide information in more natural ways, much like how people communicate with each other. Nonetheless, general machine reading comprehension and question answering remains an unsolved problem in natural language processing. To further push the boundary of machine capability in understanding and generating natural language, the team continues to work on producing even more powerful pre-training models.



