Today, we published an exploration of the power of prompting strategies that demonstrates how the generalist GPT-4 model can perform as a specialist on medical challenge problem benchmarks. The study shows GPT-4’s ability to outperform a leading model that was fine-tuned specifically for medical applications, on the same benchmarks and by a significant margin. These results are among other recent studies that show how prompting strategies alone can be effective in evoking this kind of domain-specific expertise from generalist foundation models.
During early evaluations of the capabilities of GPT-4, we were excited to see glimmers of general problem-solving skills, with surprising polymathic capabilities of abstraction, generalization, and composition—including the ability to weave together concepts across disciplines. Beyond these general reasoning powers, we discovered that GPT-4 could be steered via prompting to serve as a domain-specific specialist in numerous areas. Previously, eliciting these capabilities required fine-tuning the language models with specially curated data to achieve top performance in specific domains. This poses the question of whether more extensive training of generalist foundation models might reduce the need for fine-tuning.
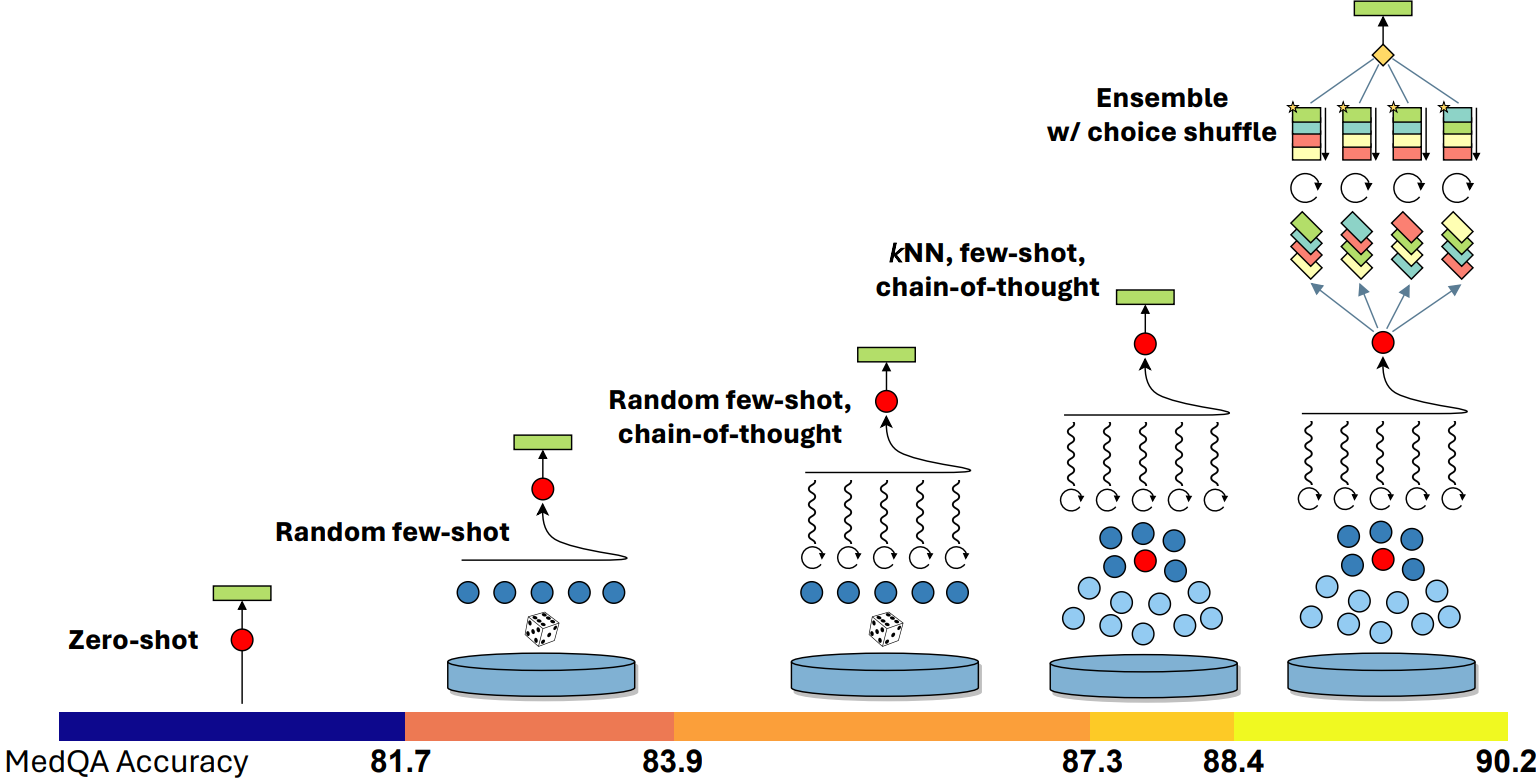
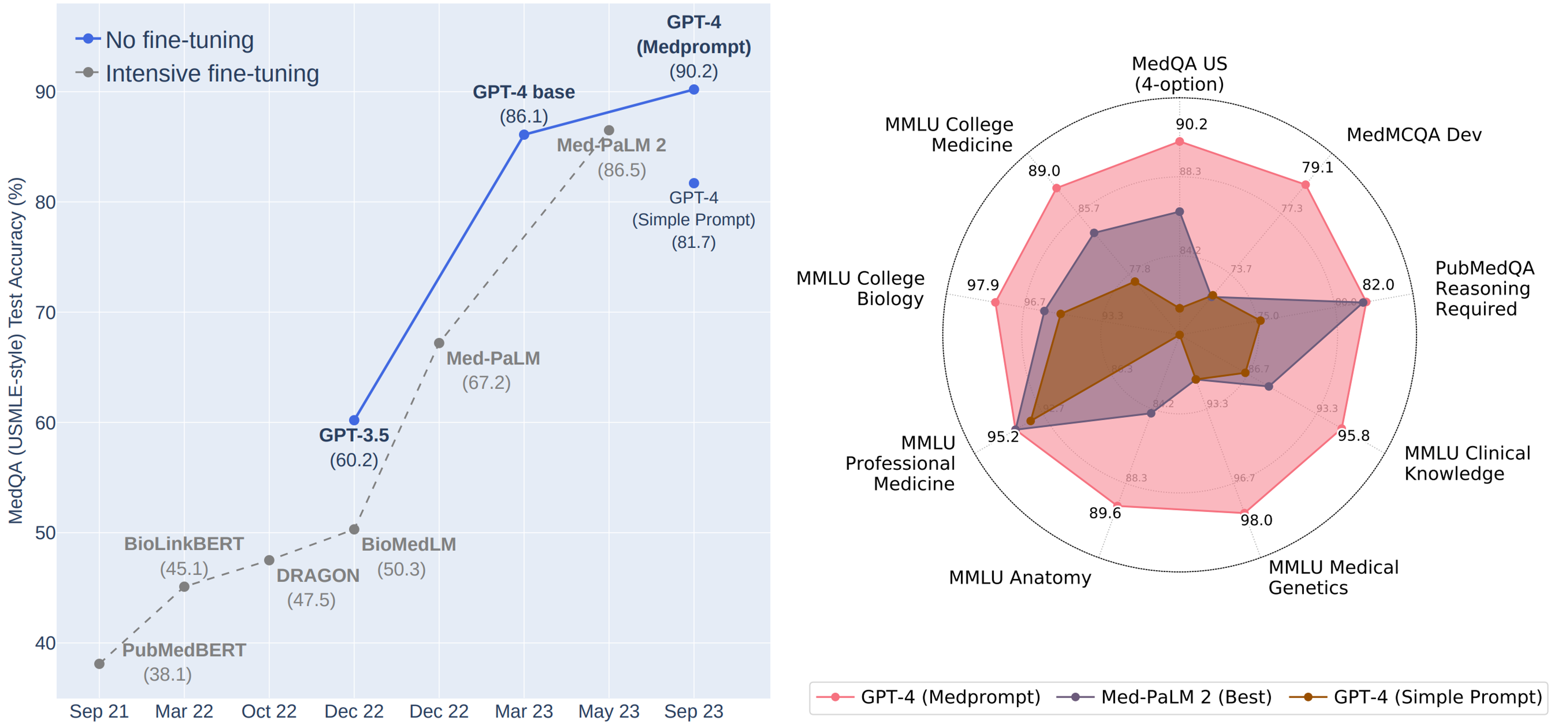
In a study shared in March, we demonstrated how very simple prompting strategies revealed GPT-4’s strengths in medical knowledge without special fine-tuning. The results showed how the “out-of-the-box” model could ace a battery of medical challenge problems with basic prompts. In our more recent study, we show how the composition of several prompting strategies into a method that we refer to as “Medprompt” can efficiently steer GPT-4 to achieve top performance. In particular, we find that GPT-4 with Medprompt:
- Surpasses 90% on MedQA dataset for the first time
- Achieves top reported results on all nine benchmark datasets in the MultiMedQA suite
- Reduces error rate on MedQA by 27% over that reported by MedPaLM 2
Spotlight: Blog post

MedFuzz: Exploring the robustness of LLMs on medical challenge problems
Medfuzz tests LLMs by breaking benchmark assumptions, exposing vulnerabilities to bolster real-world accuracy.
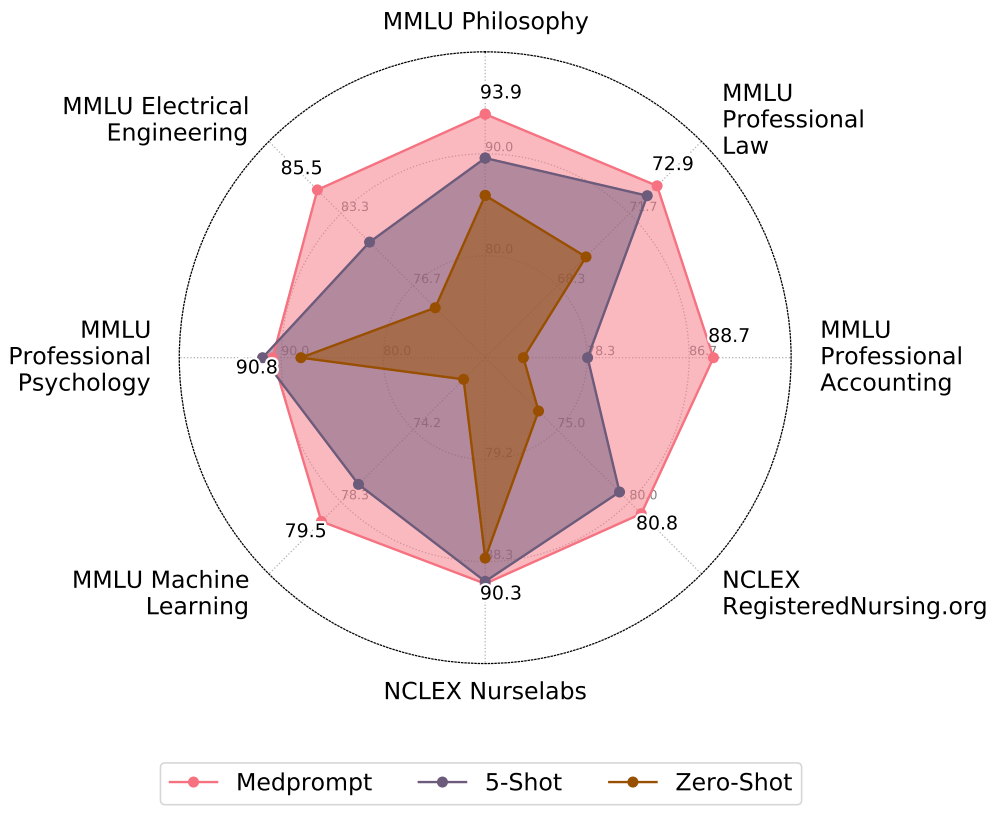
Many AI practitioners assume that specialty-centric fine-tuning is required to extend generalist foundation models to perform well on specific domains. While fine-tuning can boost performance, the process can be expensive. Fine-tuning often requires experts or professionally labeled datasets (e.g., via top clinicians in the MedPaLM project) and then computing model parameter updates. The process can be resource-intensive and cost-prohibitive, making the approach a difficult challenge for many small and medium-sized organizations. The Medprompt study shows the value of more deeply exploring prompting possibilities for transforming generalist models into specialists and extending the benefits of these models to new domains and applications. In an intriguing finding, the prompting methods we present appear to be valuable, without any domain-specific updates to the prompting strategy, across professional competency exams in a diversity of domains, including electrical engineering, machine learning, philosophy, accounting, law, and psychology.
At Microsoft, we’ve been working on the best ways to harness the latest advances in large language models across our products and services while keeping a careful focus on understanding and addressing potential issues with the reliability, safety, and usability of applications. It’s been inspirational to see all the creativity, and the careful integration and testing of prototypes, as we continue the journey to share new AI developments with our partners and customers.