As researchers continue to apply machine learning to more complex real-world problems, they’ll need to rely less on algorithms that require annotation. This is not only because labels are expensive, but also because supervised learners trained only to predict annotations tend not to generalize beyond structure in the data necessary for the given task. For instance, a neural network trained to classify images tends to do so based on texture (opens in new tab) that correlates with the class label rather than with shape or size, which may limit the suitability of the classifier in test settings. This issue, among others, is a core motivation for unsupervised learning of good representations.
Learning good representations without relying on annotations has been a long-standing challenge in machine learning. Our approach, which we call Deep InfoMax (DIM) (opens in new tab), does so by learning a predictive model of localized features of a deep neural network. The work is presented at the 2019 International Conference on Learning Representations (ICLR) (opens in new tab).
DIM (code on GitHub (opens in new tab)) is based on two learning principles: mutual information maximization in the vein of the infomax optimization principle and self-supervision, an important unsupervised learning method that relies on intrinsic properties of the data to provide its own annotation. DIM is flexible, simple to implement, and incorporates a task we call self-prediction.
Mutual information estimation: Does this pair belong together?
Microsoft research podcast

Collaborators: Silica in space with Richard Black and Dexter Greene
College freshman Dexter Greene and Microsoft research manager Richard Black discuss how technology that stores data in glass is supporting students as they expand earlier efforts to communicate what it means to be human to extraterrestrials.
DIM draws inspiration from the infomax principle, a guideline for learning good representations by maximizing the mutual information between the input and output of a neural network. In this setting, the mutual information is defined as the KL-divergence between the joint distribution—all inputs paired with the corresponding outputs—and product-of-marginals distribution—all possible input/output pairs. While intuitive, infomax has had limited success with deep networks, partially because estimating mutual information is difficult in settings where the input is high-dimensional and/or the representation is continuous.
The recently introduced Mutual Information Neural Estimator (MINE) (opens in new tab) trains a neural network to maximize a lower bound to the mutual information. MINE works by training a discriminator network between samples from the joint distribution, also known as positive samples, and samples from the product-of-marginals distribution, also known as negative samples. For a neural network encoder, the discriminator in MINE is tasked with answering the following question: Does this pair—the input and the output representation—belong together?
DIM borrows this idea from MINE to learn representations using the gradients from a discriminator to help train the encoder network. This is similar to learning for the generator in generative adversarial networks (GANs), except the encoder is making this task easier for the discriminator, not harder. In addition, we don’t rely on the KL-based discriminator from MINE, as this works less effectively in practice than discriminators that use the Jensen-Shannon divergence (JSD) or infoNCE, an estimator used by Contrastive Predictive Coding (CPC) (opens in new tab).
Learning shared information
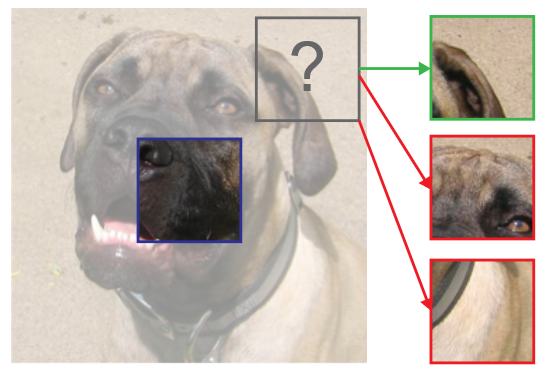
Unfortunately, training an encoder to only maximize the mutual information between the input and output will yield representations that contain trivial or “noisy” information from the input. For example, in the cat picture below, there are many locations, or patches, from which a neural network could extract information that would increase the mutual information during optimization.

(opens in new tab) An image contains both relevant information and irrelevant information, or noise. In many cases, the noise can represent a larger “quantity” of information.
But there is only a subset of locations we’re actually interested in. Worse still, maximizing mutual information between the whole image input and the output representation, which we refer to as global DIM in the paper, will be biased toward learning features that are unrelated, as their sum has more unique information than redundant locations. For example, the ear, eye, and fur all indicate information about the same thing—“a cat”—so encoding all of these locations won’t increase the mutual information as much as encoding the foliage in the background.
So pure mutual information maximization isn’t exactly what we want. We want to maximize information that is shared across the input—in this case, across relevant locations. To accomplish this, we maximize the mutual information between a global summary feature vector, which coincides with the full image, and feature vectors corresponding to local patches. This is a self-supervision task analogous to training the encoder to predict local patch features from a global summary feature; we call this local DIM, but for simplicity, we’ll refer to this approach as “DIM” below.
(opens in new tab) In a sample self-supervision task, the model selects the best patch conditioned on the center patch for a particular location given a set of candidates. Generally, in tasks like these, the conditioned and predicted features correspond to different locations (autoregression). DIM differs in that the conditioned feature is a function of all predicted features, which both simplifies implementation and improves results. The researchers refer to that task as self-prediction.
Predicting the local given the whole
DIM is not unlike other self-supervision approaches that learn to predict local patches across an image at the feature level. Other works learn a representation of images by asking the encoder to pick the correct patch for a given location from among a set of candidates (opens in new tab) and conditioned on another patch—for example, conditioned on the center patch (opens in new tab)—with the task performed completely in the representation space. In natural language processing, methods like Quick Thoughts (opens in new tab) use similar types of self-supervision to learn good sentence representations. However, these approaches are purely autoregressive: They all involve tasks where the conditioning and predicted features correspond to different locations in the input. In DIM, the conditioning global feature can be a function of all the local features being predicted, a task we call self-prediction, but DIM is also flexible enough to incorporate autoregression.
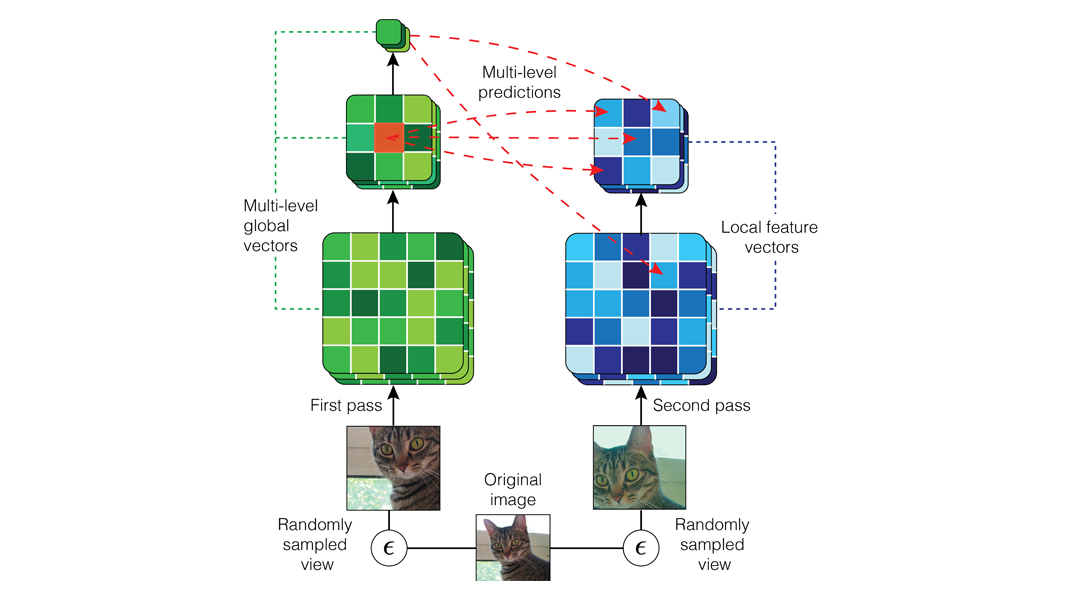
(opens in new tab) Learning representations by maximizing mutual information between a global summary feature and local features in a convolutional neural network. First, local features are computed by a forward pass, followed by a summarization into a global summary feature vector. DIM then maximizes the mutual information between the global summary feature vector and all local features simultaneously.
The base encoder architecture for DIM with images is very simple, requiring only a small modification on top of a convolutional neural network. First, a standard ConvNet yields a set of localized feature vectors. These local features are summarized using a standard neural network such as a combination of convolutional and fully connected layers. The output of this is the global summary feature vector, which we use to maximize the mutual information with all local feature vectors.
To estimate and maximize the mutual information, one can use a variety of neural architectures as small additions to the encoder architecture. One that worked well for us was a deep bilinear model in which both the local and global feature vectors were fed into separate fully connected networks with the same output size, followed by a dot product between the two for the score. This score was then fed into either JSD, infoNCE, or the KL-based estimator in MINE.
We evaluated DIM, along with various other unsupervised models, by training a small nonlinear classifier on top of the local representations on the CIFAR-10, CIFAR-100, Tiny ImageNet, and STL-10 datasets. DIM outperformed all methods we tested and proved comparable to supervised learning. We also explored other ways to measure the “goodness” of the representation, such as independence of the global variables and the ability to reconstruct, with results and analyses available in the paper.
| Model | Cifar10 | Cifar100 | Tiny Imagenet | STL10 |
| Fully supervised | 75.39 | 42.27 | 36.60 | 68.7 |
| VAE | 60.71 | 37.21 | 18.63 | 58.27 |
| AAE | 59.44 | 36.22 | 18.04 | 59.54 |
| BiGAN | 62.57 | 37.59 | 24.38 | 71.53 |
| NAT | 56.19 | 29.18 | 13.70 | 64.32 |
| DIM (KL) | 72.66 | 48.52 | 30.53 | 69.15 |
| DIM (JSD) | 73.25 | 48.13 | 33.54 | 72.86 |
| DIM (infoNCE) | 75.21 | 49.74 | 34.21 | 72.57 |
Above are classification accuracies using a single-layer neural network as a nonlinear classifier on top of the local feature vectors for evaluation on CIFAR-10, CIFAR-100, Tiny ImageNet, and STL-10. The representations for DIM outperform representations from the other unsupervised methods when their representations are evaluated in this way.
Incorporating autoregression
While DIM favors self-prediction over the type of autoregression commonly found in self-supervision models like CPC, DIM is flexible and can be easily modified to incorporate some autoregression, which can ultimately improve the representation.


The figure on the left shows the type of autoregressive semi-supervised task commonly used in Contrastive Predictive Coding (CPC), where the predictor and predicted features come from different locations. The figure on the right shows DIM with a mixed self-prediction and autoregressive task. DIM uses the global summary feature vector as a predictor for both the occluded and unoccluded locations.
This can be done by computing the global vector with part of the input occluded. The local features are then computed using the complete original input. This is a type of orderless autoregression (opens in new tab) that allows us to make the task slightly harder for DIM and potentially improve results. Alternatively, we can perform mixed self-prediction and orderless autoregression by computing multiple global vectors using a simple convolutional layer on top of the local features.

(opens in new tab) With DIM, you can perform mixed self-prediction and orderless autoregression by computing multiple global vectors using a simple convolutional layer on top of the local features.
We compared DIM with single and multiple global vectors—that is, without and with orderless autoregression—to CPC (ordered autoregression) on classification tasks using ResNet architectures and strided crops as used in CPC. DIM and CPC performed comparably despite the much simpler and faster task of DIM. This indicates the strict ordered autoregression in CPC may not be necessary for these types of representation learning tasks on images.
| Model | Cifar10 | STL10 |
| DIM (single global) | 80.95 | 76.97 |
| CPC | 77.45 | 77.81 |
| DIM (multiple globals) | 77.51 | 78.21 |
Above is the classification evaluation on CIFAR-10 and STL-10 for DIM with a ResNet architecture with single and multiple global feature vectors compared to Contrastive Predictive Coding (CPC). DIM and CPC performed comparably despite the much simpler and faster task of DIM.
Overall, the ideas behind DIM are simple and can be easily extended to other domains. They’ve already been extended—with impressive results—to learning unsupervised representations of graphs (opens in new tab) and brain imaging data (opens in new tab). We’re optimistic this is only the beginning for how DIM can help researchers advance machine learning by providing a more effective way to learn good representations.