
机器翻译
什么是机器翻译?
机器翻译系统是使用机器学习技术从其支持的语言中翻译大量文本的应用程序或在线服务。服务将 "源" 文本从一种语言转换为不同的 "目标" 语言。
虽然机器翻译技术背后的概念和使用它的接口相对简单, 但它背后的科学和技术是极其复杂的, 并汇集了一些前沿技术, 特别是深入学习 (人工智能)、大数据、语言学、云计算和 web api。
自二十一世纪十年代代初以来, 一种新的人工智能技术, 深神经网络 (又称深度学习), 使得语音识别技术达到了质量水平, 使得 Microsoft 翻译团队能够将语音识别与核心文本翻译技术推出了一种新的语音翻译技术。
从历史上看, 该行业使用的主要机器学习技术是统计机器翻译 (SMT)。SMT 采用先进的统计分析方法, 根据几句话的语境, 估计出一个词的最佳可能译文。自 mid-2000s 以来, SMT 已被所有主要的翻译服务提供商 (包括微软) 使用。
神经机器翻译 (NMT) 的出现, 使翻译技术发生了根本性的转变, 从而导致了更高的质量翻译。此翻译技术开始为用户和开发人员部署在 2016年下半年.
SMT 和 NMT 翻译技术都有两个共同点:
- 两者都需要大量的前人类翻译内容 (多达数以百万计的翻译句子) 来训练系统。
- 既不作为双语词典, 根据可能的翻译列表翻译单词, 但根据句子中使用的单词的上下文进行翻译。
什么是Translator?
笔译和语音服务,属于 认知服务 api 的集合, 是来自 Microsoft 的机器翻译服务。
文本翻译
自2007年以来,微软集团一直在使用Translator,自2011年以来,它作为一个API提供给客户。Translator在微软内部得到了广泛的使用。它被纳入产品本地化、支持和在线交流团队。同样的服务也可以从熟悉的微软产品中获得,不需要额外费用,例如 必应, 柯塔娜, 微软边缘, 办公室, Sharepoint, Skype,以及 Yammer.
翻译器可以在任何硬件平台上的Web或客户端应用程序中使用,并与任何操作系统配合使用,以执行语言翻译和其他语言相关的操作,如语言检测、文本转语音或词典等。
利用行业标准 REST 技术, 开发人员将源文本 (或语音转换的音频) 发送给服务, 并带有一个指示目标语言的参数, 并且该服务会将转换后的文本发送回客户端或 web 应用程序以使用。
Translator 服务是托管在 Microsoft 数据中心的 Azure 服务,并从其他 Microsoft 云服务的安全性、可扩展性、可靠性和不间断的可用性中获益。
语音翻译
Translator语音翻译技术从2014年底开始与Skype Translator一起推出,并从2016年初开始作为开放的API供客户使用。它被集成到微软翻译器直播功能、Skype、Skype会议广播以及Android和iOS的微软翻译器应用中。
语音转换现在可通过 Microsoft 语音 (语音识别、语音转换和语音合成 (文本到语音) 的端到端集提供。
文本翻译是如何工作的?
文本翻译主要有两种技术: 遗留一项、统计机器翻译 (SMT) 和新的世代一、神经机器翻译 (NMT)。
统计机器翻译
Translator的统计机器翻译(SMT)的实现是建立在微软公司十多年的自然语言研究的基础上。现代翻译系统不是编写手工制作的规则来进行语言间的翻译,而是将翻译作为一个从现有的人类翻译中学习语言间文本转换的问题,并利用应用统计学和机器学习方面的最新进展。
所谓的 "并行语料库 "就像现代的罗塞塔石,为许多语言对和领域提供了单词、短语和成语的上下文翻译。统计建模技术和高效的算法帮助计算机解决了破译(检测训练数据中源语言和目标语言之间的对应关系)和解码(寻找新输入句子的最佳翻译)的问题。Translator将统计学方法的力量与语言信息结合在一起,产生的模型能够更好地归纳出更多的语言信息,并导致更易理解的翻译。
由于这种方法不依赖于字典或语法规则, 它提供了短语的最佳翻译, 它可以使用给定单词周围的上下文, 而不是尝试执行单个单词翻译。对于单词翻译, 双语词典是开发的, 可以通过 www.bing.com/translator.
神经机器翻译
持续改进翻译工作非常重要。然而,自2010年代中期以来,SMT技术的性能改进已经趋于平缓。通过利用微软的AI超级计算机的规模和能力,特别是微软认知工具包,Translator现在提供了神经网络(LSTM) 为基础的翻译, 使翻译质量的新十年得以改进。
这些神经网络模型可通过Azure上的Speech服务,以及通过使用 "generalnn "类别ID的文本API,为所有语音语言提供这些神经网络模型。
与传统的 SMT 相比, 神经网络翻译在如何执行上有着根本性的差异。
下面的动画描述了神经网络翻译所经过的各种步骤来翻译句子。由于这种方法, 翻译将考虑到整个句子的上下文, 而不是只有几个字滑动窗口, SMT 技术使用, 将产生更多的流体和人翻译的前瞻性翻译。
在神经网络训练的基础上, 每个单词都按照一个500维向量 (a) 进行编码, 它代表了特定语言对 (如英语和汉语) 中的独特特性。基于用于训练的语言对, 神经网络将自我定义这些维度应该是什么。他们可以编码简单的概念, 如性别 (女性, 男性, 中性), 礼貌水平 (俚语, 休闲, 书面, 正式, 等等), 类型的词 (动词, 名词等), 但也任何其他不明显的特点, 从训练数据派生。
神经网络翻译的步骤如下:
- 每个词, 或者更具体地说, 代表它的500维向量, 通过第一层的 "神经元", 它将在一个1000维向量 (b) 中编码, 在句子中的其他单词的上下文中表示这个词。
- 一旦所有单词都被编码成这些1000维向量, 这个过程就重复了几次, 每个层允许更好地微调这个词在完整句子上下文中的这个1000维表示 (与 SMT 相反)。技术, 只能考虑到3到5字窗口)
- 最后的输出矩阵然后使用的注意层 (即软件算法), 将使用这最后的输出矩阵和以前翻译的词的输出, 以定义哪个词, 从源句, 应该翻译下。它还将使用这些计算来潜在地丢弃目标语言中不必要的单词。
- 解码器 (平移) 层, 将所选单词 (或更具体地说是在完整句子的上下文中表示这个词的1000维向量) 以其最合适的目标语言等价。最后一层 (c) 的输出随后被反馈到注意层中, 以计算从源语句中的下一个单词应该被翻译。

在动画中描述的示例中, 上下文感知的1000维模型 "的"将编码的名词 (房子) 是法语中的一个女性词 (la 故居).这将允许适当的翻译为 "的"是"洛杉矶"而不是"乐"(单数, 男性) 或"莱斯"(复数) 一旦它到达解码器 (翻译) 层。
注意算法也将根据先前翻译的单词 (在本例中) 计算。的"), 下一个要翻译的词应该是主题 ("房子"), 而不是一个形容词 ("蓝色").在可以做到这一点, 因为系统了解到, 英语和法语颠倒的顺序, 这些单词的句子。它也会计算, 如果形容词是 "大"而不是颜色, 它不应该反转他们 ("大房子"=="格兰德故居").
多亏了这种方法, 在大多数情况下, 最终输出比基于 SMT 的翻译更流畅, 更接近人类翻译。
语音翻译是如何工作的?
Translator还可以进行语音翻译。这项技术在Translator的实时功能中被曝光了(http://translate.it), 翻译应用程序, skype 翻译, 并最初是提供仅通过 Skype 翻译功能和在微软翻译应用程序的 iOS 和 Android, 这一功能现在可以向开发人员提供最新版本的开放Azure 门户上可用的基于 REST 的 API。
虽然从现有的技术砖块中构建语音翻译技术似乎是一个直接的向前过程, 但它需要的工作要比简单地插入现有的 "传统" 人机语音识别要多得多。引擎到现有的文本翻译一。
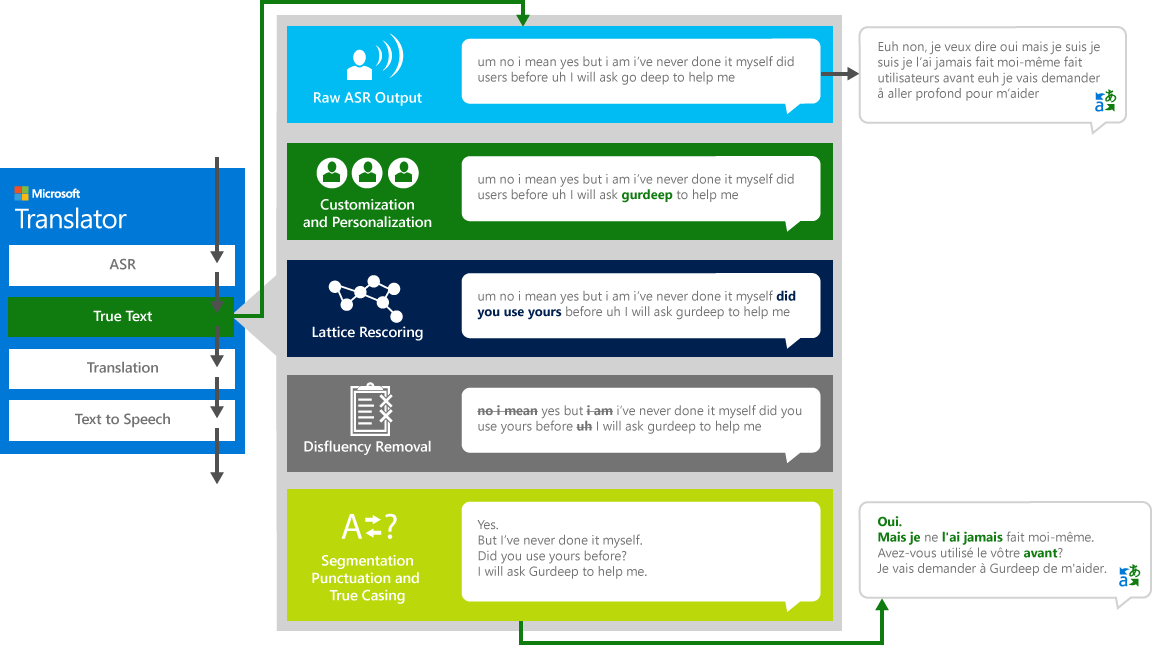
为了正确地将 "源" 语音从一种语言转换为不同的 "目标" 语言, 系统将进行四步过程。
- 语音识别, 将音频转换为文本
- TrueText: 一种将文本规范化以使其更适合翻译的 Microsoft 技术
- 翻译通过上面描述的文本翻译引擎, 但关于特别开发的翻译模型为真实生活口语谈话
- 文本到语音, 必要时, 产生翻译的音频。

自动语音识别 (ASR)
自动语音识别 (ASR) 是使用一个神经网络 (NN) 系统进行训练, 分析成千上万小时的传入音频语音。这个模型是通过人与人之间的交互而不是人与机器的命令进行训练的, 它产生了为正常对话而优化的语音识别。为了实现这一目标, 需要更多的数据以及比传统的人对机 ASRs 更大的 DNN。
了解更多关于 微软对文字服务的演讲.
TrueText
当人类与其他人交谈时, 我们不会像我们经常认为的那样完美、清晰或整齐地说话。使用 TrueText 技术, 文本转换为更密切地反映用户意图通过删除语音 disfluencies (填充字), 如 "um", "ah" s, "和" s, "像" s, 结巴和重复。通过添加句子分隔符、正确的标点和大写, 也可以使文本更易于阅读和翻译。为了达到这些结果, 我们用了数十年的语言技术工作, 我们从翻译公司发展到创建 TrueText。下面的关系图通过一个真实的示例描述了各种转换 TrueText 操作以规范化此文本。
翻译
然后将文本转换为任何 语言和方言 由Translator支持。
使用语音翻译 API (作为开发人员) 或语音翻译应用程序或服务中的翻译是以最新的基于神经网络的翻译为基础的, 用于所有语音输入支持的语言 (请参见 这里 完整列表)。这些模型还通过扩展当前的, 主要是书面文本训练的翻译模型来建立, 用更多的口语语料库构建一个更好的口语会话类型的翻译模式。这些模型也可通过 "语音" 标准类别 传统的文本翻译 API。
对于任何不受神经翻译支持的语言, 都执行传统的 SMT 翻译。
文本到语音
如果目标语言是18支持的文本到语音的一种 语言, 并且用例需要音频输出, 然后使用语音合成将文本转换为语音输出。在语音到文本翻译方案中省略此阶段。
了解更多关于 微软的文本到语音服务.