
使用 Microsoft 翻译器将 AI 转换为边缘设备
2016年11月, microsoft 将 ai 驱动的机器翻译 (即神经机器翻译 (nmt)) 的优势带给了开发人员和最终用户。上个星期 微软将 nmt 功能带到了云的边缘 通过利用 npu, 集成到 玛特10, 华为最新的旗舰手机。新芯片使 ai 供电的翻译即使在没有互联网接入的情况下也能在设备上使用, 使系统能够产生质量与在线系统相当的翻译。
为了实现这一突破, 微软和华为的研究人员和工程师合作, 使神经翻译适应了这一新的计算环境。
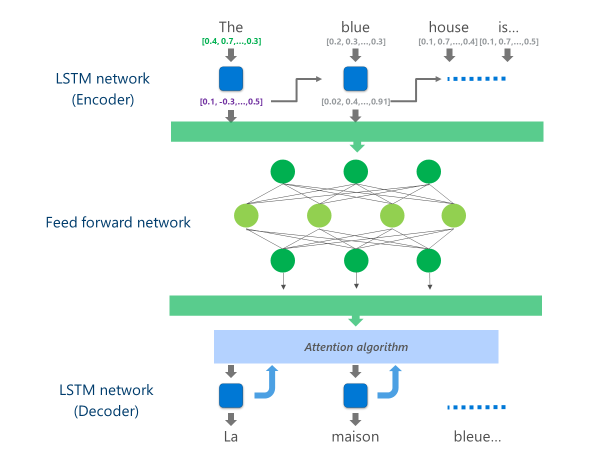
目前正在生产的最先进的 nmt 系统 (即企业和应用在云中大规模使用) 正在使用神经网络体系结构, 该体系结构结合了多层 lstm 网络, 注意算法, 和转换 (解码器) 层。
下面的动画以简化的方式解释了这种多层神经网络是如何工作的。欲了解更多详情, 请参阅 "什么是机器翻译页"在微软翻译网站上。

在此云 nmt 实现中, 这些中间 lstm 层消耗了很大一部分计算能力。为了能够在移动设备上运行完整的 nmt, 有必要找到一种机制, 在尽可能保持翻译质量的同时, 降低这些计算成本。
这就是华为神经处理单元 (npu) 发挥作用的地方。 microsoft 研究人员和工程师利用 npu (专门设计用于低延迟 ai 计算) 来卸载在主 cpu 上处理速度会非常慢的操作。
实现
现在, 华为配合10的微软翻译应用程序上提供的实现通过将计算最密集的任务卸载到 npu 来优化翻译。
具体来说, 此实现将这些中间 lstm 网络层替换为深 f向前神经网络.深前馈神经网络功能强大, 但由于神经元之间的高连通性, 需要大量的计算。
神经网络主要依赖于矩阵乘法, 从数学角度来看, 这种运算并不复杂, 但在以这种深层神经网络所需的比例执行时成本非常高。华为 npu 擅长以大规模并行的方式执行这些矩阵乘法。从电力利用率的角度来看, 它也是相当有效的, 这是电池供电设备的重要质量。
在这个前馈网络的每一层, npu 计算原始神经元输出和后续 复路激活功能 效率和非常低的延迟。通过利用 npu 上丰富的高速内存, 它可以并行执行这些计算, 而无需支付 cpu 和 npu 之间的数据传输成本 (即性能降低)。
一旦计算出这种深前馈网络的最后一层, 系统就具有丰富的源语言句子表示形式。然后通过从左到右的 lstm "解码器" 输入此表示, 以生成每个目标语言单词, 其注意算法与 nmt 在线版本中使用的算法相同。
作为 安东尼·奥, 微软翻译团队的首席软件开发工程师解释说: "将在数据中心强大的云服务器上运行的系统并在移动电话上保持不变是一个可行的选择。移动设备在计算能力、内存和功耗方面存在云解决方案所不具备的限制。通过访问 npu 以及其他一些架构调整, 我们可以解决其中的许多限制, 并设计一个能够在设备上快速高效地运行的系统, 而不必影响翻译质量."

这些翻译模型在创新的 npu 芯片组上的实施使微软和华为能够以与基于云的系统相当的质量提供设备上的神经翻译, 即使您不在网格之外。