
Masina de traducere
Ce este traducerea mașinii?
Sistemele de traducere automată sunt aplicații sau servicii online care utilizează tehnologii de învățare automată pentru a traduce cantități mari de text din și către oricare dintre limbile acceptate. Serviciul traduce un text "sursă" dintr-o limbă într-o altă limbă "țintă".
Deși conceptele din spatele tehnologiei de traducere automată și interfețelor de utilizat sunt relativ simple, știința și tehnologiile din spatele acesteia sunt extrem de complexe și aduc împreună mai multe tehnologii de vârf, în special învățarea profundă ( inteligență artificială), date mari, lingvistică, cloud computing și API-uri web.
De la începutul anului 2010s, o nouă tehnologie de inteligență artificială, rețele neuronale profunde (alias învățare profundă), a permis tehnologia recunoașterii vorbirii pentru a ajunge la un nivel de calitate care a permis echipei Microsoft Translator să combine recunoașterea vorbirii cu tehnologia de traducere a textului de bază pentru a lansa o nouă tehnologie de traducere a vorbirii.
Din punct de vedere istoric, tehnica principală de învățare a mașinii utilizată în industrie a fost statistica mașinii de traducere (SMT). SMT utilizează o analiză statistică avansată pentru a estima cele mai bune traduceri posibile pentru un cuvânt dat fiind contextul câtorva cuvinte. SMT a fost folosit de la mijlocul anilor 2000 de către toți furnizorii de servicii de traducere majore, inclusiv Microsoft.
Apariția de neuronale Machine traducere (NMT) a cauzat o schimbare radicală în tehnologia de traducere, rezultând în traduceri mult mai mare calitate. Această tehnologie de traducere a început implementarea pentru utilizatori și dezvoltatori în Ultima parte din 2016.
Ambele tehnologii de traducere SMT și NMT au două elemente în comun:
- Ambele necesită cantități mari de pre-umane tradus conținut (până la milioane de fraze traduse) pentru a instrui sistemele.
- Nici nu acționează ca dicționare bilingvă, Traducerea cuvintelor bazate pe o listă de traduceri potențiale, dar traduce în funcție de contextul cuvântului care este folosit într-o propoziție.
Ce este Translator?
Servicii de traducător și vorbire, parte a Servicii cognitive colecție de API-uri, sunt servicii de traducere automată de la Microsoft.
Traducere text
Translatorul este utilizat de grupurile Microsoft din 2007 și este disponibil ca API pentru clienți din 2011. Translator este utilizat pe scară largă în cadrul Microsoft. Este încorporat în echipele de localizare a produselor, suport și comunicare online. Același serviciu este, de asemenea, accesibil, fără costuri suplimentare, din cadrul produselor Microsoft familiare, cum ar fi Bing, Cortana, Microsoft Edge, Office, Sharepoint, Skypeși Yammer.
Translatorul poate fi utilizat în aplicații web sau client pe orice platformă hardware și cu orice sistem de operare pentru a efectua traducerea limbii și alte operațiuni legate de limbă, ar fi detectarea limbii, text în vorbire sau dicționar.
Leveraging industrie standard REST tehnologie, dezvoltatorul trimite text sursă (sau audio pentru traducerea vorbirii) la serviciu cu un parametru care indică limba țintă, iar serviciul trimite înapoi textul tradus pentru clientul sau aplicația web pentru a utiliza.
Serviciul Translator este un serviciu Azure găzduit în centrele de date Microsoft și beneficiază de securitatea, scalabilitatea, fiabilitatea și disponibilitatea non-stop pe care alte servicii cloud Microsoft, de asemenea, primesc.
Traducerea vorbirii
Tehnologia de traducere a vorbirii translator a fost lansată la sfârșitul anului 2014 începând cu Skype Translator și este disponibilă ca API deschis pentru clienți de la începutul anului 2016. Acesta este integrat în caracteristica Microsoft Translator live, Skype, difuzarea întâlnirii Skype și aplicațiile Microsoft Translator pentru Android și iOS.
Traducerea vorbirii este acum disponibilă prin Microsoft Speech, un set end-to-end de servicii complet personalizabile pentru recunoașterea vorbirii, traducerea vorbirii și sinteza vorbirii (text redat prin vorbire).
funcționează Traducerea textului?
Există două tehnologii principale utilizate pentru traducerea textului: o moștenire, statistică Machine traducere (SMT), și o generație mai nouă, neuronale Machine traducere (NMT).
Traduceri de mașini statistice
Implementarea traducerii mașinii statistice (SMT) de la Translator se bazează pe mai mult de un deceniu de cercetare în limbaj natural la Microsoft. În loc să scrie reguli artizanale pentru a traduce între limbi, sistemele moderne de traducere abordează traducerea ca pe o problemă de învățare a transformării textului între limbi din traducerile umane existente și valorificarea progreselor recente în statisticile aplicate și învățarea automată.
Așa-numita "corpora paralelă" acționează ca o piatră rosetta modernă în proporții masive, oferind cuvinte, fraze și traduceri idiomatice în contextul multor perechi de limbi și domenii. Tehnicile de modelare statistică și algoritmii eficienți ajută computerul să rezolve problema descifrarii (detectarea corespondențelor dintre limba sursă și cea țintă în datele de instruire) și decodarea (găsirea celei mai bune traduceri a unei noi propoziții de intrare). Traducătorul unește puterea metodelor statistice cu informațiile lingvistice pentru a produce modele care generalizează mai bine și conduc la traduceri mai ușor de înțeles.
Din cauza acestei abordări, care nu se bazează pe dicționare sau reguli gramaticale, acesta oferă cele mai bune traduceri de fraze în cazul în care se poate utiliza contextul în jurul unui anumit cuvânt versus încercarea de a efectua traduceri singur cuvânt. Pentru traducerile cu cuvinte simple, dicționarul bilingv a fost dezvoltat și este accesibil prin www.Bing.com/Translator.
Traducere neuronală a mașinii
Îmbunătățirile continue ale traducerii sunt importante. Cu toate acestea, îmbunătățirile de performanță au scăzut cu tehnologia SMT de la mijlocul anilor 2010. Prin valorificarea scară și puterea de Supercomputer Microsoft AI, în special Microsoft Cognitive Toolkit, Translator oferă acum rețea neuronale (LSTM) pe bază de traducere care permite un nou deceniu de îmbunătățire a calității de traducere.
Aceste modele de rețea neuronale sunt disponibile pentru toate limbile de vorbire prin serviciul de vorbire pe Azure și prin API-ul text utilizând ID-ul categoriei "generalnn".
Traduceri neuronale de rețea diferă în mod fundamental în modul în care acestea sunt efectuate în comparație cu cele tradiționale SMT.
Următoarea animație descrie diferitele etape de traduceri neuronale de rețea trece prin a traduce o propoziție. Din cauza acestei abordări, traducerea va lua în context sentința completă, față de doar câteva cuvinte alunecare fereastră care tehnologia SMT utilizează și va produce mai fluid și tradus de oameni în căutarea traducerilor.
Pe baza formării rețelei neuronale, fiecare cuvânt este codificat de-a lungul unui vector de 500 de dimensiuni (a) reprezentând caracteristicile sale unice într-o anumită pereche de limbi (de exemplu, engleză și chineză). Pe baza perechilor lingvistice utilizate pentru formare, rețeaua neuronală se va auto-defini ce ar trebui să fie aceste dimensiuni. Ei ar putea codifica concepte simple, ar fi sexul (feminin, masculin, neutru), nivel de politetea (argou, casual, scris, formal, etc), tip de cuvânt (verb, substantiv, etc), dar, de asemenea, orice alte caracteristici non-evidente ca derivate din datele de formare.
Pașii de rețea neuronale traduceri trece prin sunt următoarele:
- Fiecare cuvânt, sau mai precis de 500-vector dimensiune reprezentând aceasta, trece printr-un prim strat de "neuroni", care va codifica într-o 1000-dimensiune vector (b) reprezentând cuvântul în contextul de alte cuvinte în teză.
- Odată ce toate cuvintele au fost codificate o singură dată în aceste 1000-dimensiune vectori, procesul se repetă de mai multe ori, fiecare strat care să permită o mai bună reglaj fin al acestui 1000-dimensiune reprezentare a cuvântului în contextul pedepsei integrale (contrar SMT tehnologie care poate lua în considerare doar o fereastră de 3-5 cuvinte)
- Matricea finală de ieșire este apoi utilizată de stratul de atenție (adică un algoritm software) care va utiliza atât matricea de ieșire finală, cât și ieșirea de cuvinte traduse anterior pentru a defini ce cuvânt, de la fraza sursă, ar trebui să fie tradus în continuare. Acesta va utiliza, de asemenea, aceste calcule pentru a scădea potențial cuvinte inutile în limba țintă.
- Stratul de decodor (traducere), traduce cuvântul selectat (sau mai precis vectorul de dimensiune 1000 care reprezintă acest cuvânt în contextul propoziției integrale) în echivalentul cel mai adecvat al limbii țintă. Rezultatul acestui ultim strat (c) este apoi alimentat înapoi în stratul de atenție pentru a calcula care următorul cuvânt din fraza sursă ar trebui să fie tradus.

În exemplul descris în animație, contextul-conștient 1000-model de dimensiune a "la"va codifica că substantivul (Casa) este un cuvânt feminin în limba franceză (la Maison). Acest lucru va permite traducerea corespunzătoare pentru "la"a fi"La"și nu"le"(singular, masculin) sau"Les"(plural) odată ce ajunge la stratul de decodor (traducere).
Algoritmul de atentie va calcula, de asemenea, pe baza cuvântului (lor) tradus anterior (în acest caz "la"), că următorul cuvânt care urmează să fie tradus ar trebui să fie subiect ("Casa") și nu un adjectiv ("Albastru"). În poate realiza acest lucru, deoarece sistemul a învățat că limba engleză și franceză invertit ordinea acestor cuvinte în fraze. S-ar fi calculat, de asemenea, că, dacă adjectivul ar fi "Mare"în loc de o culoare, că nu ar trebui să le invertit ("casa mare"= >"la Grande Maison").
Datorită acestei abordări, rezultatul final este, în majoritatea cazurilor, mai fluent și mai aproape de o traducere umană decât o traducere bazată pe SMT ar fi putut fi vreodată.
funcționează Traducerea vorbirii?
Translatorul este, de asemenea, capabil să traducă vorbirea. Această tehnologie este expusă în caracteristica Live Translator (http://translate.it), aplicațiile Translator, Skype Translator și este, de asemenea, inițial puse la dispoziție numai prin caracteristica Skype Translator și în aplicațiile Microsoft Translator pe iOS și Android, această funcționalitate este acum disponibil pentru dezvoltatori cu cea mai recentă versiune a deschis API pe bază de repaus disponibil pe portalul Azure.
Deși poate părea ca un proces direct înainte, la o primă vedere pentru a construi o tehnologie de traducere discurs de la cărămizi existente tehnologie, este necesar mult mai mult de lucru decât pur și simplu conectarea unui existente "tradiționale" de recunoaștere a vorbirii umane la mașină motorului la traducerea textului existent.
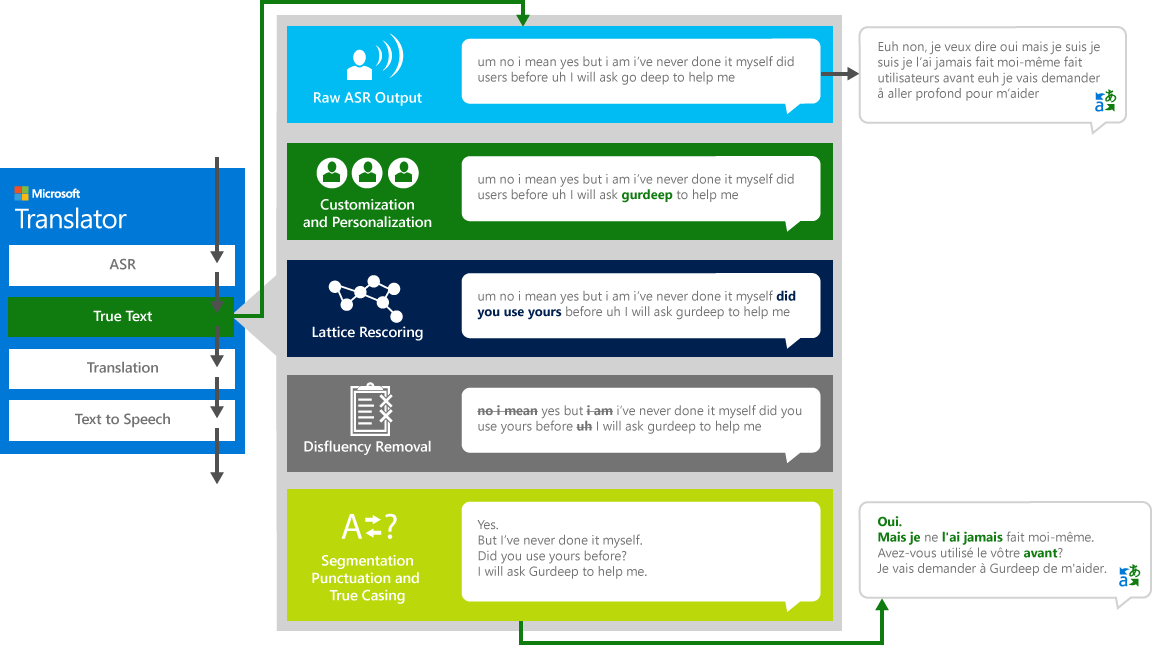
Pentru a traduce corect discursul "sursă" dintr-o limbă într-o altă limbă "țintă", sistemul trece printr-un proces în patru pași.
- Recunoașterea vorbirii, pentru a converti conținutul audio în text
- TrueText: O tehnologie Microsoft care normalizează textul pentru a o face mai potrivită pentru traducere
- Traducerea prin intermediul motorului de traducere text descris mai sus, dar pe modele de traducere special dezvoltate pentru conversații vorbite viața reală
- Text-to-Speech, atunci când este necesar, pentru a produce audio tradus.

Recunoaștere automată vorbire (ASR)
Recunoașterea automată a vorbirii (ASR) se efectuează utilizând un sistem de rețea neuronală (NN) instruit pentru analizarea a mii de ore de vorbire audio de intrare. Acest model este instruit pe interacțiunile umane-la-umane, mai degrabă decât de la om la mașină comenzi, producătoare de recunoaștere a vorbirii, care este optimizat pentru conversații normale. Pentru a realiza acest lucru, mult mai multe date sunt necesare, precum și un DNN mai mare decât tradiționale de la om la mașină ASRs.
Aflați mai multe despre Discursul Microsoft pentru serviciile de text.
TextAdevărat
Pe măsură ce oamenii discută cu alți oameni, nu vorbim la fel de perfect, clar sau îngrijit credem adesea că facem. Cu tehnologia TrueText, textul literal este transformat pentru a reflecta mai îndeaproape intenția utilizatorului prin eliminarea disfluențe vorbire (cuvinte de umplere), ar fi um, Ah s, și s, ar fi s, stutters, și repetitii. Textul este, de asemenea, făcut mai lizibil și traductibile prin adăugarea de pauze de teză, punctuație corespunzătoare, și capitalizare. Pentru a realiza aceste rezultate, am folosit decenii de lucru pe tehnologii lingvistice, am dezvoltat de la translator pentru a crea TrueText. Diagrama următoare prezintă, printr-un exemplu de viață reală, diferite transformarea TrueText operează pentru a normaliza acest text literal.
Traducere
Textul este apoi tradus în oricare dintre limbi și dialecte sunt acceptate de Translator.
Traducerile utilizând API-ul pentru traducerea vorbirii (ca dezvoltator) sau într-o aplicație sau serviciu de traducere a vorbirii, este alimentat cu cele mai noi traduceri neuronale bazate pe rețea pentru toate limbile acceptate de intrare vorbire (a se vedea aici pentru lista completă). Aceste modele au fost, de asemenea, construite prin extinderea actuale, cea mai mare parte scris-text instruit modele de traducere, cu mai vorbită-text corpora pentru a construi un model mai bun pentru tipurile de conversație vorbite de traduceri. Aceste modele sunt, de asemenea, disponibile prin categoria standard "vorbire" de text tradițional de traducere API.
Pentru orice limbă care nu este acceptată de traducerea neuronală, se efectuează traducerea tradițională SMT.
Text în vorbire
Dacă limba țintă este una dintre cele 18 acceptate de text-to-speech Limbi, iar cazul de utilizare necesită o ieșire audio, textul este apoi convertit în ieșire vorbire folosind sinteza vorbirii. Această etapă este omisă în scenarii de traducere vorbire-la-text.
Aflați mai multe despre Textul Microsoft la serviciile de vorbire.
Cercetare
Vizualizați cele mai recente lucrări de cercetare din echipa Microsoft Translator.



