
Brengen AI vertaling naar edge-apparaten met Microsoft Translator
In november 2016, Microsoft bracht het voordeel van AI-Powered machine translation, aka neurale machine translation (NMT), aan ontwikkel-en eindgebruikers gelijk. Vorige week Microsoft bracht NMT mogelijkheid om de rand van de wolk door gebruik te maken van de NPU, een AI-dedicated processor geïntegreerd in de Mate 10, Nieuwste vlaggenschip van Huawei telefoon. De nieuwe chip maakt AI-Powered vertalingen beschikbaar op het apparaat, zelfs in het ontbreken van toegang tot internet, waardoor het systeem om vertalingen waarvan de kwaliteit is op gelijke voet met het online systeem te produceren.
Om deze doorbraak te bereiken, hebben onderzoekers en ingenieurs van Microsoft en Huawei gewerkt aan het aanpassen van neurale vertaling aan deze nieuwe computeromgeving.
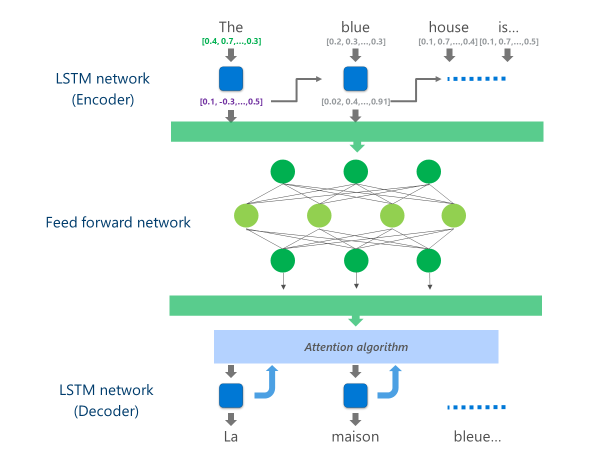
De meest geavanceerde NMT systemen die momenteel in productie (dat wil zeggen, gebruikt op schaal in de wolk door bedrijven en apps) zijn met behulp van een neuraal netwerkarchitectuur combineren van meerdere lagen van LSTM netwerken, een aandacht-algoritme, en een vertaling (decoder) laag.
De animatie hieronder legt, op een vereenvoudigde manier, hoe deze multi-layer neuraal netwerk functioneert. Voor meer details, verwijzen wij u naar de "Wat is machine translation pagina"op de Microsoft Translator site.

In deze Cloud NMT implementatie, deze middelste LSTM lagen verbruiken een groot deel van de rekenkracht. Om te kunnen volledige NMT draaien op een mobiel apparaat, was het noodzakelijk om een mechanisme dat deze computationele kosten kunnen verminderen met behoud van, zo veel mogelijk, de vertaling kwaliteit te vinden.
Dit is waar Huawei neurale processing unit (NPU) in het spel komt. Microsoft onderzoekers en ingenieurs maakten gebruik van de NPU, die specifiek is ontworpen om uit te blinken bij lage latency AI berekeningen, om operaties die onaanvaardbaar zou zijn geweest om te verwerken op de belangrijkste CPU offload.
Uitvoering
De implementatie nu beschikbaar op de Microsoft Translator app voor de Huawei mate 10 optimaliseert de vertaling door het laden van de meest reken-intensieve taken naar de NPU.
Concreet, deze implementatie vervangt deze middelste LSTM netwerklagen door een diepe feed-forward neuraal netwerk. Diepe feed-forward neurale netwerken zijn krachtig, maar vereisen zeer grote hoeveelheden van de berekening als gevolg van de hoge connectiviteit tussen neuronen.
Neurale netwerken vertrouwen voornamelijk op matrix vermenigvuldigingen, een operatie die niet complex is vanuit een wiskundig oogpunt, maar erg duur wanneer uitgevoerd op de schaal die nodig is voor een dergelijk diep neuraal netwerk. De Huawei NPU blinkt uit in het uitvoeren van deze matrix vermenigvuldigingen in een massaal parallelle manier. Het is ook vrij efficiënt vanuit een oogpunt van de machts benutting, een belangrijke kwaliteit op batterij aangedreven apparaten.
Op elke laag van deze feed-forward netwerk, de NPU berekent zowel de ruwe neuron output en de daaropvolgende ReLu activeringsfunctie efficiënt en met zeer lage latentie. Door gebruik te maken van de ruime High-Speed geheugen op de NPU, het voert deze berekeningen in parallel zonder de kosten te betalen voor de overdracht van gegevens (dat wil zeggen, vertragen prestaties) tussen de CPU en de NPU.
Zodra de definitieve laag van dit diepe Voer-voorwaartse netwerk wordt gegevens verwerkt, heeft het systeem een rijke vertegenwoordiging van de brontaal zin. Deze vertegenwoordiging wordt vervolgens gevoed door een van links naar rechts LSTM "decoder" om elke doeltaal woord te produceren, met dezelfde aandacht algoritme gebruikt in de online versie van de NMT.
Als Anthony Aue, een van de belangrijkste Software Development Engineer in de Microsoft Translator team legt uit: "het nemen van een systeem dat draait op krachtige Cloud servers in een datacenter en draait het ongewijzigd op een mobiele telefoon is geen haalbare optie. Mobiele apparaten hebben beperkingen in de rekenkracht, het geheugen en het stroomverbruik die cloud-oplossingen niet hebben. Na toegang tot de NPU, samen met enkele andere architectonische tweaks, konden we werken rond veel van deze beperkingen en het ontwerpen van een systeem dat snel en efficiënt kan worden uitgevoerd op het apparaat zonder de vertaling kwaliteit compromis."

De implementatie van deze Vertaal modellen op de innovatieve NPU chipset stond Microsoft en Huawei toe om op-apparaat neurale vertaling op een kwaliteit te leveren vergelijkbaar met die van cloud-based systemen zelfs wanneer u van het net bent.



