


Azure OpenAI の活用シナリオと最近の動向
Executive Summary
- 生成AIに対する関心が高まり、企業等での利用だけではなく公的機関でも、職員の働き方改革や市民サービスの質向上が期待されています。一方で医療の分野では、医師の時間外労働の上限規制が始まり、医療従事者の就労環境改善が必須となっています。
- 長時間労働の原因となっている文書関連の事務作業の負荷軽減のため、診療サマリーやヒヤリ・ハット事例などの文書作成に生成AIを活用した、業務効率化と誤記防止が期待されています。
- 生成AIは大規模言語モデル(LLM)を基盤とし、利用開始のハードルが低く、一定の精度で処理が可能な点がメリットです。ハルシネーションのリスクに対しては、RAGモデル等による対策が進んでいます。
- Azure OpenAIは進化を続け、他のAzure Data & AIソリューションと組み合わせることで多様なデータと利活用シナリオへの対応が可能になっています。
昨年から何度かこのヘルスケアブログでも取り上げている生成AIについて、世の中の関心はますます高まっており、様々な業種において具体的な導入・検証が盛んに進められています。この動きは一部大手の民間企業だけのものではなく、政府、行政機関をはじめとする公的なサービスを担う組織においても、職員の働き方を変革していく手段として、また市民へのより質の高いサポートを実現するための道具としても期待が寄せられています。
医療の世界においても、生成AIの活用による効率化が期待されている分野の一つとして、病院に勤務する医師の長時間労働の改善が挙げられます。特に令和6年4月からは、医師の時間外労働の上限規制の適用が始まったことも背景として、医療従事者の就労環境の改善が必須となっています。
参考 厚生労働省 「医師の時間外労働の上限規制の解説」
以下の調査結果は、厚生労働省の調査研究からの引用に基づく、医師の長時間労働の原因に対するアンケート結果です。この中で、②の記録や報告書作成、書類の整理といった文書関連の事務作業の負荷が高いことが見て取れます。併せて④⑤のように、調整のためのコミュニケーションに要する時間や自己研鑽のための時間も、残業の増加につながっていると回答されています。
【調査結果】 病院医師の勤務実態 – 主な時間外労働
長時間労働の主な要因:
- 緊急対応(80%)
- 記録・報告書作成や書類の整理(80%)
- 手術や外来対応等の延長(70%)
- 多職種・他機関との連絡調整(40%)
- 会議・勉強会・研修会等への参加(30%)
※パーセントは時間外労働の原因であると回答した医師の割合
出典:医療分野の勤務環境改善マネジメントシステムに基づく医療機関の取組に対する支援の充実を図るための調査・研究.pdf (mhlw.go.jp)
こうした課題の解決を支援するために、生成AIがどのように活用可能かについて、次にご紹介します。
1.医療現場での活用シナリオ(例)
NPO法人日本医師事務作業補助研究会によると、医師や事務作業補助者による主な文書として以下のような例が挙げられています。
文書例:
- 保険会社・病院様式診断書
- 外来診療情報提供書
- 外来内服薬の処方
- 入院退院サマリー
- 入院診療情報提供書
- 入院診療記録
など
出典:NPO法人日本医師事務作業補助研究会
ここでは「診療サマリー」を生成AIによって作成するシナリオについてご紹介します。
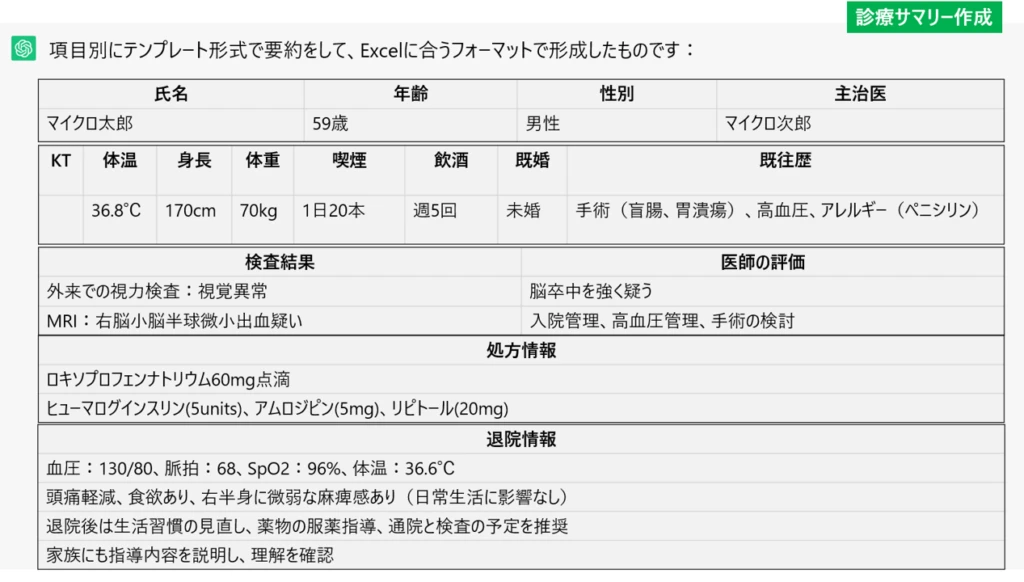
こちらは、電子カルテから出力した診療記録の生データとなっています。このデータをもとに、Azure OpenAIに対して図の上部記載の「あなたは医者です。患者情報を迅速に確認したいです・・(以下略)」といった、プロンプトを実行します。プロンプトとは、生成AIに対する指示や要求を与えるための入力文です。具体的で明確に指示をすることで、より正確な結果を得ることができます。

実行結果がこちらとなります。診療記録のサマリーの体裁で、AIが文書を自動整形してくれることで、転記・二重入力の負荷が下がり、誤記や漏れ等も防止できます。ただし、幾つかの項目はAIが専門用語の意味を理解できない等の原因で拾えないケースもあるため、その点は医師等による追記は必要となりますが、一から全て手作業で作成するよりも業務効率化を実現できると考えられます。
もう1つヒヤリ・ハット事例収集の業務への適用例をご紹介します。
下記の図の左側にある看護記録例には、赤枠部分にヒヤリ・ハットの事案が記載されています。
ここでAIに対して、「以下の看護記録から、医療事故情報収集等事業で記載されている各項目を抜き出し(以下略)」のプロンプトを実行した結果が、図の右側の表となります。

従来は看護記録から転記していたこのような業務も、生成AIを活用することによりその多くの作業を効率化できると考えられます。
こうしたケースは、さらに汎化してとらえると、一つの様式のデータをカルテで作成し、別の様式に転記や二重入力していた業務、別々のシステムをそれぞれ使用して非効率となっていた作業を、生成AIをチャットのような汎用的なインターフェースから利用することで、代替できる可能性を示しているといえます。生成AIは、人が都度入力するのではなく、システムの中でデータ連携することで、指示・回答を自動化することもできます。
- 生成AI(LLM)のメリットと回答精度の向上策
ご存じの通りAzure OpenAI に代表される生成AIサービスは、大規模言語モデル(LLM)と呼ばれる自然言語処理技術が基礎となっています。LLMは、既に過去の大量の公開情報を学習しており、ユーザが特別に意識することなく直ぐに使用でき、前章で述べた例のようにある程度の精度の高さで処理が実行されるという点で、利用開始のハードルが低いという点が大きなメリットです。
一方で、「ハルシネーション(幻覚)」と称されるような、事実に基づかない情報を生成する可能性もあり、それらは学習データの偏りや誤り、入力された質問(プロンプト)の文脈を正しく理解できない場合に生じうる挙動であることも知られています。医療情報のように一般の事務よりも高い精度が要求される業務においては、こうしたリスクに対して、生成AIの利用に慎重な面もありましたが、実績によりハルシネーションへの対策が明確になり、利用検討が活発にされるようになりました。
ハルシネーションの対策として取り上げられる方式として、RAG(Retrieval Augmented Generation)モデルがあります。これは、生成AIのLLMモデルが使用する公開情報によるトレーニング済みデータに加えて、多様なデータソースからの情報検索を組み合わせる仕組みです。これにより、学習済みデータを補完し、正確な回答を応答することに寄与します。
ファインチューニングという、必要な学習データを準備して、既存の生成AIに追加学習させる方法もあります。必要な学習データを準備して学習させ、追加学習させた生成AIモデルを管理することが継続的に必要となります。既成の生成AIモデルと検索を組み合わせるRAGモデルと比べると運用負荷がかかるため、RAGモデルから検証を始めるケースがスタンダードになっています。
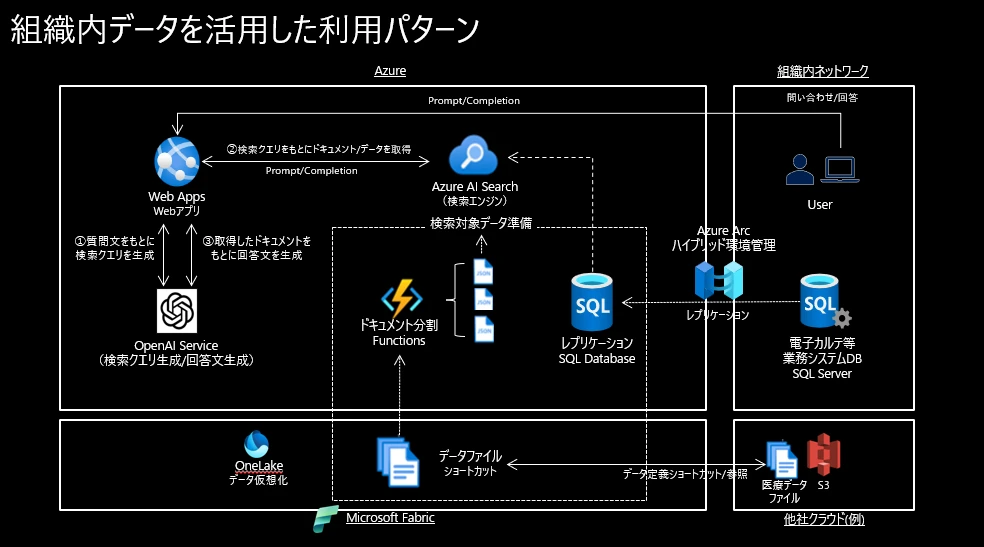
下の図は、組織内の情報を検索するシステムにおいて、Azure OpenAI Serviceと全文検索エンジンAzure AI Searchを組み合わせて利用することで高度かつ自然な回答内容を生成してユーザに返す仕組みを実現するためのサンプルアーキテクチャです。
このアーキテクチャは、Azure OpenAI を使用する際のRAGモデルの一例であるとともに、加えてオンプレミス上の院内ネットワーク上にある電子カルテ等の業務システムDBをクラウド(Azure)上にレプリケーションすることで、電子カルテ等のデータを検索対象として組み入れることを可能とし、同時に災害時のバックアップデータをクラウド上に退避させることもできます。Azure Arcを組み合わせて使用すると、さらなるメリットを享受できます。Azure Arcは、Azure以外の場所にある分散したサーバ環境をAzure上で一元管理するためのサービスです。具体的には、オンプレミスにある業務システムや他のパブリッククラウド環境の既存の仮想マシンなどの様々なリソースをAzure Arcに接続することで、統合管理ができるようになります。 Azure Arcを導入すると、オンプレミスに設置された電子カルテのデータベースSQL Serverをクラウド上で一元管理したり、クラウド利用料金のように利用時間単位の月額払いで使用したりすることも可能となります。
さらに2023年後半にリリースされた新しいサービスであるMicrosoft Fabric を利用することにより、Azureだけでなく他社クラウド上にあるデータも仮想化して、あたかも実態があるかのように検索対象とすることができます。生成AIの活用による業務効率化を進めるためには、業務上必要なデータが点在していることが課題になります。Microsoft Fabric は、サイロ化し分散したデータの「民主的なデータメッシュ」として機能し、データを一箇所で中央集権的に管理するのではなく、各部門やチームが自分たちのデータを自律的に管理・活用できるようにし、組織全体のデータガバナンスに寄与します。
- 他のAIを組み合わせることで広がる利用シーン
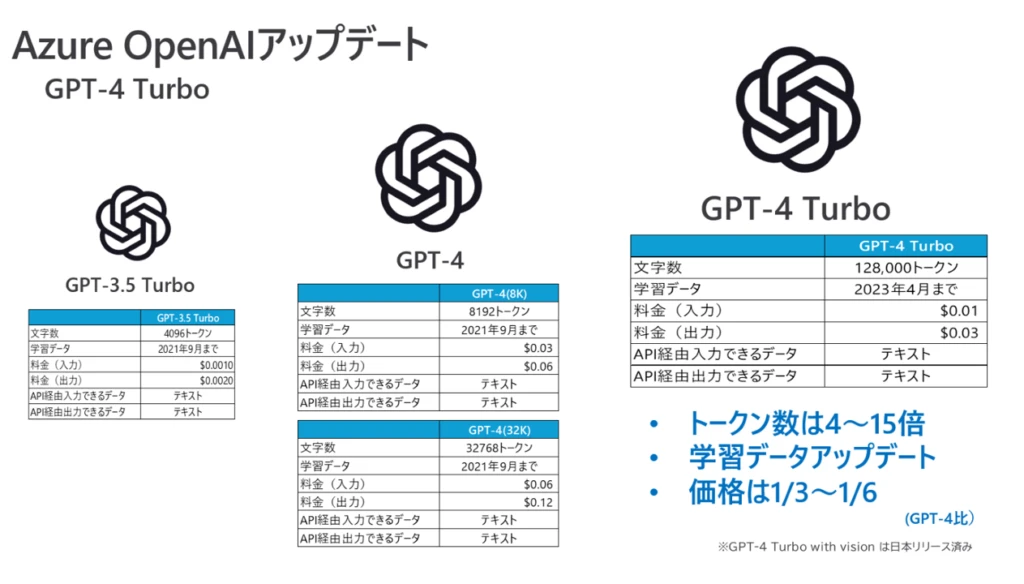
生成AIの歴史は未だ始まったばかりであり、日々進化を遂げている途上でもあります。Azure OpenAIも、GPT-3.5からGPT-4、GPT-4-Turboへとアップデートしており、扱えるトークン数(文字数をカウントする値)も大幅に拡大しています。規約やガイドラインといった長文のコンテンツを、直接プロンプトにインプットし、過去の文例を参考にしながら改定されたドキュメントを自動で下書きさせるといった用途へも広がりを見せています。かつ、トークン当たりの価格は、以前のバージョンよりも安価であるという点でも、利用しやすさのメリットが向上しているといえます。さらに、直近ではGPT-4o という新しいバージョンのモデルの提供も開始し、さらなる精度と応答速度の向上により、利用シナリオの拡大が見込まれています。
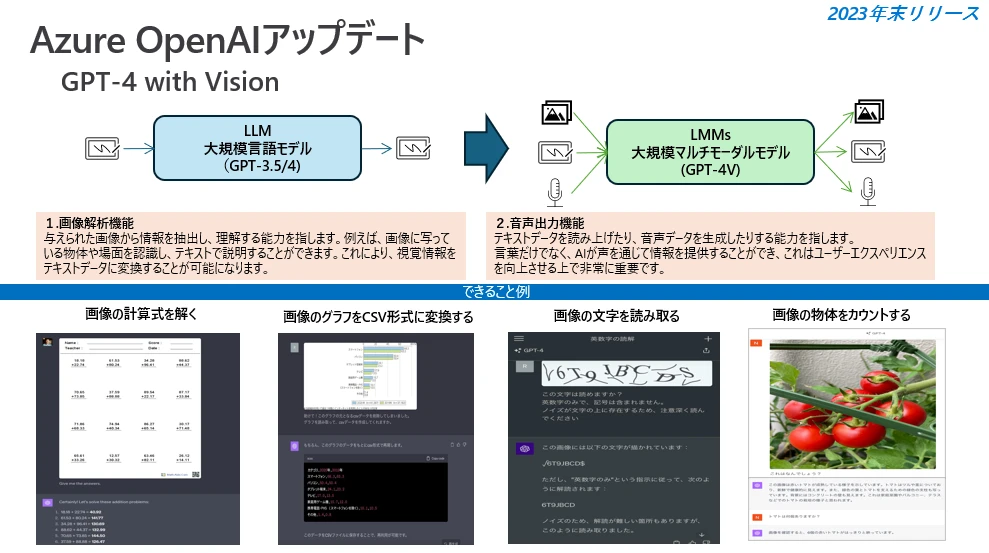
また、LLMは言語領域だけでなく画像や動画、音声もインプットデータとして処理できるようになってきており、これを大規模マルチモーダルモデルと呼んでいます。下図はその一例ですが、医療の分野でも画像等のデータを扱うシステム(PACS等)との組合せや、音声の記録や会議録を入力としたり、逆にテキストから音声によるガイダンスを自動生成したり、といった利用シナリオへと発展する可能性が期待されています。
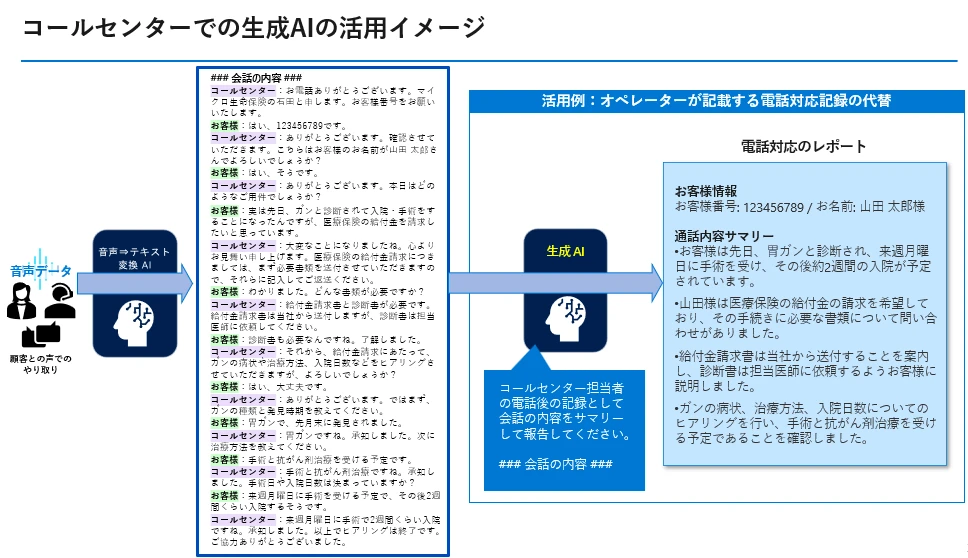
下図は、異業種ですが金融業界におけるコールセンター業務へ生成AIの活用イメージとなります。お客様とオペレータのやりとりを音声からリアルタイムにテキスト情報に変換し、その内容に基づいて生成AI側がバックヤードで電話対応のレポートを自動作成することで業務効率化を図るといった例です。ここからさらに過去のQA記録に対するナレッジ検索AI、生成AIによる自然言語処理、そしてテキストを音声に変換するAI等を組み合わせて、お客様に対する音声回答まで自動で行う仕組みが考えられます。そして、これらはAIの翻訳サービスと組み合わせることにより、外国人のお客様や相談者に対する多言語での応対をAIにより実現する仕組みへと発展させることも可能と考えます。
最後に
このブログでは、生成AIの医療分野での活用シナリオから始まり、進化を続けるAIの様々なサービスコンポーネントを上手く組み合わせることによって、より精度の高い回答、より多くの種類のデータの取り扱いが可能となってきていることをご説明いたしました。
ここまでご紹介してきたAI活用のベースになるのは、元となる情報・データが適切に記録され蓄積されていることが前提となります。医療の現場で使用される電子カルテ等についても同様です。診療と平行して行う入力作業の負荷軽減にも併せて対処が必要であり、そこではAzure AIのSpeech to Text を使用し音声⇒テキスト変換を組み合わせるといった方策も考えられます。
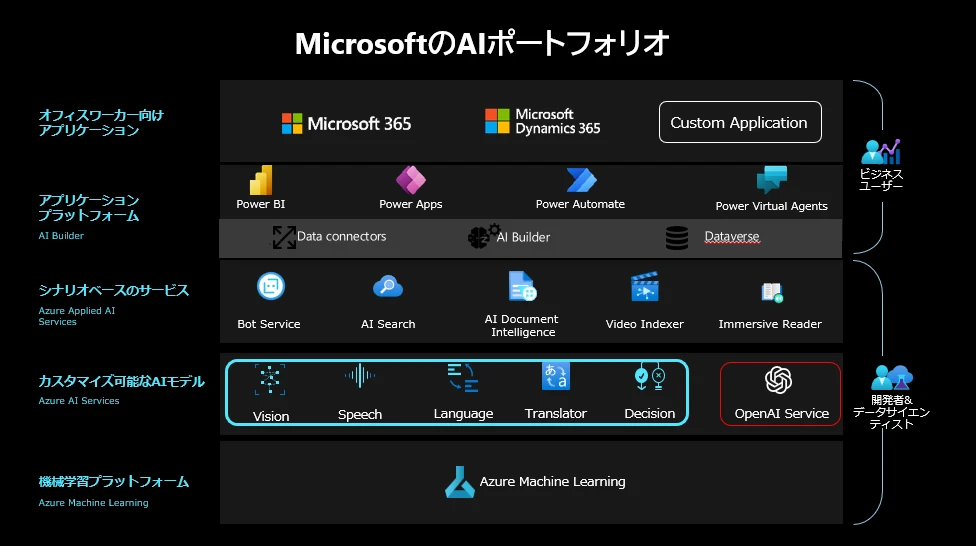
Microsoft Azureでは、下図に示すようにOpenAI サービス以外にも各種ラインナップを取り揃えており、お客様の実現したい利用シナリオを柔軟に構築することが可能です。
ここでご紹介したAzure OpenAIサービスは、既にISMAPへも登録済みです。またサービス契約に関する管轄裁判所も日本となり、SLAも設定されており、サポートもMicrosoftで一元的に提供が可能です。
ぜひ、皆様のこれからの顧客サービス向上、業務効率化をプランニングされる際に、Microsoft Azureをご検討いただけますと幸いです。


