
Traducción automática
¿Qué es la traducción automática?
Los sistemas de traducción automática son aplicaciones o servicios en línea que utilizan tecnologías de aprendizaje automático para traducir grandes cantidades de texto desde y hacia cualquiera de sus idiomas soportados. El servicio traduce un texto "fuente" de un idioma a otro idioma "target".
Aunque los conceptos detrás de la tecnología de traducción automática y las interfaces para usarlas son relativamente simples, la ciencia y las tecnologías detrás de ella son extremadamente complejas y reúnen varias tecnologías de vanguardia, en particular, el aprendizaje profundo ( inteligencia artificial), grandes datos, lingüística, Cloud Computing y APIs Web.
Desde principios de 2010, una nueva tecnología de inteligencia artificial, redes neuronales profundas (aka Deep Learning), ha permitido que la tecnología de reconocimiento de voz alcance un nivel de calidad que permitió al equipo de traductores de Microsoft combinar el reconocimiento de voz con su tecnología de traducción de texto principal para lanzar una nueva tecnología de traducción de voz.
Históricamente, la técnica de aprendizaje de máquinas primaria utilizada en la industria fue la traducción automática estadística (SMT). SMT utiliza el análisis estadístico avanzado para estimar las mejores traducciones posibles para una palabra dada el contexto de unas pocas palabras. SMT ha sido utilizado desde mediados de la década de 2000 por todos los principales proveedores de servicios de traducción, incluyendo Microsoft.
El advenimiento de la traducción automática neuronal (NMT) causó un cambio radical en la tecnología de la traducción, dando como resultado traducciones de calidad mucho más elevadas. Esta tecnología de traducción comenzó a desplegar para usuarios y desarrolladores en el última parte de 2016.
Las tecnologías de traducción SMT y NMT tienen dos elementos en común:
- Ambos requieren grandes cantidades de contenido traducido pre-humano (hasta millones de frases traducidas) para entrenar los sistemas.
- No actúan como diccionarios bilingües, traduciendo palabras basadas en una lista de traducciones potenciales, sino que se traducen basándose en el contexto de la palabra que se utiliza en una oración.
¿Qué es Translator?
Servicios de traductor y habla, parte de la Servicios cognitivos colección de APIs, son servicios de traducción automática de Microsoft.
Traducción de texto
Translator ha sido utilizado por los grupos de Microsoft desde 2007 y está disponible como una API para los clientes desde 2011. El traductor se utiliza ampliamente en Microsoft. Está incorporado en los equipos de localización de productos, soporte y comunicación en línea. Este mismo servicio también es accesible, sin coste adicional, desde productos conocidos de Microsoft como Bing, Cortana, Microsoft Edge, Oficina, Sharepoint, Skypey Yammer.
El traductor se puede utilizar en aplicaciones web o cliente en cualquier plataforma de hardware y con cualquier sistema operativo para realizar la traducción del idioma y otras operaciones relacionadas con el idioma, como la detección de idioma, texto a voz o diccionario.
Aprovechando la tecnología de REST estándar de la industria, el desarrollador envía texto de origen (o audio para traducción de voz) al servicio con un parámetro que indica el idioma de destino, y el servicio devuelve el texto traducido para que el cliente o la aplicación web utilicen.
El servicio Translator es un servicio de Azure hospedado en centros de datos de Microsoft y se beneficia de la seguridad, escalabilidad, confiabilidad y disponibilidad sin parar que también reciben otros servicios en la nube de Microsoft.
Traducción de voz
La tecnología de traducción de voz de Translator se lanzó a finales de 2014, empezando por Skype Translator, y está disponible como una API abierta para los clientes desde principios de 2016. Está integrada en la función en directo de Microsoft Translator, en Skype, en la transmisión de reuniones de Skype y en las aplicaciones de Microsoft Translator para Android e iOS.
La traducción de voz ya está disponible a través de Microsoft Speech, un conjunto end-to-end de servicios totalmente personalizables para el reconocimiento de voz, la traducción del habla y la síntesis de voz (Text-to-Speech).
¿Cómo funciona la traducción de texto?
Hay dos tecnologías principales usadas para la traducción del texto: la herencia una, traducción de la máquina estadística (SMT), y la más nueva generación una, traducción de la máquina de los nervios (NMT).
Traducción automática estadística
La implementación de Translator de Traducción De Máquina Estadística (SMT) se basa en más de una década de investigación en lenguaje natural en Microsoft. En lugar de escribir reglas hechas a mano para traducir entre idiomas, los sistemas de traducción modernos abordan la traducción como un problema para aprender la transformación del texto entre idiomas a partir de traducciones humanas existentes y aprovechar los avances recientes en estadísticas aplicadas y aprendizaje automático.
Los llamados "corporas paralelos" actúan como una piedra Rosetta moderna en proporciones masivas, proporcionando palabras, frases y traducciones idiomáticas en contexto para muchos pares de idiomas y dominios. Las técnicas de modelado estadístico y los algoritmos eficientes ayudan al equipo a abordar el problema del descifrado (que detecta las correspondencias entre el idioma de origen y de destino en los datos de entrenamiento) y la decodificación (encontrar la mejor traducción de una nueva oración de entrada). El traductor une el poder de los métodos estadísticos con la información linguística para producir modelos que generalicen mejor y conduzcan a traducciones más comprensibles.
Debido a este enfoque, que no se basa en diccionarios o reglas gramaticales, proporciona las mejores traducciones de frases en las que puede utilizar el contexto en torno a una palabra determinada versus tratar de realizar traducciones de una sola palabra. Para las traducciones de palabras sencillas, el diccionario bilingüe fue desarrollado y es accesible a través de www.Bing.com/Translator.
Traducción automática neural
Las mejoras continuas en la traducción son importantes. Sin embargo, las mejoras de rendimiento se han estancado con la tecnología SMT desde mediados de la década de 2010. Al aprovechar la escala y la potencia del superordenador de IA de Microsoft, específicamente Microsoft Cognitive Toolkit, Translator ahora ofrece red neuronal (LSTM) basado en la traducción que permite una nueva década de mejora de la calidad de la traducción.
Estos modelos de red neuronal están disponibles para todos los lenguajes de voz a través del servicio de voz en Azure y a través de la API de texto mediante el identificador de categoría 'generalnn'.
Las traducciones de redes neuronales difieren fundamentalmente en la forma en que se realizan en comparación con las tradicionales SMT.
La siguiente animación muestra los distintos pasos que las traducciones de redes neuronales pasan para traducir una oración. Debido a este enfoque, la traducción tomará en contexto la frase completa, versus sólo unas pocas palabras ventana deslizante que utiliza la tecnología SMT y producirá traducciones más fluidas y traducidas en humanos.
Basándose en el entrenamiento de la red neural, cada palabra está codificada a lo largo de un vector de 500 dimensiones (a) que representa sus características únicas dentro de un par de idiomas en particular (por ejemplo, Inglés y chino). Basándose en los pares de idiomas utilizados para la formación, la red neuronal se autodefine cuáles deben ser estas dimensiones. Podrían codificar conceptos simples como el género (femenino, masculino, neutro), el nivel de cortesía (argot, casual, escrito, formal, etc.), el tipo de palabra (verbo, sustantivo, etc.), pero también cualquier otra característica no obvia como derivado de los datos de entrenamiento.
Los pasos que atraviesan las traducciones de redes neuronales son los siguientes:
- Cada palabra, o más específicamente el vector de dimensión 500 que lo representa, pasa a través de una primera capa de "neuronas" que lo codificará en un vector de 1000 dimensiones (b) que represente la palabra dentro del contexto de las otras palabras de la oración.
- Una vez que todas las palabras se han codificado una vez en estos vectores de la dimensión 1000, el proceso se repite varias veces, cada capa permitiendo un mejor Fine-Tuning de esta representación de la 1000-dimensión de la palabra dentro del contexto de la oración completa (contraria a SMT tecnología que sólo puede tener en cuenta una ventana de 3 a 5 palabras)
- La matriz de salida final es utilizada entonces por la capa de atención (es decir, un algoritmo de software) que usará tanto esta matriz de salida final como la salida de palabras traducidas previamente para definir qué palabra, a partir de la frase de origen, debe traducirse a continuación. También usará estos cálculos para potencialmente soltar palabras innecesarias en el idioma de destino.
- La capa de decodificador (traducción), traduce la palabra seleccionada (o más específicamente el vector de dimensión 1000 que representa esta palabra en el contexto de la oración completa) en su equivalente de idioma de destino más apropiado. La salida de esta última capa (c) se vuelve a alimentar en la capa de atención para calcular qué palabra siguiente de la frase de origen debe traducirse.

En el ejemplo representado en la animación, el modelo de dimensión 1000 del contexto "la"se codificará que el sustantivo (Casa) es una palabra femenina en francés (la Maison). Esto permitirá la traducción apropiada para "la"ser"la"y no"le"(singular, varón) o"les"(plural) una vez que llega a la capa de decodificador (traducción).
El algoritmo de atención también calculará, basándose en la palabra (s) previamente traducida (en este caso "la"), que la siguiente palabra a traducir debe ser el tema ("Casa") y no un adjetivo ("Azul"). En puede lograr esto porque el sistema aprendió que el inglés y el francés invierten el orden de estas palabras en oraciones. También habría calculado que si el adjetivo fuera a ser "Gran"en lugar de un color, que no debe invertirlos ("la casa grande"= >"la grande Maison").
Gracias a este enfoque, la producción final es, en la mayoría de los casos, más fluida y más cercana a una traducción humana que una traducción basada en SMT podría haber sido alguna vez.
¿Cómo funciona la traducción de voz?
Translator también es capaz de traducir el habla. Esta tecnología se expone en la función en vivo de Translator (http://translate.it), el traductor Apps, el traductor de Skype y también se hace inicialmente disponible sólo a través de la función de traductor de Skype y en las aplicaciones de Microsoft Translator en iOS y Android, esta funcionalidad está ahora disponible para los desarrolladores con la última versión de la abierta API basada en REST disponible en el portal Azure.
Aunque puede parecer como un proceso directo a primera vista para construir una tecnología de traducción de voz de los ladrillos de la tecnología existente, se requiere mucho más trabajo que simplemente enchufar un "tradicional" de reconocimiento de voz humano a máquina motor a la traducción de texto existente una.
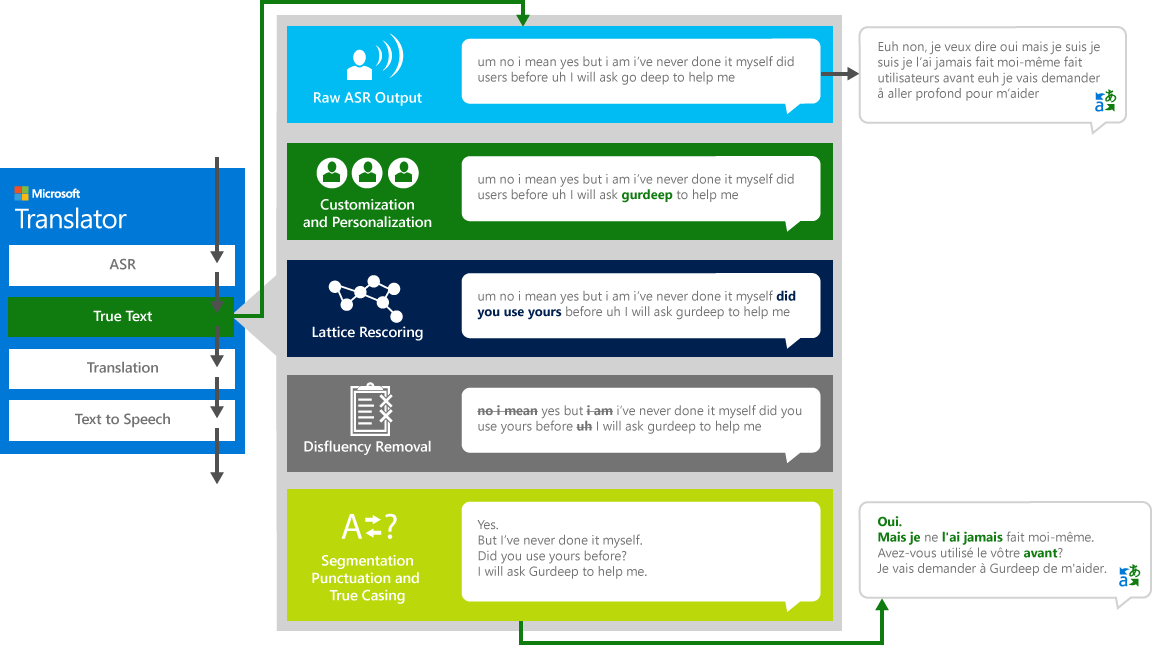
Para traducir correctamente el discurso "fuente" de un idioma a otro idioma "target", el sistema pasa por un proceso de cuatro pasos.
- Reconocimiento de voz, convertir audio en texto
- TrueText: una tecnología de Microsoft que normaliza el texto para que sea más apropiado para la traducción
- Traducción a través del motor de traducción de texto descrito anteriormente pero sobre modelos de traducción especialmente desarrollados para conversaciones habladas en la vida real
- Texto a voz, cuando sea necesario, para producir el audio traducido.

Reconocimiento automático de voz (ASR)
El reconocimiento automático de voz (ASR) se realiza utilizando un sistema de red neural (NN) entrenado en el análisis de miles de horas de voz de audio entrante. Este modelo está entrenado en interacciones humano-humanos en lugar de comandos humanos-a-máquina, produciendo reconocimiento de voz optimizado para conversaciones normales. Para lograr esto, se necesitan muchos más datos, así como un DNN más grande que el ASRS tradicional de la persona a la máquina.
Más información sobre El discurso de Microsoft en los servicios de texto.
TrueText
Como seres humanos que conversan con otros seres humanos, no hablamos tan perfectamente, claramente o cuidadosamente como pensamos a menudo que hacemos. Con la tecnología TrueText, el texto literal se transforma para reflejar más estrechamente la intención del usuario al eliminar el disfluencies de voz (palabras de relleno), como "um", "Ah", "y" s, "como" s, tartamudeos y repeticiones. El texto también se hace más legible y traducible mediante la adición de pausas de oración, puntuación adecuada y capitalización. Para lograr estos resultados, hemos utilizado las décadas de trabajo en tecnologías lingüísticas, hemos desarrollado desde el traductor para crear TrueText. El siguiente diagrama muestra, a través de un ejemplo de la vida real, la varia transformación TrueText opera para normalizar este texto literal.
Traducción
El texto se traduce entonces en cualquiera de los idiomas y dialectos con el apoyo de Translator.
Las traducciones que utilizan la API de traducción de voz (como desarrollador) o en una aplicación o servicio de traducción de voz, se alimentan con las más recientes traducciones basadas en redes neuronales para todos los idiomas soportados por voz (consulte aquí para la lista completa). Estos modelos también fueron construidos expandiendo los modelos de traducción entrenados, en su mayoría con texto escrito, con más corpus de texto hablado para construir un modelo mejor para los tipos de traducción de conversación hablada. Estos modelos también están disponibles a través de la Categoría estándar del "discurso" de la API de traducción de texto tradicional.
Para cualquier idioma no soportado por la traducción neural, se realiza la traducción tradicional de SMT.
Texto a voz
Si el idioma de destino es uno de los 18 texto-a-voz apoyado Idiomas, y el caso del uso requiere una salida audio, el texto entonces se convierte en salida del discurso usando síntesis de discurso. Esta etapa se omite en los escenarios de traducción de voz a texto.
Más información sobre El texto de Microsoft a los servicios de voz.
Investigación
Vea los trabajos de investigación más recientes del equipo de Microsoft Translator.
- Traducción automática neuronal universal para lenguajes de recursos extremadamente bajos
- Lograr la paridad humana en chino automático a Inglés traducción de noticias
- Traducción de lenguaje hablado de género en Inglés-Árabe
- Datos sintéticos para la traducción de la máquina de los nervios de hablado-Dialectos



