
Intelligent Query Processing: feature family additions
Part of the SQL Server 2022 blog series.
SQL Server 2022 introduces a handful of new members to the growing Intelligent Query Processing (IQP) family. These additions range from expanding and improving various query performance feedback mechanisms to adding two new features—parameter sensitive plans (PSPs) and optimized plan forcing. In this blog, we give a general overview of these additions, with detailed feature-specific blogs to follow.
Feedback features
SQL Server 2022 introduces two new query plan feedback features: degree of parallelism feedback and cardinality estimation feedback, and it improves the overall experience of the existing feedback feature: memory grant feedback.
Memory grant feedback
Memory grant feedback is a feature that was introduced in SQL Server 2017. It looks at executions of a query and determines if the query is using more memory than it was granted (spill to disk), or if it is using way less than it was granted (possibly limiting throughput potential). As a query is executed multiple times, the system learns the amount of memory typically used by the query and adjusts the grant according to the needs of previous executions. In this release we have improved memory grant feedback in two significant ways:
- Plan feedback is now persisted on disk. This means feedback is retained across cache evictions and server restarts.
- We have improved the algorithm that generates feedback to look at more of the query history before advising. This prevents issues that previously occurred if a plan had widely vacillating memory needs (as might be seen with a parameter sensitive plan).
As a result, users can benefit from memory grant feedback in a wider range of scenarios—and without requiring any re-learning of feedback after a restart, failover, or plan cache eviction.
Degree of parallelism feedback
SQL Server has long allowed users to specify a maximum degree of parallelism (DOP) for a server or for individual queries. However, fine-tuning the most performant DOP for every query in a workload can be time-consuming and arduous, and, in some cases, has not been easily possible without underlying code change to the workload. In SQL Server 2022, DOP feedback can detect opportunities to reduce the DOP for a query. DOP feedback reduces the DOP in steps until the query is running with an amount of parallelism that optimizes CPU usage and query performance.
Many customers do not have the time or expertise to individually tailor the degree of parallelism for each individual query. DOP Feedback does this automatically—reducing CPU and overall query time while still taking advantage of the maximum DOP that works for each individual query.
Cardinality estimation feedback
Cardinality estimation (CE) is a process used by SQL Server to determine how many rows might be returned by a specific part of a query plan. This process incorporates a basic set of assumptions—called the model—to produce the estimates. However, the basic set of assumptions that works best for one query might not work as well for a different query. In previous versions of SQL Server, customers were stuck with one baseline CE model—meaning that there were always some queries that did well and some that did less well but would have performed better with a different model. There have been ways to manually adjust the model, but they required code change as well as in-depth, technical investigation. In SQL Server 2022, however, we can now fine-tune the CE model in a way that is specific to an individual query. This means, that if you have a workload with some queries performing best under one set of model assumptions, and others performing best with a different set of assumptions, all queries can be automatically adjusted by CE feedback to provide the best model for each query in the workload. This is done in a do-no-harm, automated way.
Users no longer have to limit their workload to a single CE model. Users no longer have to manually tweak the CE model for poorly performing queries. CE Feedback will automatically choose the best CE model available for the query, on a per-query basis, and without any manual intervention.
Parameter sensitive plan optimization
SQL Server uses parameters or parameter markers in Transact-SQL statements to increase its ability to match new Transact-SQL statements with existing, previously compiled execution plans and promote plan reuse. This process is also known as “parameter sniffing.” This is a technique used by SQL Server to “sniff” the current parameter values during query compilation and pass those parameters to the Query Optimizer so that the “sniffed” parameter values can be used to generate more efficient query plans. In a lot of scenarios, this process works well but sometimes it can go awry. Parameter sniffing (also known as parameter sensitivity) problems start to occur when a query plan that is efficient for a query given one set of actual parameters may be inefficient for a different set of parameters. For example:
- You execute a query with one or more parameterized predicates.
- During query compilation, the query optimizer generates a query execution plan based on compile-time parameter values. This plan is then cached and used for subsequent executions.
- You or someone else execute the same parameterized query but this time, using different runtime parameter values. The selectivity of those predicates for those runtime parameter values can be quite different from the estimated selectivity based on the compile time parameter values from when that plan was previously compiled. The compiled plan may be non-optimal for some parameter values, causing performance to suffer.
This often occurs when the data distribution within a table or tables is uneven (also known as data skew). There can be many other contributing factors to parameter sniffing problems, such as variable values that are unknown to the optimizer at compile time, code branching, and so on.
At a high level, SQL Server server assumes that at any given point in time there is one optimal plan for a query. That plan may change over time if, for example, enough data changes in a table, or column statistics get updated and change drastically, or someone simply recompiles the query. However, the assumption remains the same; the plan cache will map each query to one plan. The parameter sensitive plan optimization (PSP) feature begins to unlock SQL Server’s ability to cache two or more plans for a query at the same time, with each plan being optimal for a subset of the parameter space. PSP optimization uses the histogram on column-level statistics to identify any non-uniform distributions of data and this is really where the power lies because what we are trying to optimize for is having a plan that aligns more with defined predicate cardinality ranges or “buckets.” This alignment enables the ability to create different and optimal query plans based on the data distribution. For example, in a fictitious real estate agency let’s say that we had a table called PropertySearchByAgent. This table was used to keep track of real estate agents and the number of listings each agent had. If we wanted to view all of the listings for AgentId 1, we could use a parameterized query such as:
sp_executesql N’SELECT * FROM PropertySearchByAgent WHERE AgentId = @AgentId’, N’@AgentId inst’, 1
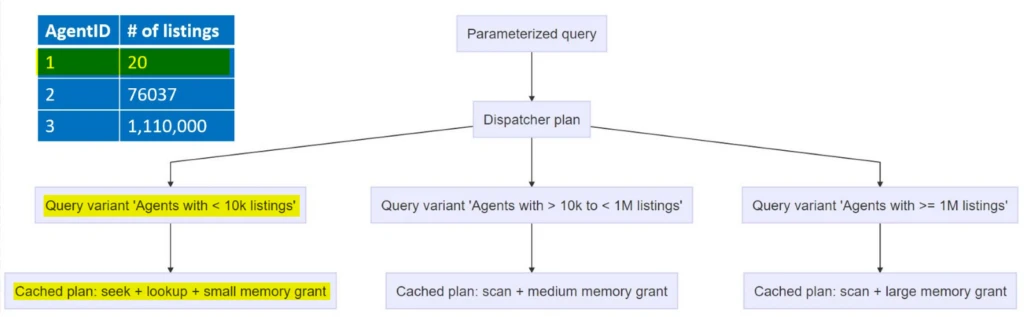
PSP optimization would determine, based on the predicate for this query WHERE AgentID equal to some value, along with the runtime cardinality of the predicate, that it will “bucketize” and create separate queries (known as query variants) to execute and cache in the plan cache. By using different query variants which map back to the original parameterized query, PSP optimization can create multiple plans for a given query. If we wanted to query the ProperySearchByAgent table for information about AgentID 3, the same parameterized query that was used previously can be used, but this time using a different parameter value of 3. Since Agent 3 has many more listings than Agent 1, PSP optimization would generate a different plan that would be more optimal for the number of listings that Agent 3 has.
As a result, one of the most common performance challenges in SQL Server is one step closer to being resolved completely. This is a foundational capability that will provide great benefits for mission-critical workloads and is foundational and will continue to improve over time.
Optimized plan forcing
Query optimization and compilation is a multi-phased process of quickly generating a “good enough” query execution plan. Query execution time includes the time it takes to compile the query. This can sometimes represent a substantial portion of the overall query execution time and consume significant system resources (such as CPU and memory). To reduce compilation overhead for repeating queries, SQL Server caches query plans for re-use. However, plans can be evicted from the cache due to memory pressure or SQL Server restarts. This can lead to subsequent calls of the previously cached queries to require a new, full compilation cycle. Optimized plan forcing, has been introduced to reduce the complication time for complex queries as well as reduce CPU and memory overhead by reducing the amount of work that the optimization process may have to go through.
- What is optimized plan forcing? Optimized plan forcing (or optimization replay) is a new addition to the IQP family whose goal is to speed up the query optimization process for repeating forced queries.
- Why would anyone use it? In certain scenarios, the database can use up a lot of resources to deal with the incoming compilation requests (for example, after a failover). To decrease the strain on the database server, optimization replay can be an effective tool.
- How does optimization replay help? Optimization replay records the history of a compilation process when a query is executed so that it can be used in the future to speed up the optimization process. It achieves this by recording an “optimization replay script” (ORS) which is a compact representation of useful rules that were applied during the optimization process. Useful rules are those that contribute to generating some expression(s) that becomes a part of the final plan.
Optimization replay (OR) consists of two phases—capture and replay. The capture phase records a compact history of rules that, based on heuristics, are determined to be useful during the optimization process, and stores them inside the Showplan XML attribute in the sys.query_store_plan table within Query Store. We refer to this recording as the optimization replay script (ORS). After the ORS is captured, you typically must mark the query plan as “forced.” Plans can also become automatically forced if the automatic plan correction feature is enabled on the database. Once the plan is marked as “forced” and there is an ORS for the plan and the plan is not already in the plan cache, we kick off the “replay” phase. The replay phase occurs during subsequent executions of the captured query. If the optimization replay requirements are satisfied, the optimization of the query will utilize the ORS to reach the final plan more quickly by skipping the optimization rules that are not part of the ORS.
Conclusion
In conclusion, these five new additions or improvements to the IQP family continue to solve some of the most common pain points customers may experience with performance. The feedback family of features tailors the query performance on a per-query basis in a way designed to reduce poor performance offsets. PSP optimization solves a problem that has long been giving customers issues, and optimized plan forcing speeds up the compilation step when users force plans. Each of these features taken individually improves some pain point or challenge—but the best part is that all these features can be used together seamlessly. Improving a single query in more than one dimension. We are proud to release these new additions to Intelligent Query Processing in SQL Server 2022.
Learn More
- Download the preview of SQL Server 2022.
- See what’s new in SQL Server 2022.
