
What’s new with SQL Server Big Data Clusters—CU13 Release
SQL Server Big Data Clusters (BDC) is a capability brought to market as part of the SQL Server 2019 release. Big Data Clusters extends SQL Server’s analytical capabilities beyond in-database processing of transactional and analytical workloads by uniting the SQL engine with Apache Spark and Apache Hadoop to create a single, secure, and unified data platform. It is available exclusively to run on Linux containers, orchestrated by Kubernetes, and can be deployed in multiple-cloud providers or on-premises.
Today, we’re proud to announce the release of the latest cumulative update, CU13, for SQL Server Big Data Clusters which includes important changes and capabilities:
- Hadoop Distributed File System (HDFS) distributed copy capabilities through azdata
- Apache Spark 3.1.2
- SQL Server Big Data Clusters runtime for Apache Spark release 2021.1
- Password rotation for Big Data Cluster’s auto-generated Active Directory service accounts during BDC deployment
- Enable Advanced Encryption Standard (AES) Optional parameter on the automatically generated AD accounts
Major improvements in this update are highlighted below, along with resources for you to learn more and get started.
HDFS distributed copy capabilities through azdata
Hadoop HDFS DistCP is a command line tool that enables high-performant distributed data copy between HDFS clusters. On SQL Server Big Data Clusters CU13 we are surfacing the capability of distcp through the new azdata bdc hdfs distcp command to enable inter Big Data Clusters distributed data copy. This enables data migration scenarios between SQL Server Big Data Clusters; supporting both secure and non-secure cluster deployment configurations.
For more information, see:
- HDFS distributed data copy—SQL Server Big Data Clusters
- azdata bdc hdfs reference—SQL Server Big Data Clusters
Apache Spark 3.1.2
Up to cumulative update 12, Big Data Clusters relied on the Apache Spark 2.4 line, which reached its end of life in May 2021. Consistent with our continuous improvement commitment to the Big Data and Machine Learning capabilities of the Apache Spark engine, CU13 brings in the current release of Apache Spark, version 3.1.2.
This new version of Apache Spark brings stellar performance benefits on big data processing workloads. Using the reference TCP-DS 10 TB workload in our tests we were able to reduce runtime from 4.19 hours to 2.96 hours, a 29.36 percent improvement achieved just by switching engines while using the same hardware and configuration profiles, no additional application optimizations. The improvement mean of individual query runtime is 36 percent.
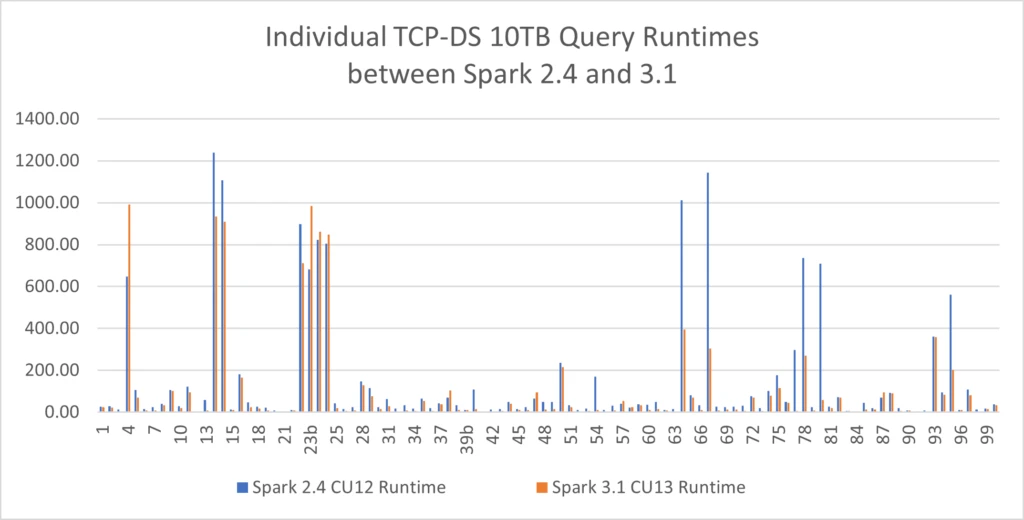
Spark 3 is a major release and as such, contains breaking changes. Following the same established best practice in the SQL Server universe, perform a side-by-side deployment of SQL Server Big Data Clusters to validate your current workload with Spark 3 before upgrading. You can leverage the new azdata HDFS distributed copy capability to have a subset of your data needed to validate this workload. For more information, see the following articles to help you assess your scenario before upgrading to the CU13 release:
- Spark 3 upgrade guide—SQL Server Big Data Clusters
- Migration guide: Spark Core—Spark 3.1.2 documentation
SQL Server Big Data Clusters runtime for Apache Spark release 2021.1
With this release of SQL Server Big Data Clusters, we doubled down on our commitment of release cadence, binary compatibility, and consistency of experiences for data engineers and data scientists through the SQL Server Big Data Clusters runtime for Apache Spark initiative.
The SQL Server Big Data Clusters runtime for Apache Spark is a consistent versioned block of programming language distributions, engine optimizations, core libraries, and packages for Apache Spark.
Here is a summary of the SQL Server Big Data Clusters runtime for Apache Spark release 2021.1 shipped with SQL Server Big Data Clusters CU13:
- Apache Spark 3.1.2
- Scala 2.12 for Scala Spark
- Python 3.8 for PySpark
- Microsoft R Open 3.5.2 for SparkR and sparklyr
For more information on all included packages and how to use it, see:
- SQL Server Big Data Clusters CU13 release notes—SQL Server Big Data Clusters
- Spark library management—SQL Server Big Data Clusters
Password rotation for Big Data Cluster’s Active Directory service accounts
When a big data cluster is deployed with Active Directory integration for security, there are Active Directory (AD) accounts and groups that SQL Server creates during a big data cluster deployment, see auto-generated active directory objects for further information.
When it comes to security-sensitive customers, it is usually required security reinforcement such as setting password expiration policies, allowing the administrator to set user passwords to never expire or expire after a certain number of days. For SQL Server Big Data Cluster deployments it was previously required to manually rotate the password for those auto-generated active directory objects.
With SQL Server Big Data Clusters CU13, we are now releasing the azdata bdc rotate command to rotate passwords for all auto-generated accounts except for the DSA account. In order to update the DSA password for SQL Server Big Data Clusters we are releasing a specific operation notebook.
Enable Advanced Encryption Standard (AES) on the automatically generated AD accounts
Today’s enterprise environments are facing a lot more challenges than it used to be. Using secure and encrypted connections when authenticating with Kerberos will significantly lower the risk to encounter attacks such as Kerberoasting; a type of attack targeting service accounts in Active Directory. Starting with SQL Server Big Data Clusters CU13, we’re enabling the Advanced Encryption Standard (AES) support on the auto-generated AD accounts by allowing users to set an optional boolean parameter in the BDC deployment profile to indicate this AD account supports Kerberos AES 128 bit and 256 bit encryptions.
For more information, see:
- SQL Server Big Data Clusters CU13 release notes—SQL Server Big Data Clusters
- Management notebooks for SQL Server Big Data Clusters—SQL Server Big Data Clusters
Ready to learn more?
Check out the SQL Server Big Data Clusters CU13 release notes to learn more about all the improvements available with the latest update. For a technical deep-dive on Big Data Clusters, read the documentation and visit our GitHub repository.
Follow the instructions on our documentation page to get started and deploy Big Data Clusters.
