
SQL Server 2019 is now generally available
As you saw from our launch announcement earlier today, over a year ago at Microsoft Ignite we announced our first preview of SQL Server 2019 and today our latest release is now generally available.
You have told us that in today’s demanding world of massive data, wide variety of data sources, and expectations of near real-time application and query performance you need more than just a database engine. You need a modern data platform.
SQL Server 2019 encompasses all of this in one product, SQL Server 2019 brings enhancements in the core SQL engine, offers a scale-up and scale-out system with built in support for Big Data (Apache Spark, Data Lake), state of the art data virtualization technology, and with built-in machine learning capabilities.
SQL Server 2019 is designed to solve challenges of the modern data professional including:
- Store enterprise data in a data lake and offer SQL and Spark query capability overall data
- Reduce the need for Extract, Transform, and Load (ETL) applications by eliminating data movement
- Integrate and secure machine learning applications with scalable performance
- Reduce the need for application and query changes to gain a boost in performance
- Increase confidential computing of data through hardware enclaves
- Increase application and database uptime and availability through features like ADR (Advanced Database Recovery)
- Extend the power of the T-SQL language in a secure and robust fashion
- Run applications and deploy databases across multiple operating systems and platforms with compatibility
- Reduce the risk of upgrades while using new SQL capabilities when you are ready though inbuilt database compatibility levels
Unified data platform
Enterprises today use multiple data platforms to meet their business needs. This ranges from operational databases, to data-marts, and to Big Data platforms. These platforms have different security models and tools ecosystems, which often require different skill sets and domain expertise. SQL Server 2019 offers all these capabilities as a unified data platform.
Customers can choose to deploy SQL Server in a traditional pattern. SQL Server 2019 also supports big data cluster deployment that comes with additional capabilities of big data, data virtualization, data-mart and enterprise data lake.
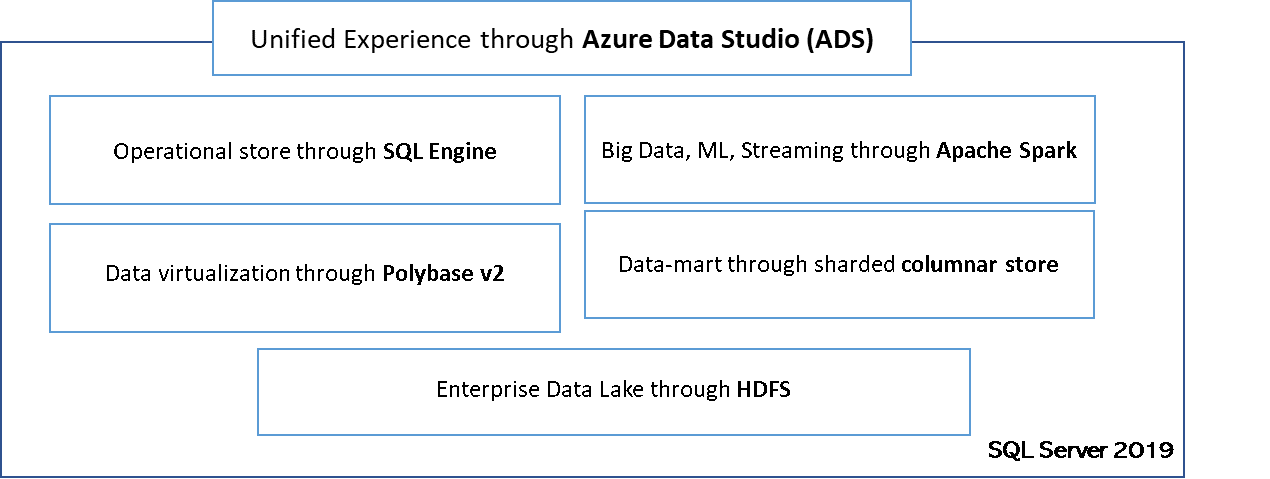
Big Data Clusters come with an easy to use deployment and management experience through the azdata command line tool, or the GUI tool Azure Data Studio. Azure Data Studio is a cross platform, modern tool built on top of VS Code. ADS provides experiences to access Big Data Clusters through interactive dashboards, and also includes rich SQL and Jupyter Notebooks experiences.
Azure Data Studio offers a unified view across all enterprise data both on-premises and in the cloud. You can view all your SQL Servers, data marts, data lakes and any external data sources that you wish to virtualize.
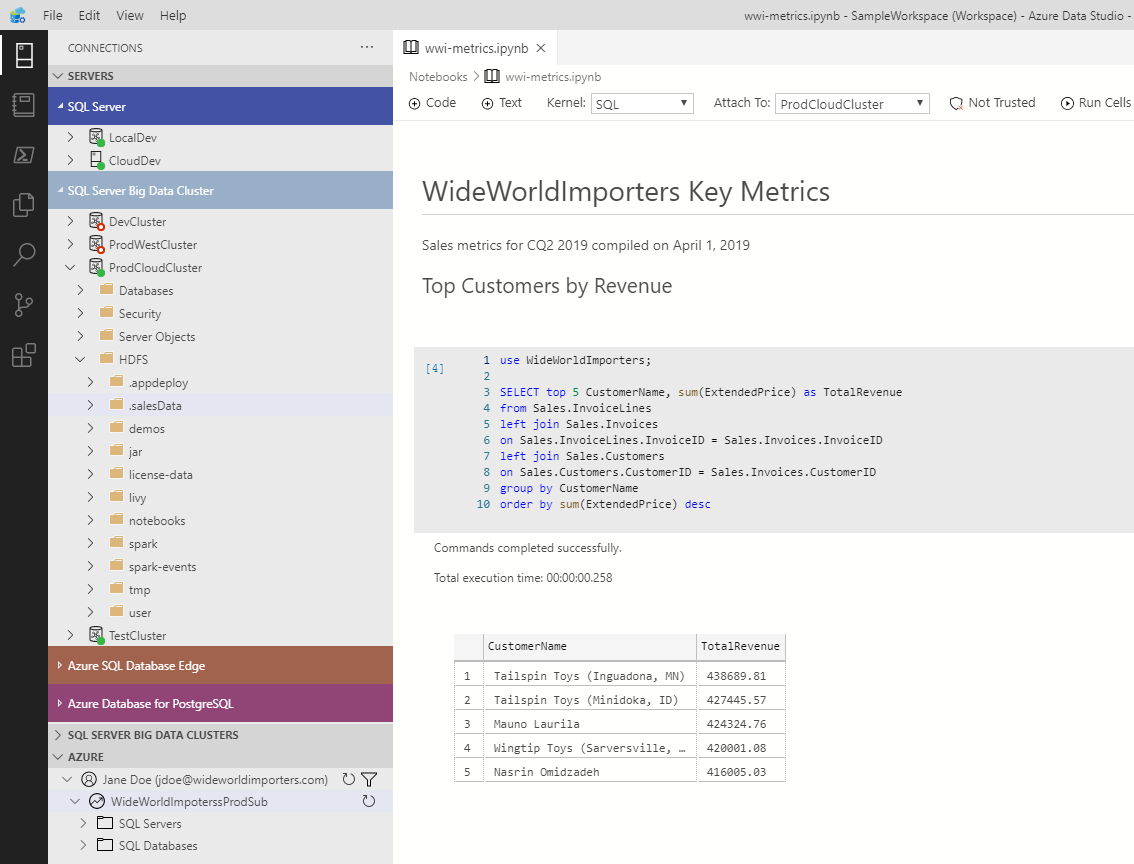
In addition to supporting connections to many data sources, Azure Data Studio has a built-in Jupyter notebook experience. You can use notebooks to access, explore, manipulate, visualize, and model against the built-in Apache Spark experience for SQL Server Big Data Clusters, but what I am most excited about is how we also light up all these capabilities on top of the native SQL Server engine. Using the SQL kernel, you can create rich interactive experiences using T-SQL against any version or edition of SQL Server, on-premises on in the cloud. You can program in Python, SQL, Powershell, Scala, and R. It is such a powerful concept that we have started to convert our documentation, deployment experiences, and troubleshooting manuals into interactive notebooks. We will continue to invest in innovative ways to incorporate this new paradigm into our data experience.
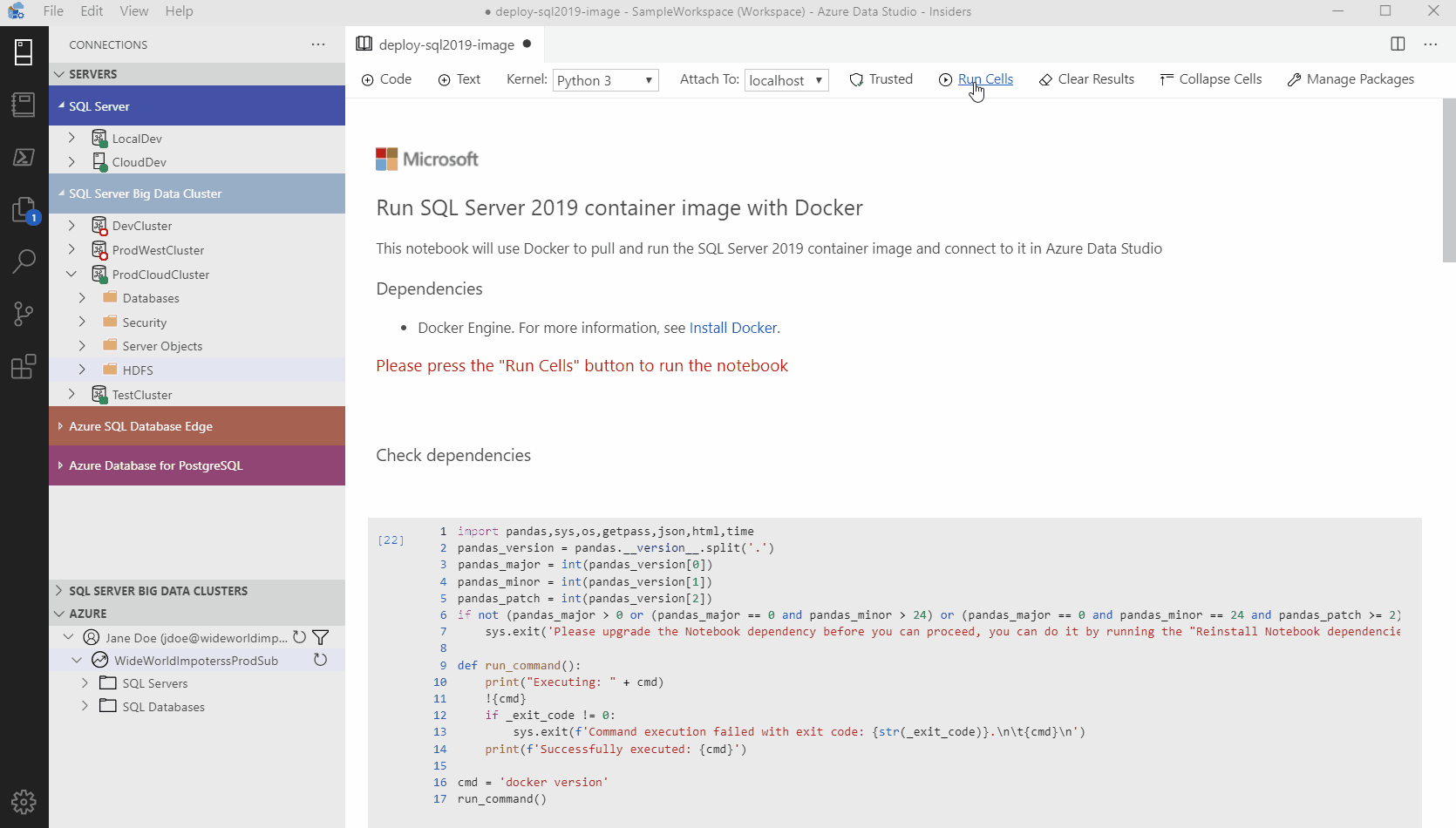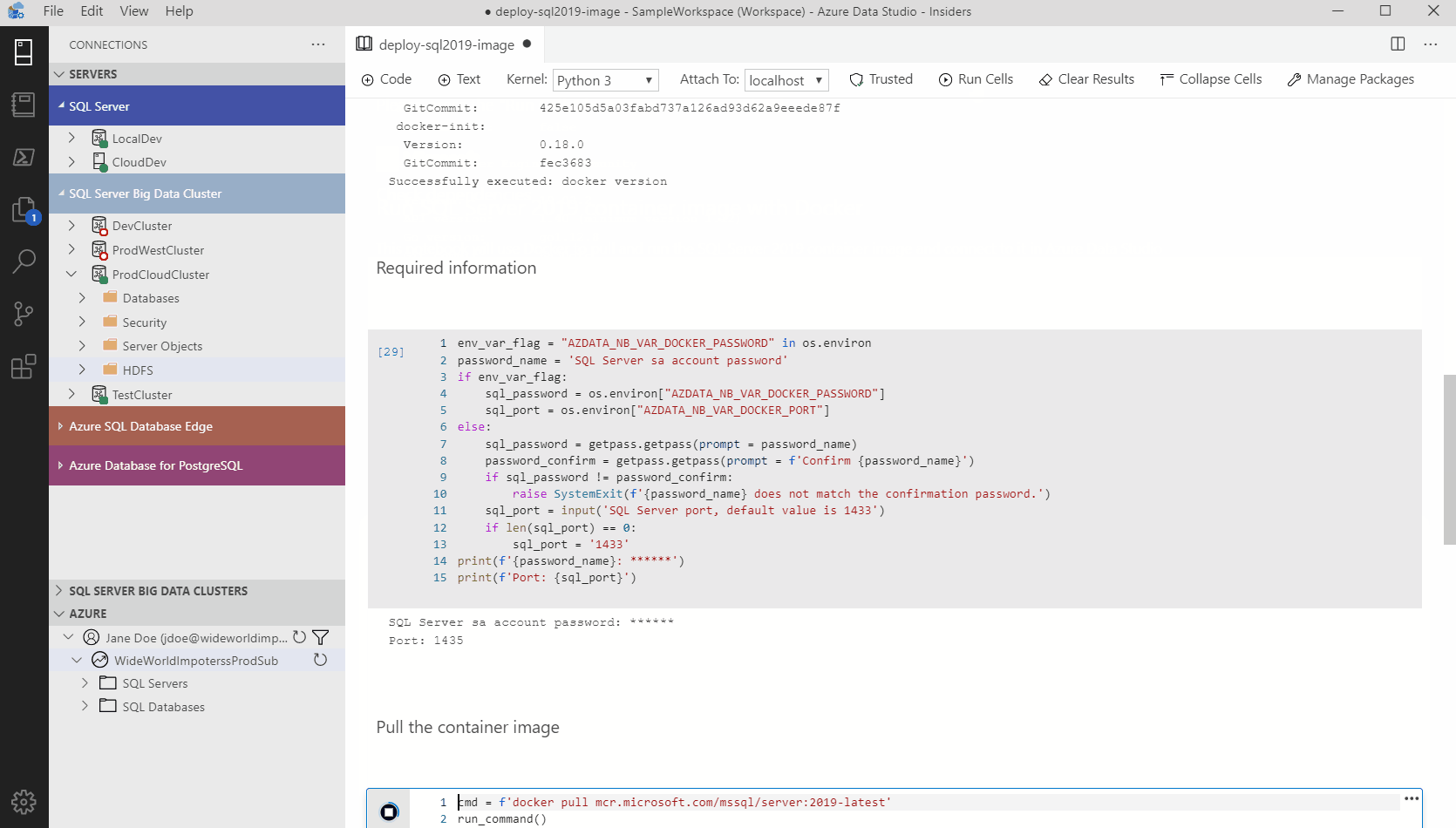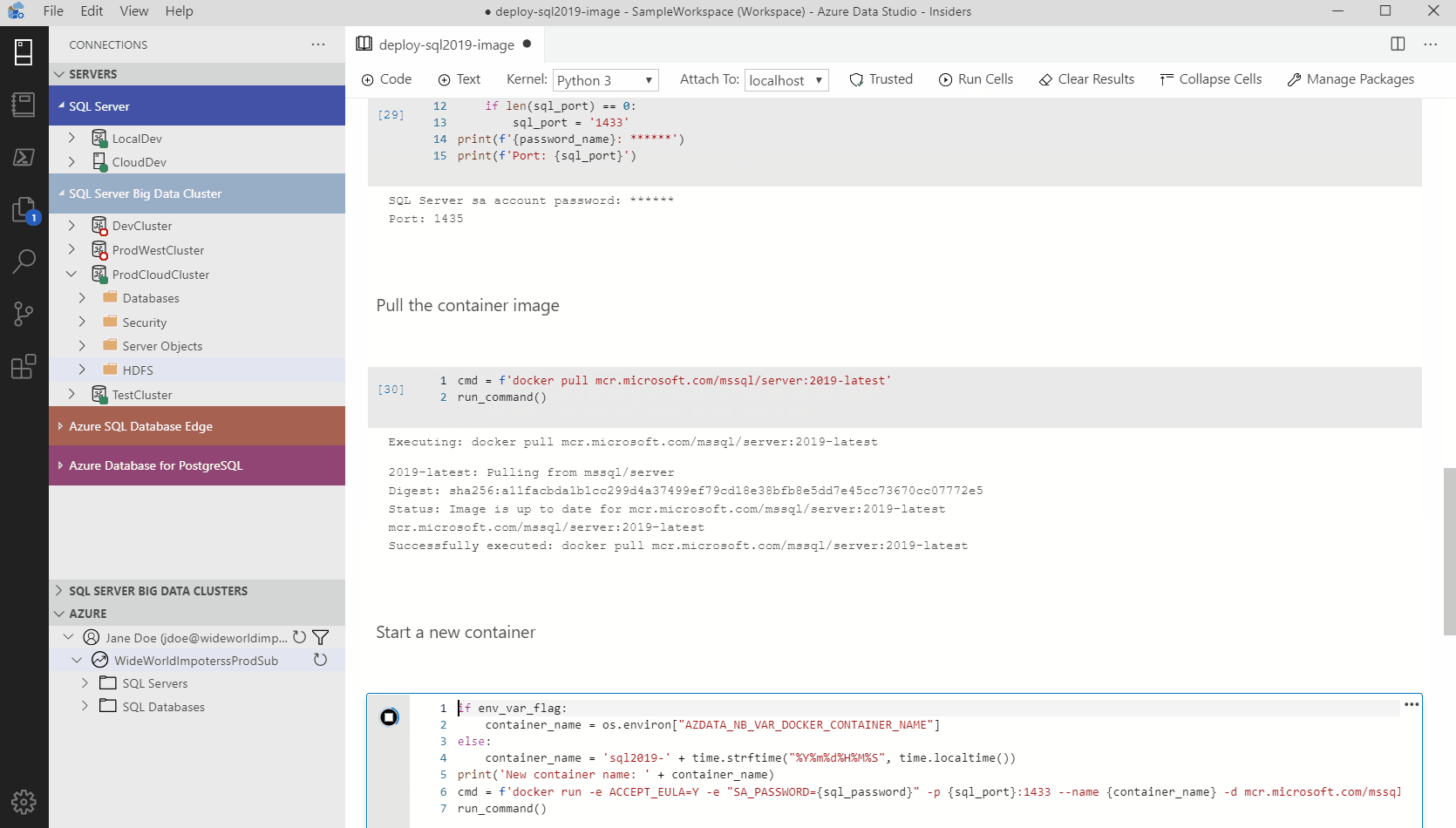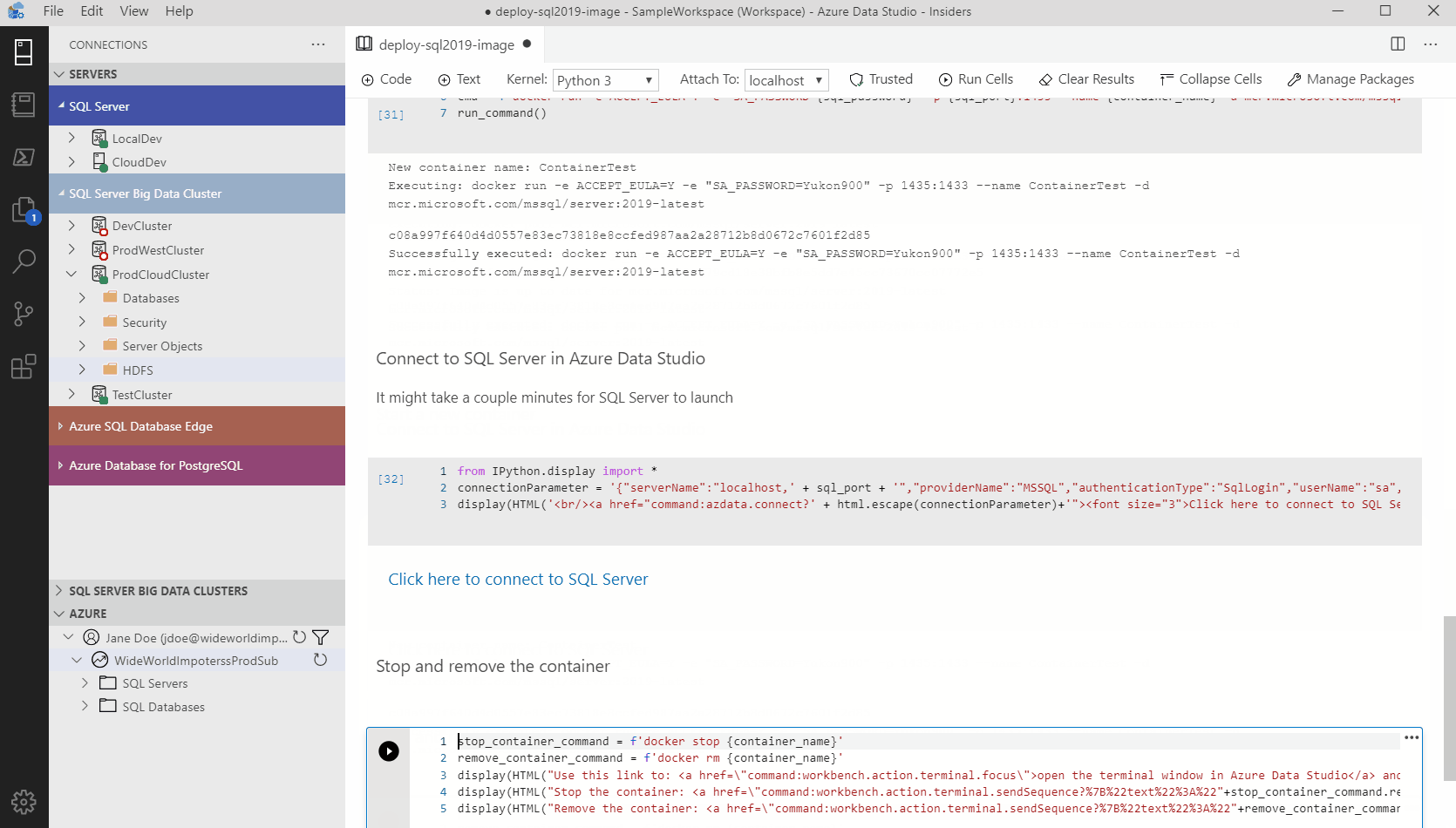
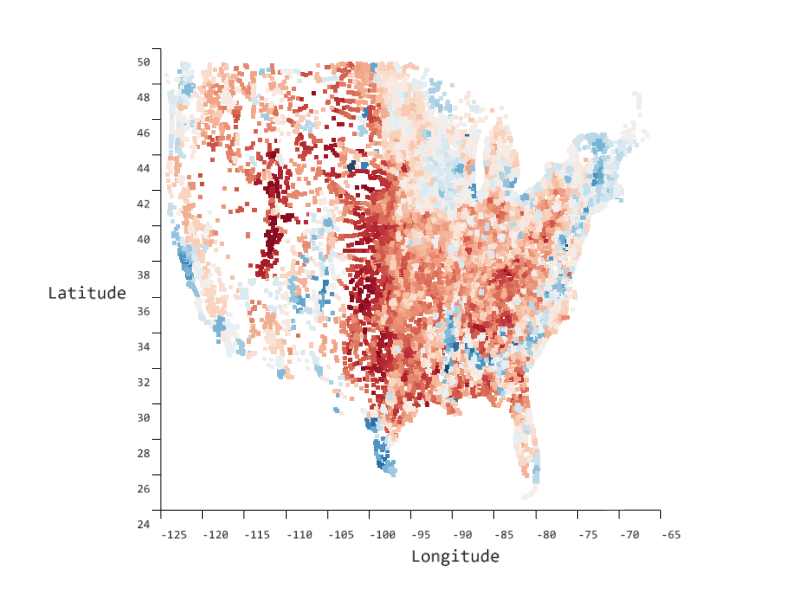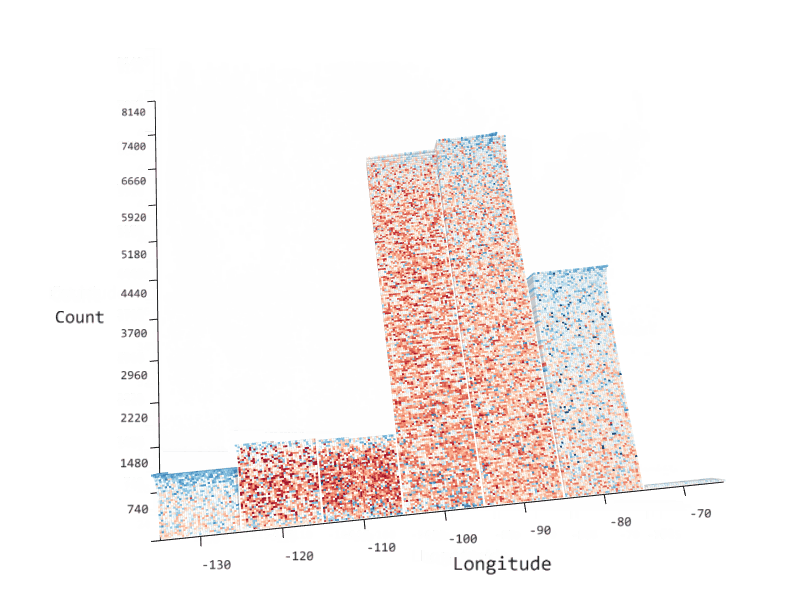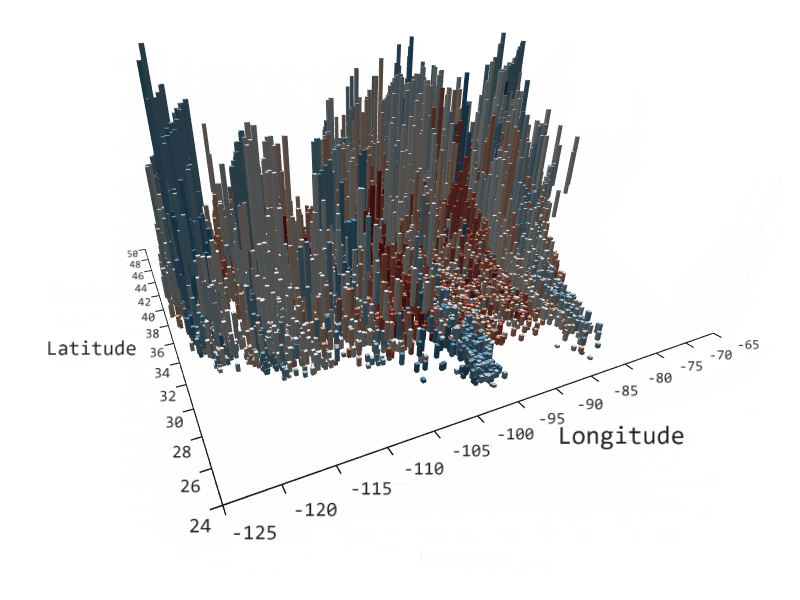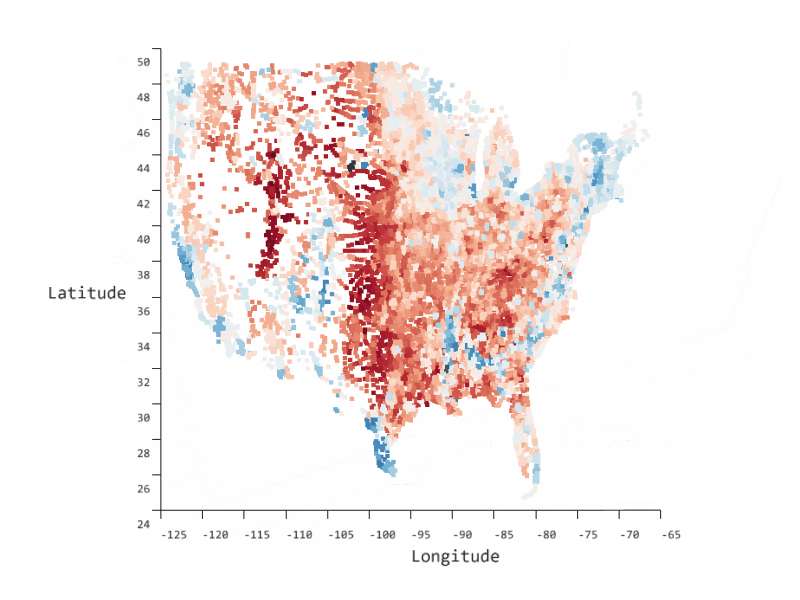
Azure Data Studio comes with many other rich features that make it the most powerful single tool to work across relational databases, data virtualization, big data, and built-in virtualization. Through custom dashboards, intelligent visualizations, and a highly extensible platform, we can continue to bring innovative and modern data experiences into Azure Data Studio such as the SandDance visualizer seen below.
Azure Data Studio is on GitHub so that you can see the innovative progress being made in this evolving tool. To learn more about the capabilities of Azure Data Studio, read our documentation.
Intelligence over all of your data
Enterprises today have data scattered across a variety of platforms and data sources but need to access this data in a consistent manner. This has led to the need to build complex and expensive Extract, Transform, and Load (ETL) applications often moving the data into a central database platform like SQL Server.
SQL Server 2019 has solutions for these challenges by providing data virtualization. Applications and developers can use the familiar and consistent language of T-SQL through external tables to access structured and unstructured data from sources like Oracle, MongoDB, Azure SQL, Teradata, and HDFS. SQL Server 2019 eases the burden of establishing these data sources with built-in driver support. Polybase extends this functionality allowing you to access a host of other data sources using the ODBC driver of your choice. Because external tables act and look like tables you can join data across these sources with local SQL Server tables to provide a seamless experience. In addition, external tables provide some of the same capabilities as local SQL Server tables including using familiar security and object management techniques.
SQL Server 2019 extends the functionality of Polybase by providing a complete analytics platform powered by Big Data Clusters. In addition, a Big Data Cluster deployment includes a Data Pool which can be used to build a data mart of cached results from queries from external tables across or outside the cluster or data directly ingested from sources such as IoT data.
As mentioned earlier, Big Data Clusters come with Apache Spark built-in providing an end-to-end, secure machine learning platform using technologies such as SparkML and SQL Server Machine Learning Services. Data Scientists now have a complete system to train and prepare machine learning models using external table data sources in and outside the cluster. These models can then be deployed and consumed as applications using a RESTful Web Service compliant with Swagger applications.
“Building and deploying our vertical AI-solution for clinical radiology combines very diverse implementation paradigms, data formats and regulatory requirements. SQL Server 2019 big data clusters allowed us to accommodate and integrate all aspects from one shared platform – for our data scientists with their deep learning as well as for our software engineers who wire up workflows, security and scalability. At runtime, our healthcare customers benefit from simple containerized deployment and maintenance while being able to move our solution between on-prem and the cloud easily.” Read more in our Balzano customer story.
René Balzano, Founder and CEO, Balzano
Industry leading intelligent performance
SQL Server provides one of the most powerful query engines proven with industry leading benchmarks. Today new TPC benchmarks have been announced continuing to prove SQL Server has unparalleled performance in the industry.
Developers and data professionals need more. They need a database engine that can adapt to their query workloads and reduce time for expensing performance tuning. Users expect to migrate to the latest release of SQL Server and gain performance without having to make major application changes. When they have to analyze query performance they need deep insights anytime and anywhere.
We recently performed a performance test on a SQL Server 2019 instance running on a Windows Server 2016 running on an 8-Socket (224 cores, 12TB RAM and 200TB+ SSD storage) Lenovo Server (ThinkSystem SR950) using Intel Cascade Lake processors. We generated data and loaded a single table (LINEITEM, TPCH database schema with 145TB+ raw data). This table had 54TB compressed data with 1 Trillion+ rows. Q1 query (as defined by TPCH) which scans the whole table and selects nearly all the rows for computation was run in both cold (all data read from storage) and warm (data in memory) scenario. SQL Server 2019 was able to provide unparalleled performance processing over a trillion rows with the query completing in under 2 mins (107 secs) in warm cache and under 4 mins (238 secs) with all data read from storage. For the warm cache, this translates to processing over 6 billion rows/sec and read throughput of around 50GB/sec. You can find the Azure Data Studio Notebooks that showcase both scenarios on GitHub.
SQL Server 2019 includes built-in query processing capabilities called Intelligent Query Processing. By updating your database compatibility level to 150 (the default level for SQL Server 2019), the query processor in the SQL Server engine can enhance performance through capabilities like batch-mode on row store, scalar UDF inlining,or table variable deferred compilation. It can automatically correct memory-related query execution issues through memory grant feedback. No query or application changes are required for a boost in performance.
SQL Server also provides optimized in-memory capabilities without changing your application through the support of persistent memory and optimized tempdb metadata access. Tempdb now just runs faster.
Because in some situations you need immediate access to query performance insights, SQL Server 2019 enables lightweight query profiling by default including the ability to access the last actual query execution plan. For deeper insights over time, enable the query store and enable historical query plan performance analysis including the ability to have SQL Server automatically correct query plan regressions.
A list of all the performance improvements in SQL Server 2019 is available.
Mission critical security and availability
A modern data platform must provide confidential computing through software that does not expose vulnerabilities and features to secure your data. SQL Server 2019 for the last 9 years has been the least vulnerable database product in the industry according to NIST (National Institute of Standards and Technology Comprehensive Vulnerability Database).
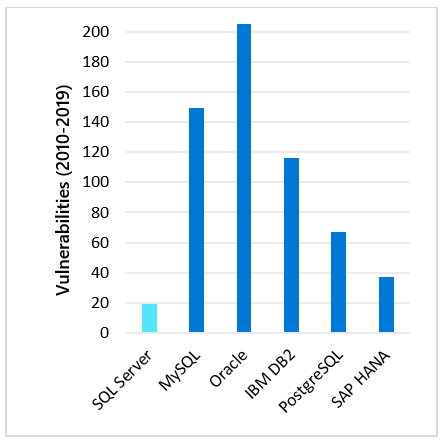
Built on the foundation of security capabilities like row-level security and dynamic data masking, SQL Server 2019 provides features that meet the security needs of modern applications through always encrypted with secure enclaves. Enclaves allow for data to be only available in an unencrypted state in the enclave memory space on the server. This provides control over the unencrypted data while enabling rich query computing and indexing. SQL Server 2019 also provides a new T-SQL interface to classify your data assisting you to meet compliance standards such as GDPR. Because classification is now built into the engine, SQL Server audit can be used to track users who access classified data.
Keeping your data available at all times is critical to any data application. Data professionals for years have struggled with managing transaction log growth and application availability due to long running or long open active transactions. SQL Server 2019 now provides accelerated database recovery to overcome these challenges with no application changes required. Using a database option, SQL Server will use a Persisted Version Store to track changes allowing for rollback and undo recovery to execute faster than it takes to observe changes. Transaction log truncation is no longer dependent on active transactions. Accelerated database recovery is based on the work done for Azure SQL Database (read the whitepaper on the topic recently presented at the VLDB 2019 conference) and is one of the key technologies behind the amazing performance of Hyperscale in Azure.
Platform and language of choice with compatibility
SQL Server rocked the industry by bringing SQL Server to Linux with SQL Server 2017. Using the innovative technology of the SQLPAL, SQL Server on Linux has application and database compatibility with Windows. Backup a database on Windows and restore it on Linux with no application changes. SQL Server 2019 continues the Linux journey by offering new capabilities such as Replication, Distributed Transactions, Polybase, and Machine Learning Services.
Because SQL Server has embraced Linux, the community has already seen the benefits of using SQL Server containers including simplified software patching, consistency, and easy integration into Continuous Integration/Continuous Deployment (CI/CD) pipelines. Customers now see the benefit of using SQL Server with containers in production. SQL Server 2019 embraces this need by offering containers based on Red Hat Enterprise Linux images and running by default as non-root. This enables SQL Server containers to be officially supported on the popular Kubernetes platform RedHat OpenShift.
Developers also need to use the language of their choice with a compatible data platform. SQL Server supports a variety of popular languages and providers such as C#, Java, node.js, PHP, Ruby, and Go. In addition, SQL Server 2019 also allows developers to extend the T-SQL language through Java classes with SQL Server Language Extensions using the extensibility framework, the same architecture that powers SQL Server Machine Learning Services.
The voice of the customer
Everything poured into SQL Server is based on customer experiences. Listening to our customers is the only way to provide solutions that meet real-world challenges. SQL Server 2019 addresses key customer feedback areas such as:
- Improved context for errors such as string truncation
- New diagnostics for supportability
- Query store enhancements
- Deep engine performance improvements.
Read about all the SQL Server 2019 improvements in our documentation.
