Research talk: Large-scale, self-supervised pretraining: From language to vision
Over the past years, large-scale pretrained models with billions of parameters have improved the state of the art in nearly every natural language processing (NLP) task. These models are fundamentally changing the research and development of NLP and AI in general. Recently, researchers are expanding such models beyond natural language texts to include more modalities, such as structured knowledge bases, images, and videos. With this background, the talks in this session are expected to introduce the latest advances in pretrained models, and also discuss the future of this research frontier. Hear from Li Dong (Microsoft Research Asia), in the first of three talks on recent advances and applications of language model pertaining.
Learn more about the 2021 Microsoft Research Summit: https://Aka.ms/researchsummit (opens in new tab)
- Track:
- Deep Learning & Large-Scale AI
- Date:
- Speakers:
- Li Dong, Furu Wei
- Affiliation:
- Microsoft Research, Microsoft Research Asia
Deep Learning & Large-Scale AI
-
-
-
Research talk: Resource-efficient learning for large pretrained models
Speakers:- Subhabrata (Subho) Mukherjee
-
-
-

Research talk: Prompt tuning: What works and what's next
Speakers:- Danqi Chen
-
-
-
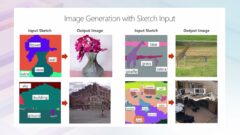
Research talk: NUWA: Neural visual world creation with multimodal pretraining
Speakers:- Lei Ji,
- Chenfei Wu
-
-
-
-

Research talk: Towards Self-Learning End-to-end Dialog Systems
Speakers:- Baolin Peng
-

Research talk: WebQA: Multihop and multimodal
Speakers:- Yonatan Bisk
-

Research talk: Closing the loop in natural language interfaces to relational databases
Speakers:- Dragomir Radev
-

Roundtable discussion: Beyond language models: Knowledge, multiple modalities, and more
Speakers:- Yonatan Bisk,
- Daniel McDuff,
- Dragomir Radev
-