
Policy Gradient Methods: Tutorial and New Frontiers
In this tutorial we discuss several recent advances in deep reinforcement learning involving policy gradient methods. These methods have shown significant success in a wide range of domains, including continuous-action domains such as manipulation, locomotion, and flight. They have also achieved the state of the art in discrete action domains such as Atari. We will provide a unifying overview of a variety of different policy gradient methods, and we will also discuss the formalism of stochastic computation graphs for computing gradients of expectations.
- Séries:
- Cambridge Lab PhD Summer School
- Date:
- Haut-parleurs:
- John Schulman
- Affiliation:
- UC Berkeley
-
-

Scarlet Schwiderski-Grosche
Director
-
-
Taille: Cambridge Lab PhD Summer School
-
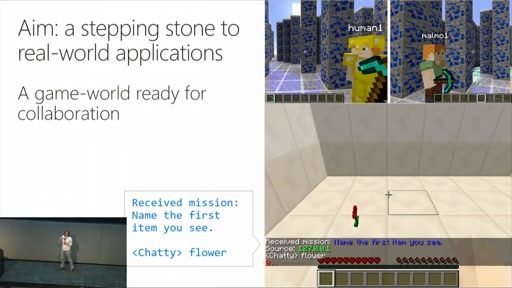
The Malmo Collaborative AI Challenge
Speakers:- Scarlet Schwiderski-Grosche
-
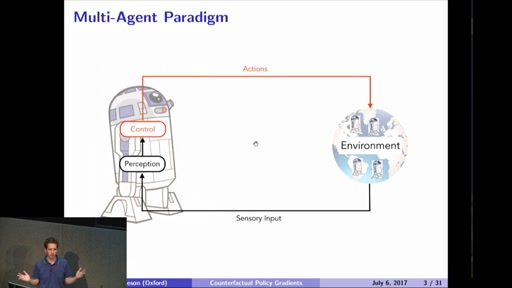
Counterfactual Multi-Agent Policy Gradients
Speakers:- Scarlet Schwiderski-Grosche
-
Design - On the Human Side
Speakers:- Alex Taylor,
- Scarlet Schwiderski-Grosche
-

Probabilistic Machine Learning and AI
Speakers:- Scarlet Schwiderski-Grosche
-

Policy Gradient Methods: Tutorial and New Frontiers
Speakers:- Scarlet Schwiderski-Grosche
-

Strategic Thinking for Researchers
Speakers:- Andy Gordon,
- Jeff Running
-

How to Write a Great Research Paper
Speakers:- Scarlet Schwiderski-Grosche,
- Simon Peyton Jones
-

Project Malmo – a platform for fundamental AI research
Speakers:- Scarlet Schwiderski-Grosche
-

No Compromises: Distributed Transactions with Consistency, Availability, and Performance
Speakers:- Scarlet Schwiderski-Grosche
-

The Evolution of Innovation
Speakers:- Scarlet Schwiderski-Grosche
-

How to Give a Great Research Talk
Speakers:- Scarlet Schwiderski-Grosche,
- Simon Peyton Jones