
Counterfactual Multi-Agent Policy Gradients
Many real-world problems, such as network packet routing and the coordination of autonomous vehicles, are naturally modelled as cooperative multi-agent systems. In this talk, I overview some of the key challenges in developing reinforcement learning methods that can efficiently learn decentralised policies for such systems. I also propose a new multi-agent actor-critic method called counterfactual multi-agent (COMA) policy gradients. COMA uses a centralised critic to estimate the Q-function and decentralised actors to optimise the agents’ policies. In addition, to address the challenges of multi-agent credit assignment, it uses a counterfactual baseline that marginalises out a single agent’s action, while keeping the other agents’ actions fixed. COMA also uses a critic representation that allows the counterfactual baseline to be computed efficiently in a single forward pass. Finally, I present results evaluating COMA in the testbed of StarCraft unit micromanagement.
- Séries:
- Cambridge Lab PhD Summer School
- Date:
- Haut-parleurs:
- Shimon Whiteson
- Affiliation:
- University of Oxford
-
-

Scarlet Schwiderski-Grosche
Director
-
-
Taille: Cambridge Lab PhD Summer School
-
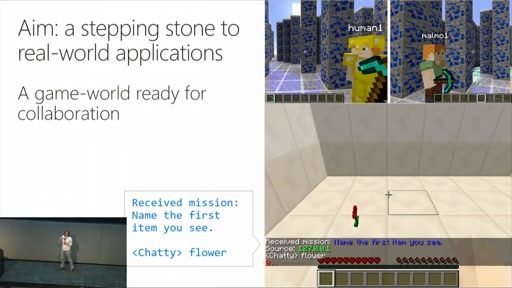
The Malmo Collaborative AI Challenge
Speakers:- Scarlet Schwiderski-Grosche
-
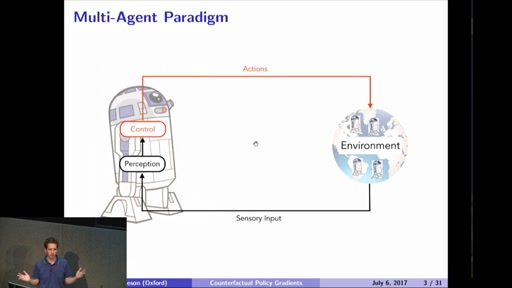
Counterfactual Multi-Agent Policy Gradients
Speakers:- Scarlet Schwiderski-Grosche
-
Design - On the Human Side
Speakers:- Alex Taylor,
- Scarlet Schwiderski-Grosche
-

Probabilistic Machine Learning and AI
Speakers:- Scarlet Schwiderski-Grosche
-

Policy Gradient Methods: Tutorial and New Frontiers
Speakers:- Scarlet Schwiderski-Grosche
-

Strategic Thinking for Researchers
Speakers:- Andy Gordon,
- Jeff Running
-

How to Write a Great Research Paper
Speakers:- Scarlet Schwiderski-Grosche,
- Simon Peyton Jones
-

Project Malmo – a platform for fundamental AI research
Speakers:- Scarlet Schwiderski-Grosche
-

No Compromises: Distributed Transactions with Consistency, Availability, and Performance
Speakers:- Scarlet Schwiderski-Grosche
-

The Evolution of Innovation
Speakers:- Scarlet Schwiderski-Grosche
-

How to Give a Great Research Talk
Speakers:- Scarlet Schwiderski-Grosche,
- Simon Peyton Jones