
Generative Kaleidoscopic Networks
‘Dataset Kaleidoscope’: We discovered that the Deep ReLU networks (or Multilayer Perceptron architecture) demonstrate an ‘over-generalization’ phenomenon. In other words, the MLP learns a many-to-one mapping and this effect is more prominent as we increase the number of layers or depth of the MLP. We utilize this property of neural networks to design a dataset kaleidoscope, termed as ‘Generative Kaleidoscopic Networks’.
‘Kaleidoscopic Sampling’: If we learn a MLP to map from input to itself, f(x)->x, the sampling procedure starts with a random input noise (z) and recursively applies f(…f(z)…). After a burn-in period duration, we start observing samples from the input distribution and we found that deeper the MLP, higher is the quality of samples recovered.
Software & demo: Generative Kaleidoscopic Networks (opens in new tab)
Additional discussions: Microsoft highlight (opens in new tab), Tech Blog (opens in new tab)

Manifold learning & Kaleidoscopic sampling: [left] During the manifold learning process, the Multilayer Perceptron (MLP) weights have their gradients enabled, shaded in blue, and have their output units bounded. [right] During the sampling process, the weights of the neural network model are frozen and the input is a randomly sampled from a normal or a uniform distribution. The model f is repeatedly applied to the input noise f(…f(z)…) and post the burn-in period we start obtaining the samples closer to the input data distribution.
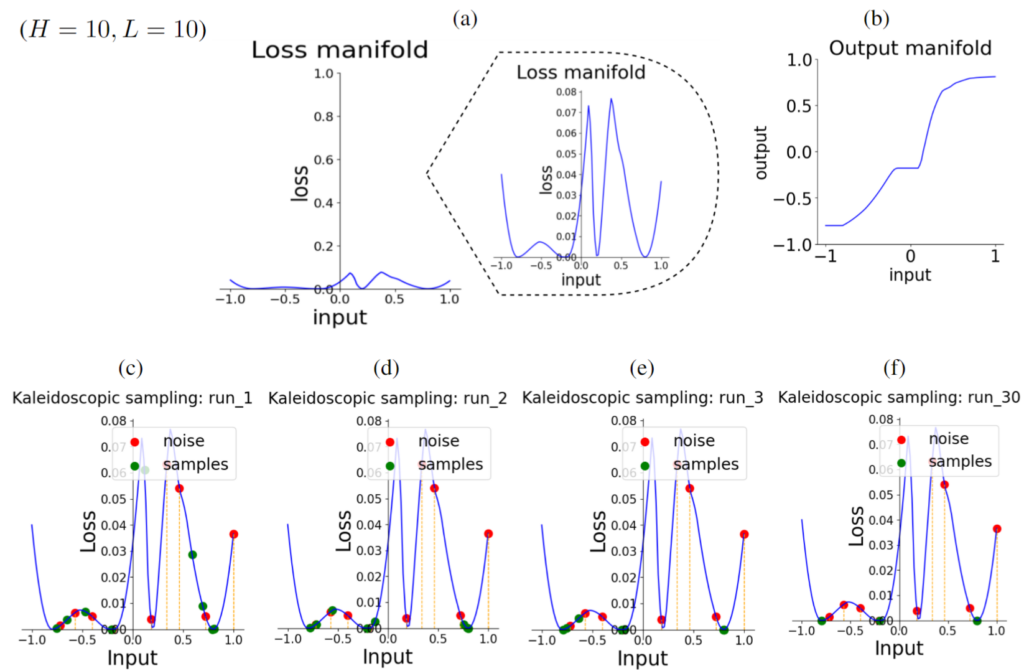
Points in 1D space with NN bounded by `Tanh’: Manifold learning done on data points X={-0.8, -0.2, 0.2, 0.8} by fitting a MLP with H=10,L=10 and the final layer non-linearity as `Tanh’. The rows (c-f) shows intermediate instances of the sampling runs. We can observe the over-generalization phenomenon in (b), where the MLP learns many-to-one mapping, as evident by the flat regions around the points X.

Generative Kaleidoscopic Network for MNIST: Manifold learning done using a deep ReLU network. [TOP row] The leftmost images show the digits recovered after the manifold learning. The center images show the first run after applying learned MLP on the input noise. The input noise vector was sampled randomly from a Uniform distribution. The rightmost images show the state at the sampling run of 300. The procedure shows kaleidoscopic effect until eventually it converges at a digit and then it can remain stable throughout the future iterations as it has found a stable minima. Here, we show the output of randomly chosen subset of images and the seed is constant, so that there is one-to-one correspondence across sampling runs. [MIDDLE row] A sequence of intermediate sampling runs 5 to13, which is still in the burn-in period. One can take a digit and observe their evolution over the iterations. For instance, top row & third last column evolves into digit 8 and then eventually transforms into the digit 6 at the 300th iteration. [BOTTOM row] Shows another sequence of evolution of sevens from noise.
 GitHub
GitHub