
Arena Learning: Build Data Flywheel for LLMs Post-training via Simulated Chatbot Arena
- Haipeng Luo ,
- Qingfeng Sun ,
- Can Xu ,
- Pu Zhao ,
- Qingwei Lin 林庆维 ,
- Jianguang Lou ,
- Shifeng Chen ,
- Yansong Tang ,
- Weizhu Chen
Preprint

Assessing the effectiveness of large language models (LLMs) presents significant challenges. The method of conducting human-annotated battles in an online Chatbot Arena has been recognized as a highly effective evaluative approach. However, this process is hindered by the costliness and time demands of human annotation, complicating the enhancement of LLMs via post-training. In this paper, we introduce ”Arena Learning”, an innovative offline strategy designed to simulate these arena battles. We have developed a comprehensive set of instructions for simulated battles and employ AI-driven annotations to assess battle outcomes, facilitating continuous improvement of the target model through both supervised fine-tuning and reinforcement learning. A crucial aspect of our methodology is ensuring precise evaluations and achieving consistency between offline simulations and online competitions. To this end, we present WizardArena, a pipeline crafted to accurately predict the Elo rankings of various models using a meticulously designed offline test set. Our findings indicate that WizardArena’s predictions are closely aligned with those from the online Arena. We apply this novel framework to train our model, WizardLM-β, which demonstrates significant performance enhancements across various metrics. This fully automated training and evaluation pipeline paves the way for ongoing, incremental advancements in various LLMs via post-training. Notably, Arena Learning plays a pivotal role in the success of WizardLM-2, and this paper serves both as an exploration of its efficacy and a foundational study for upcoming discussions related to WizardLM-2 and its derivatives.
Introduction
With the rapid implementation of various large model applications and the reduction of inference costs, the interest and demand from businesses and consumers in using large language model services have increased rapidly. At the same time, with the innovation and deepening of application scenarios, this requires those models to continue to evolve to adapt to the user’s new intentions and instructions. Therefore, building an efficient data flywheel to continuously collect feedback and improve model capabilities has become a key direction for next generation AI research.
The emergence of the LMSYS Chatbot Arena has been a significant development. This is a platform that facilitates the assessment and comparison of different chatbot models by pitting them against each other in a series of conversational challenges and rank with Elo rating system. However, the human-based evaluation process poses its own challenges: Manually orchestrating and waiting the interactions between chatbots and human evaluators can be time-consuming and resource-intensive, limiting the scale and frequency of evaluation and training data opensource cycles. On the other hand, due to their priority limitations, most models are unable to participate in arena evaluations, and the community can only obtain 10% of the chat data at most, making it hard to directly and efficiently guide the development of the target model based on this Arena. Therefore, the need for a more efficient and scalable arena-based pipeline to chatbot post-training and evaluation has become increasingly pressing.
To address these challenges, this paper introduces a novel approach called Arena Learning, which is a training and evaluation pipeline fully based on and powered by AI LLMs without human evaluators. The primary objective of Arena Learning is to build an efficient data flywheel and mitigate the manual and temporal costs associated with post-training LLMs while retaining the benefits of arena-based evaluation and training. As the running example shown in the Figure 1, the key is that Arena Learning simulates a offline chatbot arena, and can efficiently predict accurate performance rankings among different arena battle models based on a powerful “judge model”, which could automatically imitate the manner of human annotators in judging a responses pair of two models and provide rankings, scores, and explanation.
 Approach Overview
Approach Overview
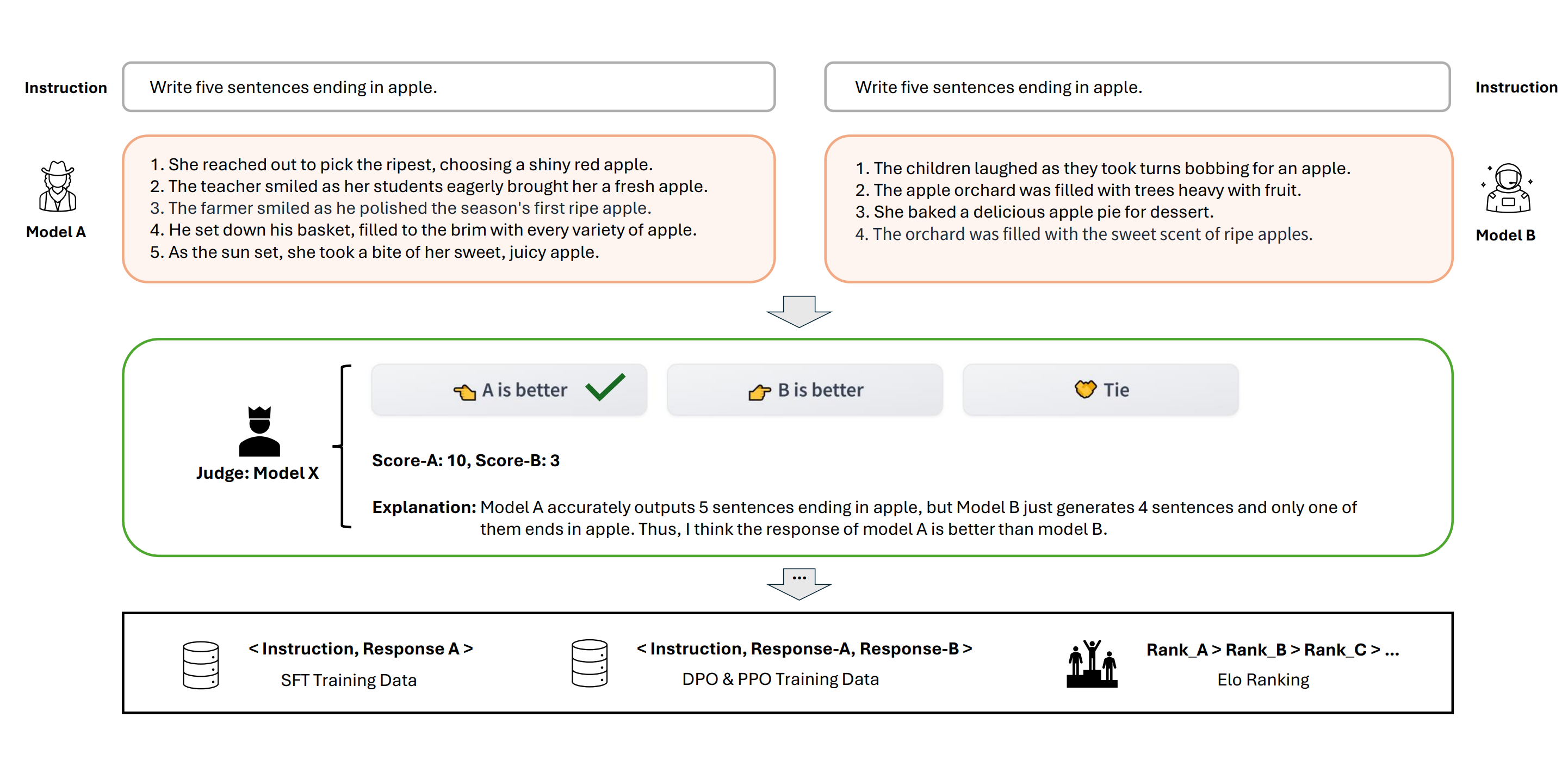
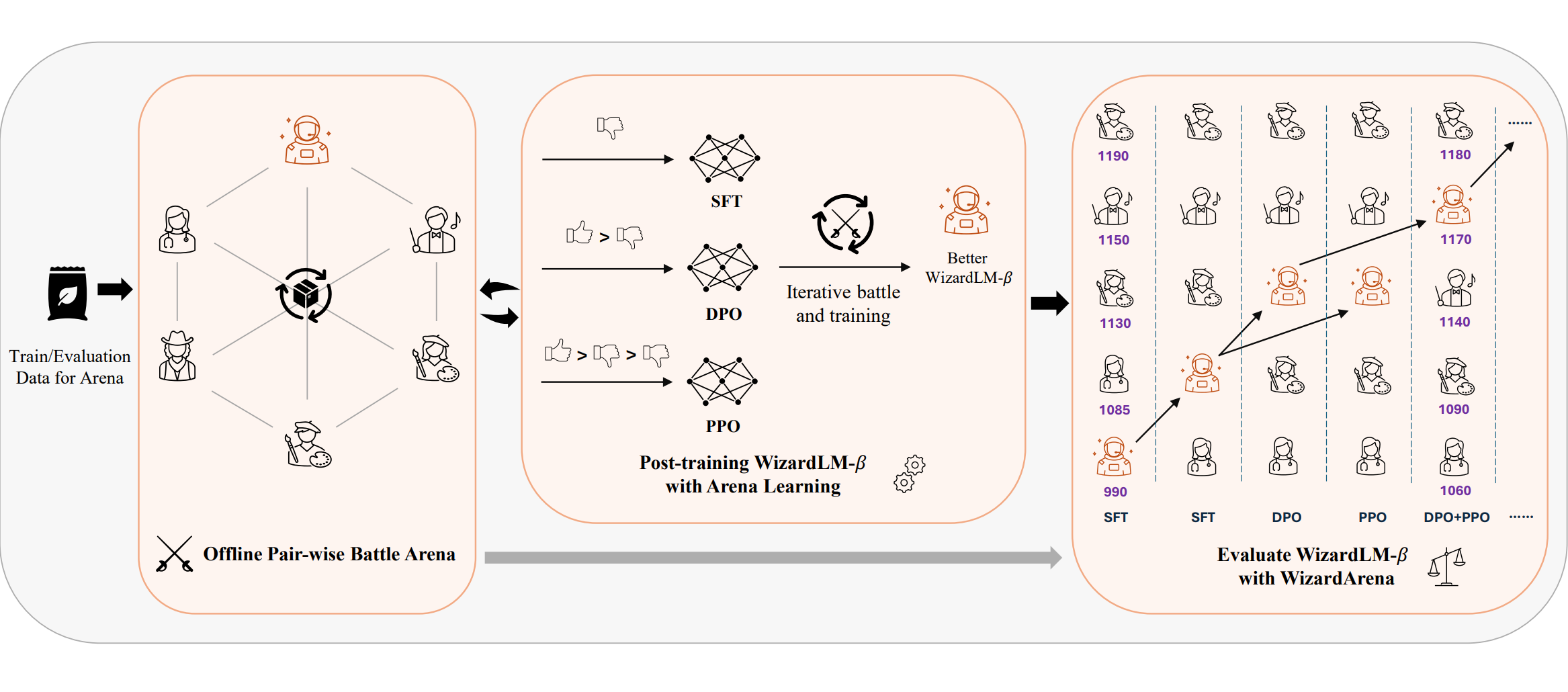
In the post-training scenario, Arena Learning simulates battles among target model (referred to as WizardLM-β) and various state-of-the-art models on a large scale of instruction data. These synthetic battle results are then used to enhance WizardLM-β through some training strategies, including supervised fine-tuning (SFT), direct preference optimization (DPO), and proximal policy optimization (PPO), enabling it to learn from the strengths and weaknesses of other good models. Furthermore, Arena Learning introduces an iterative battle and training process, where the WizardLM-β is continuously updated and re-evaluated against SOTA models. This allows for the WizardLM-β to iteratively improve and adapt to the evolving landscape of the arena, ensuring that it remains competitive and up-to-date with the latest top-tier competitors in the field.
Build a Data Flywheel to Post-train LLMs
Collect Large-Scale Instruction Data
To facilitate leveraging the simulated arena battles among models to train WizardLM-β, Arena Learning relies on a large-scale corpus of conversational data D. The data collection process involves several stages of filtering, cleaning, and deduplication to ensure the quality and diversity of the instruction data. The simulated arena battle outcomes are then used to generate training data for the WizardLM-β, tailored to different training strategies: supervised fine-tuning (SFT), direct preference optimization (DPO), and proximal policy optimization (PPO). We split the data equally into some parts D = {D_0, D_1, D_2, …, D_N} for following iterative training and updates respectively.
Iterative Battle and Model Evolving
Arena Learning employs an iterative process for training and improving the WizardLM-β. After each round of simulated arena battles and training data generation, the WizardLM-β is updated using the appropriate training strategies (SFT, DPO, and/or PPO). This updated model is then re-introduced into the arena, where it battles against the other SOTA models once again. This iterative process allows the WizardLM-β to continuously improve and adapt to the evolving landscape of the arena. As the model becomes stronger, the simulated battles become more challenging, forcing the WizardLM-β to push its boundaries and learn from the latest strategies and capabilities exhibited by the other models. Additionally, the iterative nature of Arena Learning enables the researchers to monitor the progress and performance of the WizardLM-β over time, providing valuable insights into the effectiveness of the different training strategies and potential areas for further improvement or refinement.
Evaluate LLMs with WizardArena
In the evaluation scenario, we firstly contribute a carefully prepared offline testset – WizardArena, it effectively balances the diversity and complexity of evaluation. By automating the pair judgement process with “judge model”, WizardArena significantly reducing the associated costs and priority limitations, and could produce the Elo rankings and detailed win/loss/tie statistics.
3. Experiments Overview
3.1 Offline WizardArena closely align with the Online LMSYS ChatBot Arena.

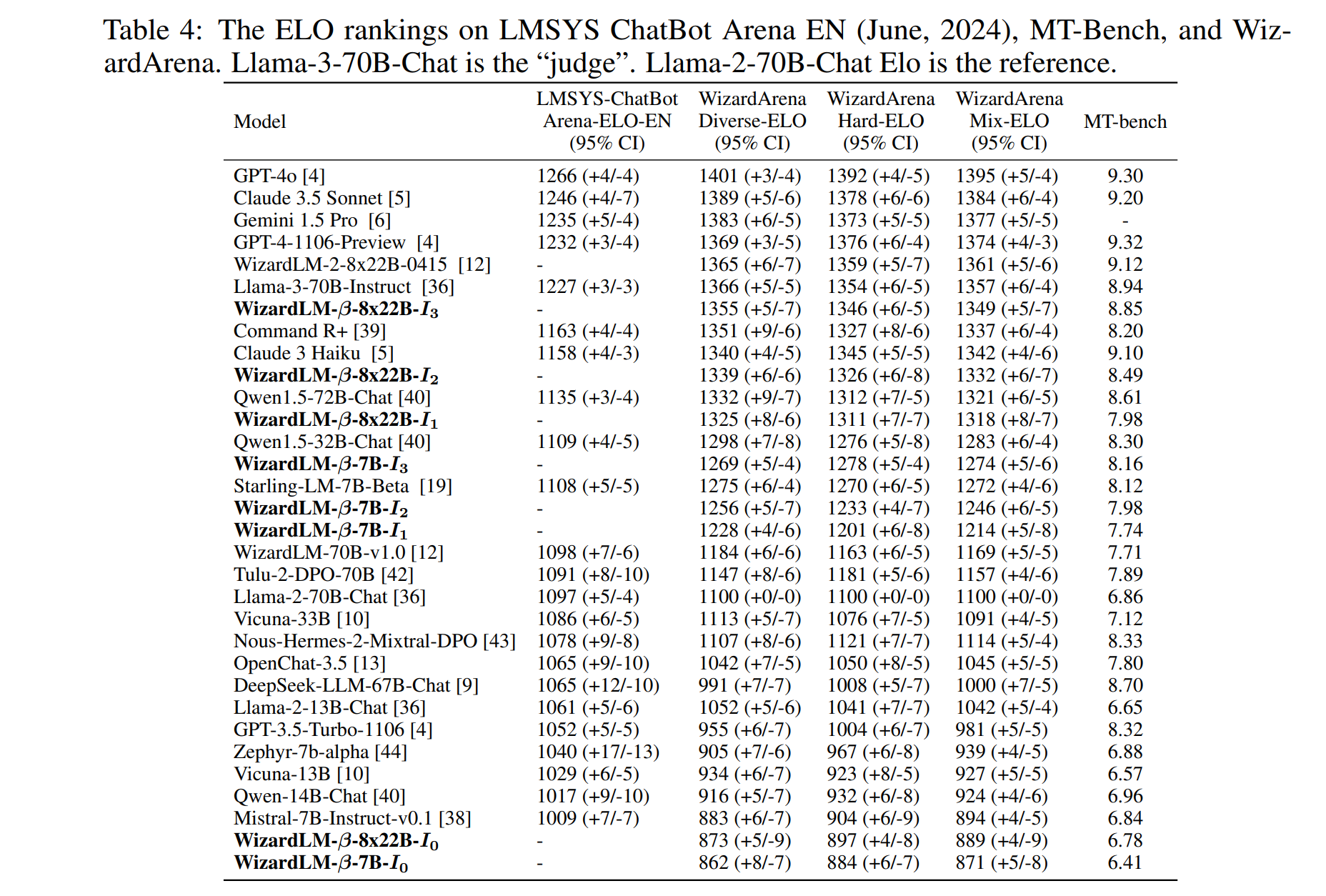
Figure 6 reveals that employing the LMSYS ChatBot Arena as the reference benchmark in the real-world scenarios, WizardArena displays the good ranking consistency, however MT-Bench shows the large fluctuations. Table 3 also illustrates that the Offline WizardArena-Mix significantly outperforms MT-Bench across several consistent metrics: a 19.87% higher Spearman Correlation, a 73.07% increase in Human Agreement with 95% CI, and a 74.57% improvement in Differentiation with 95% CI. It achieves an average consistency of 98.79% with the LMSYS ChatBot Arena by human judgment, outperforming Arena-Hard-v1.0 by 8.58% and MT-Bench by 55.84%. In contrast to MT-Bench and Arena-Hard-v1.0 which use proprietary models (i.e. GPT-4) as the judge model, our approach employs current SOTA open-source model Llama-3-70B-Chat, which not only has a significantly lower cost but also achieves strong consistency. Moreover, the Offline WizardArena-Mix, which integrates both Diverse and Hard test sets, achieves 0.87% higher average consistency compared to WizardArena-Diverse and 0.82% higher than WizardArena-Hard. This indicates that balancing diversity and complexity is crucial for the effective offline evaluation of large language models. Above results also further prove the feasibility of using the “judge” model to judge the battles between LLMs and generate a large amount of post-training data in simulated arena.
3.2 Can Arena Learning build an effective data flywheel with post-training?
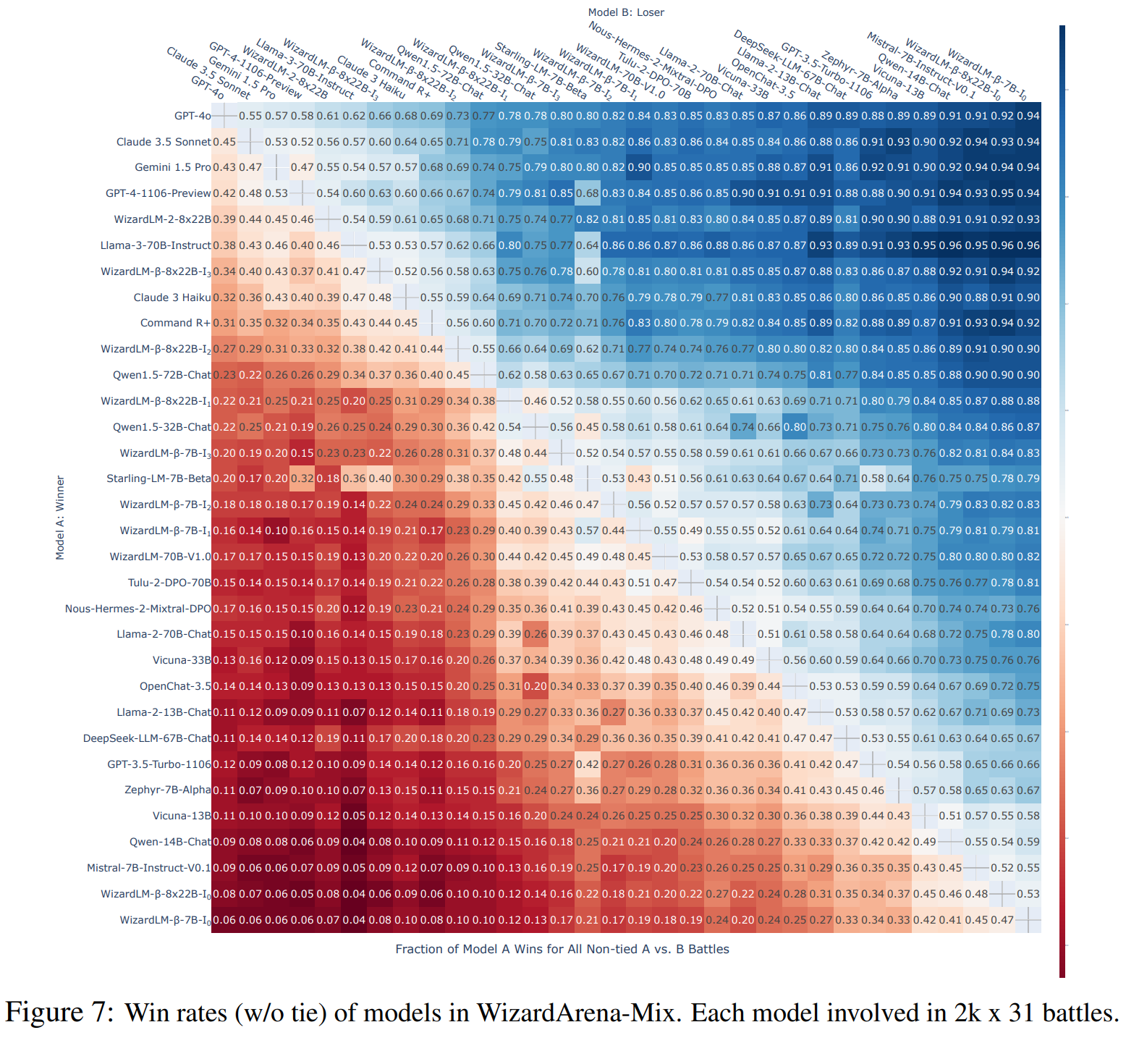
Following Table demonstrates the impact of using the methodname method to post-train WizardLM-beta models during three data flywheel iterations, where I_i represents the i-th iteration. In each iteration from I_1 to I_3, we always use 90k data for post-training. Starting from WizardLM-β-7B-I_0, the next 3 iterations have improved by 343 points, 32 points, and 28 points on Wizardarena-Mix Elo, respectively. At the same time, the MT-bench score of this model has also achieved significant improvement (from 6.41 to 8.16). Specifically, the WizardLM-β-7B-I_1 even surpasses WizardLM-70B-v1.0 and the WizardLM-β-7B-I_3 also shows comparable performance with Starling-LM-7B-Beta. It is worth noting that we have also observed the same trend on WizardLM-β-8x22B models, and even achieved a more significant increase in both Wizardarena-Mix Elo (+460) and MT-Bench (+2.07). This model also beats both Command R+ and Claude 3 Haiku. Following Figure presents the win rates of 32 models in WizardArena-Mix, with each model involving in 2k x 31 battles. Compared to those baselines, our model has achieved significant improvements in win rate from the I_0 to I_3. Specifically, using GPT-4o as the battle target, our WizardLM-β-8x22B’s win rate increased by 26% (8% -> 22% -> 27% ->34%), WizardLM-β-7B’s win rate also increased by 14% (6% -> 16% -> 18% ->20%).
Above results highlight that continuous battle with SOTA models with Arena Learning and updating weights with new selected data can progressively enhance model capacities compared to its rivals. Hence, Arena Learning builds an effective data flywheel and utilizing the Arena Learning can significantly improve model performance in post-training.
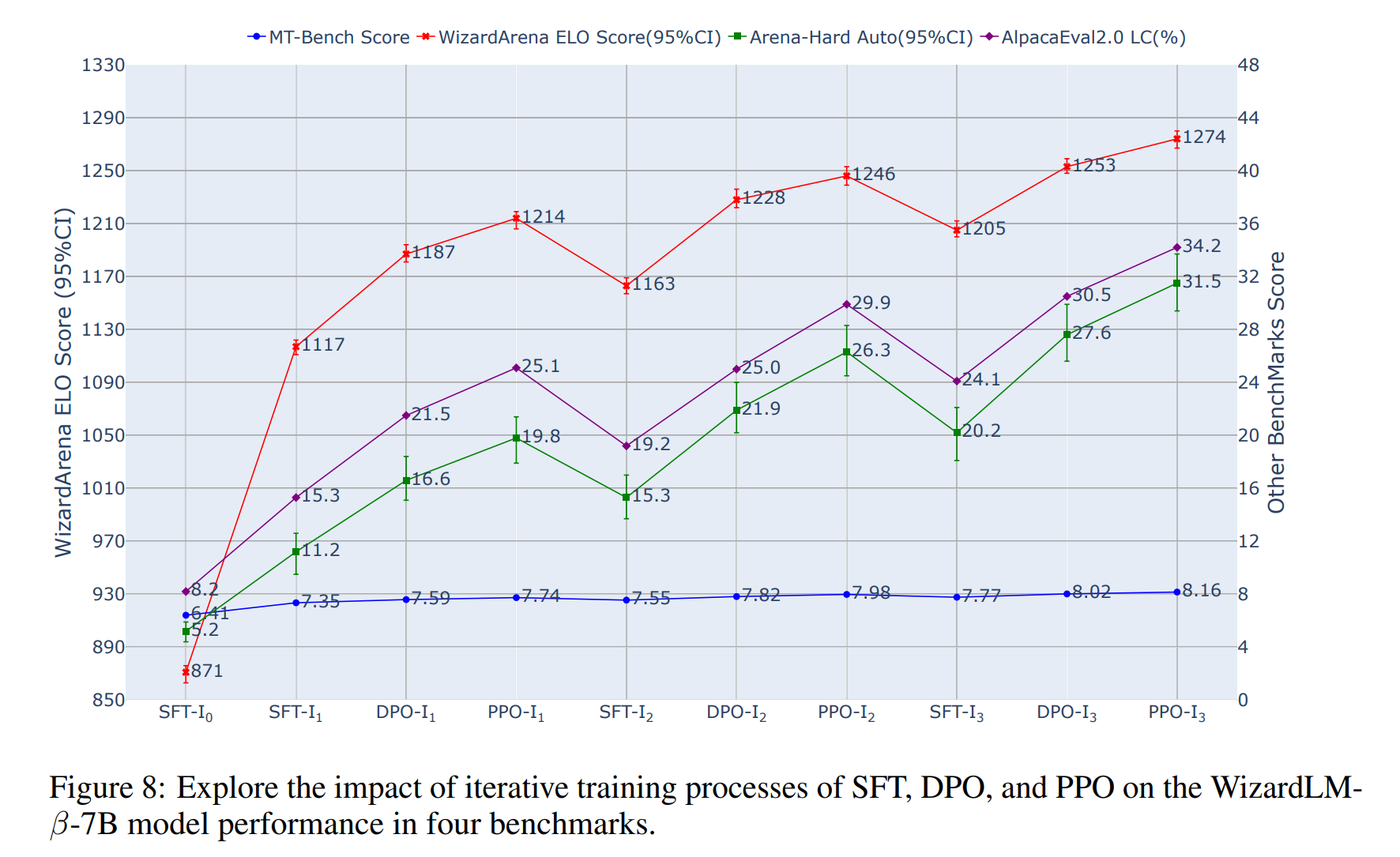
3.3 Scaling Iterative SFT, DPO, and PPO with Arena Learning.
As the core question of this paper asks how Arena Learning improves a model’s performance with post-training, in this section we examine how performance is affected by different post-training technology and data flywheel iterations. Following Figure explores the results of WizardLM-β-7B model. As expected, we observe that each performance across the SFT and RL models improves step by step as we add more selected data from more Arena Learning battle iterations. Specifically, from SFT-I_0 to PPO-I_3, the WizardArena-Mix ELO score improves from 871 to 1274, achieves a huge gain of 403 points, and the Arena-Hard Auto ELO score also rose by 26.3 points (from 5.2 to 31.5). Additionally, the AlpacaEval 2.0 LC win rate improved by 26%, from 8.2% to 34.2%, and the MT-Bench score increased by 1.75 points, from 6.41 to 8.16. Significant improvements across four key benchmarks highlight the effectiveness and scalability of the iterative training approach proposed by Arena Learning in enhancing post-training LLMs during the SFT, DPO, and PPO stages.
Conclusion
In conclusion, this paper presents Arena Learning, a simulated offline chatbot arena that utilizes AI LLMs to eliminate the manual and temporal costs associated with post-training LLMs, while preserving the benefits of arena-based evaluation and training. The effectiveness of Arena Learning is validated through the high consistency in predicting Elo rankings among different LLMs compared to the human-based LMSys Chatbot Arena. Furthermore, the model iteratively trained on synthetic data generated by Arena Learning exhibits significant performance improvements across various training strategies. This work showcases the potential of Arena Learning as a cost-effective and reliable alternative to human-based evaluation and data flywheel platform for post-training large language models.
Citation
@misc{luo2024arena,
title={Arena Learning: Build Data Flywheel for LLMs Post-training via Simulated Chatbot Arena},
author={Haipeng Luo and Qingfeng Sun and Can Xu and Pu Zhao and Qingwei Lin and Jianguang Lou and Shifeng Chen and Yansong Tang and Weizhu Chen},
year={2024},
eprint={2407.10627},
archivePrefix={arXiv},
primaryClass={cs.CL}
}