
 Website structure understanding can be treated as a reverse engineering for the purpose of automatically discovering the layout templates and URL patterns of a website, and understanding how these templates and patterns are integrated to organize the website. The study of this problem has had a great impact to many applications which can leverage such site-level knowledge to help web search and data mining.
Website structure understanding can be treated as a reverse engineering for the purpose of automatically discovering the layout templates and URL patterns of a website, and understanding how these templates and patterns are integrated to organize the website. The study of this problem has had a great impact to many applications which can leverage such site-level knowledge to help web search and data mining.
Almost every website on the Internet has a distinct design & organization structure. Experienced website designers usually create distinguishable layout templates for pages of different functions. They then organize the website by linking various pages with hyperlinks, each of which is represented by a URL string following some pre-defined syntactic patterns. This project is a reverse engineering to automatically discover the layout templates and URL patterns of a website, and understand how these templates and patterns are integrated to organize the website. To demonstrate the power of website structure understanding, this project also proposes some applications which leverage such site-level knowledge to help web search and data mining.
-
We first give a brief introduction to the concept “website structure” defined in this project, and then present the basic flowchart and methods currently developed to automatically mine the website structure of a given website.
What’s Website Structure?
In this project, the website structure consists of three components: layout templates, URL patterns, and linkage structure.
Layout Template
Most web pages consist of HTML elements like table, menu, button, image, and input box. The layout of a web page describes what HTML elements are included in the page, as well as how these elements are visually distributed in page rendering. Essentially, a page layout is represented by a so called DOM (Document Object Model) tree. In this project, a layout template is considered as a group of pages which have very similar layouts (DOM trees).
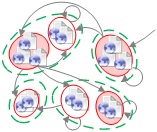
In a website, pages are generated based on distinguishable templates according to their functions. That is to say, visually similar pages usually have same function. In this way, user can easily identify a page’s function at a glance. Following are several typical layout templates identified from the ASP.NET Forums. Their functions are to show a) a list of discussion thread, b) a list of thread posts, and c) user profile, respectively.
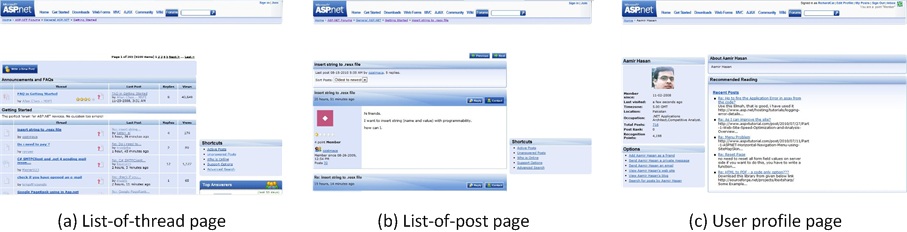
Fig. 1. Typical layout templates from the ASP.NET Forums. They are designed to show a) a list of discussion thread, b) a list of thread posts, and c) user profile, respectively.
URL Pattern
A URL pattern is a generalization of a group of URLs sharing similar syntactic format. In general, a URL pattern can be represented with a regular expression. Following we show some example URL patterns discovered, again, from the ASP.NET Forums.
-
- List-of-thread pages
- ^http://forums.asp.net/d+.aspx$
- ^http://forums.asp.net/d+.aspx?PageIndex=d+&forumoptions=d+:d+:d+::$
- List-of-post pages
- ^http://forums.asp.net/t/d+.aspx$
- ^http://forums.asp.net/t/d+.aspx?PageIndex=d+$
- ^http://forums.asp.net/p/d+/d+.aspx$
- ^http://forums.asp.net/ThreadNavigation.aspx?PostID=d+&NavType=(Previous|Next)$
- User profile pages
- ^http://forums.asp.net/user/Profile.aspx?UserID=d+$
- ^http://forums.asp.net/members/[^/?]*$
- List-of-thread pages
It is noticed that one layout templates can have more than one related URL pattern. For example, a bookseller website usually designs one template to show a list of books, and provides different query parameters to generate such a list. Various query parameters in this scenario will lead to different URL patterns, but the search results are shown with the same template. Another common case is duplicate pages, i.e., pages with the same content (and very likely the same layout) but different URLs.
Link Structure
Based on the layout templates and URL patterns, we can construct a directed graph to represent the website organization structure. That is, each layout template is considered as a node in a graph, and two nodes are linked if there are hyperlinks between the pages belonging to the two nodes. The link direction is the same as the related hyperlinks. And each link is characterized with the URL pattern of the corresponding hyperlink URLs. Again, it should be noticed that there could be multiple links from one node to another if the corresponding hyperlinks have more than one URL pattern.
Fig. 2 gives an illustrative example of the sub-graph constructed based on the layout templates and URL patterns above.
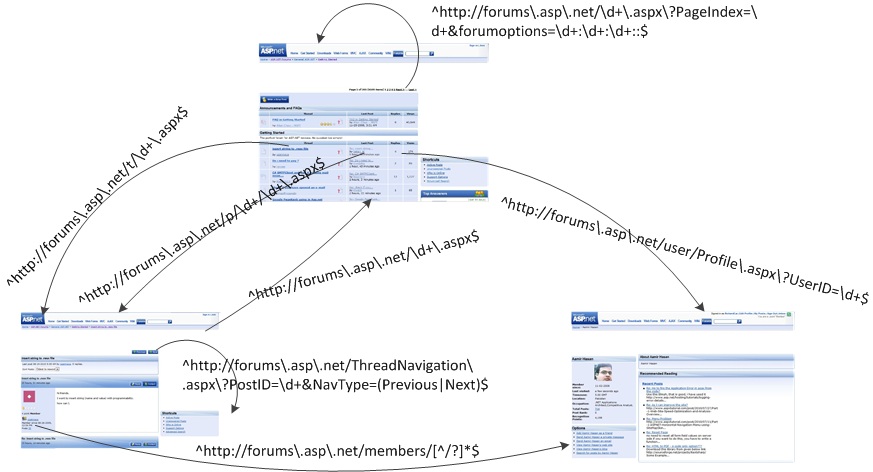 Fig. 2 An illustrative sub link-graph for the ASP.NET Forums.
Fig. 2 An illustrative sub link-graph for the ASP.NET Forums.Understand Website Structure
To automatically discover the organization structure of a given website, an unsupervised pipeline was proposed in this project. The basic idea is to first sample a few pages randomly from the target website, then discover layout template and URL patterns by grouping these sampled pages, and finally reconstruct the link graph. Figure 3 shows the flowchart of the pipeline, which consists of four components: random sampling, page layout grouping, URL pattern discovery, and link structure reconstruction.
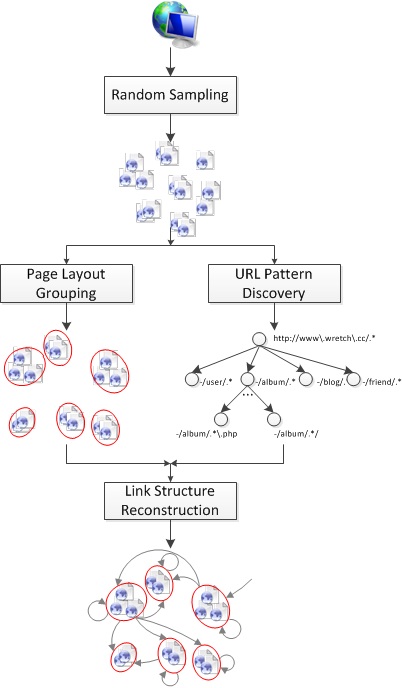 Fig. 3. The flowchat of the proposed pipeline for website structure understanding.
Fig. 3. The flowchat of the proposed pipeline for website structure understanding.Random Sampling
The goal of random sampling is to provide a snapshot of a website by downloading only a relatively small number of pages. The sampling quality is the foundation of the whole mining process. To keep the downloaded pages as diverse as possible, in practice the sampling process adopts a strategy combining both breadth-first and depth-first, and can quickly retrieve pages at deep levels within a few steps.
Page Layout Grouping
Pages with similar layout usually have similar HTML components. Fig. 4 gives an illustrative example. In Fig. 4 there are four pages from the website of Amazon, two of them are detailed pages of product introduction; while the other two are pages of help. Some salient HTML components in these four pages are marked with color ellipses. It is clear that similar layout have similar HTML components.
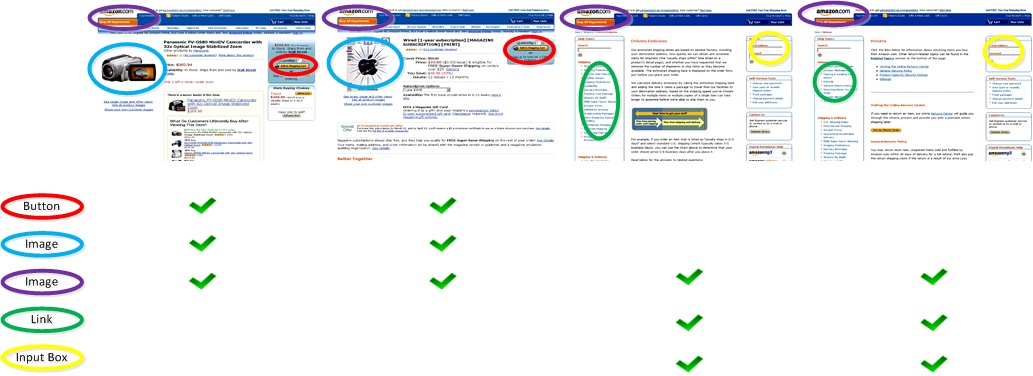 Fig. 4. Four pages from the website of Amazon. It clear that they have different HTML elements (marked with color ellipses) and can be categorized into two layout templates.
Fig. 4. Four pages from the website of Amazon. It clear that they have different HTML elements (marked with color ellipses) and can be categorized into two layout templates.Inspired by this observation, in this project, DOM path is utilized to characterize the layout of a webpage. As shown in Fig. 5, a DOM path is a path from a leaf node to the root of the DOM tree. The leaf node indicates the component type, and the path-to-root approximately describes the visual location of that component in page rendering.
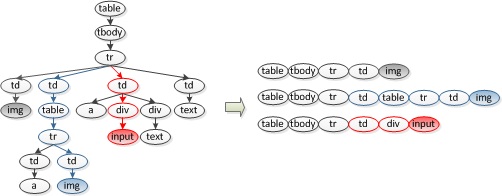 Fig. 5. An illustrative example of a (patial) DOM tree and some extracted DOM paths as features for page layout grouping.
Fig. 5. An illustrative example of a (patial) DOM tree and some extracted DOM paths as features for page layout grouping.Given a set of HTML pages, all unique DOM paths are extracted to form a feature space. Each page is represented by a point in the feature space, and the layout similarity of two pages can be estimated. A bottom-up strategy is then utilized to group similar pages, and each cluster is considered as a layout template.
URL Pattern Discovery
A URL is not an ordinary string but has a syntax structure scheme strictly defined by W3C standards. Based on a syntax structure, a URL string can be represented by a group of key-value pairs. Fig. 6 gives an example URL, its syntax structure, and the corresponding key-value pairs.
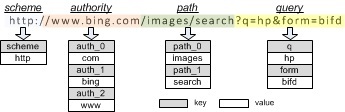 Fig. 6. An illustration of the syntax structure of a URL, based on which it can be described as a set of key–value pairs
Fig. 6. An illustration of the syntax structure of a URL, based on which it can be described as a set of key–value pairsIt is noticed that different URL components (or keys) usually have different functions and play different roles in a website. In general, keys denoting directories, functions, and document types are with only a few values, which should be explicitly recorded in a URL pattern. By contrast, keys denoting parameters such as user names are with quite diverse values, which should be generalized in the pattern. Based on this observation, a top-down recursive split process is proposed in this project to construct a pattern tree to characterize a set of URLs. Fig. 7 gives an example pattern tree based on URLs from www.wretch.cc. Algorithm details please refer to [9].
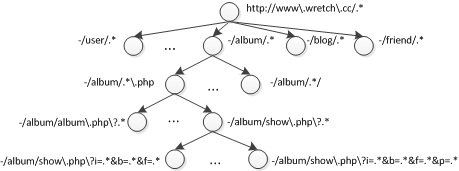 Fig. 7. An illustration of the pattern tree based on URLs from www.wretch.cc. The tree has been simplified for a clear view.
Fig. 7. An illustration of the pattern tree based on URLs from www.wretch.cc. The tree has been simplified for a clear view.Link Structure Reconstruction
Once the layout templates and URL patterns are avaliable, the construction of the link graph is quite straigthforward. Two layout templates are linked if there are links between pages belonging to the two templates, and the link is characterized with the URL pattern of the corresponding pages. Algorithm details please refer to [1-3].
-
-
Website structure information, as a kind of site-level knowledge, can help a lot of applications in web search and data mining. Currently, we have demonstrated the power of website structure information in two areas: 1) improving index quality of a search engine and 2) structure data extraction and mining.
Improving Index Quality of a Search Engine
Index quality is very critical to a search engine. Website structure information provides site specific knowledge and can help improve the quality of a search engine index.
Focused Crawling
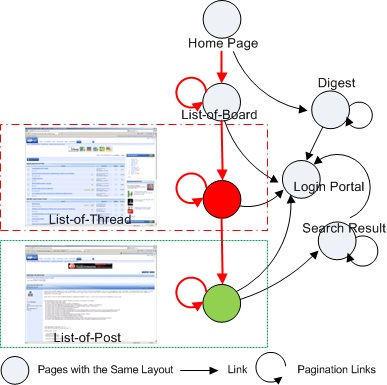 Fig. 7. An illustration of focused forum crawling.
Fig. 7. An illustration of focused forum crawling.Not all the pages in a website are valuable to a search engine. For example, private pages may redirect the crawler to a login portal page. And for vertical search, only a part of pages containing related information are worth crawling. Focused crawling is to optimize the bandwidth and download as many targeted pages as possible. With the mined site-level link graph, we can provide better strategy to do focused crawling.
In this project, we take web forum crawling as an example to show how such site-level structure information is useful. A framework was proposed in [1] to fetch a forum more efficiently and effectively. Around 50% bandwidth can be saved by only downloading list-of-thread and list-of-post pages and discarding valueless supplementary pages. The crawling traversal strategy was further improved in [2] to increase the performance. Targeted on incremental crawling, a list-wise strategy was developed in [3] to fetch newly published posts in the first time.
Ongoing work is to extend the focused crawling to websites general than forums. The basic idea is to assign higher priorities to those pages important to users. Such a priority is assigned to a layout template or a URL pattern, instead of to individual pages.
URL Normalization for Duplication Deduction
 Fig. 8. The flowchart of the pattern tree-based approach to learn rewrite rules for URL normalization.
Fig. 8. The flowchart of the pattern tree-based approach to learn rewrite rules for URL normalization.Duplicate URLs have brought a series of troubles to a search engine. URL normalization is to rewrite a set of duplicate URLs to a canonical form. In this project, a pattern tree-based approach was proposed in [9] to automatically generate rewrite rules. Instead of previous research efforts working on individual duplicate pairs, pattern tree provides statistical information of all duplicate pairs in a website. In this way, we can accelerate the learning process and generate more reliable rewrite rules. Fig. 8 shows the flowchart of this approach.
Structured Data Extraction and Mining
Previous research on structured data extraction usually only works on process individual pages. The noise information on single page is easy to distort the extraction results. In contrast, if consider multiple pages having the same layout template, we can obtain relatively robust template-level statistical information and help improve the performance of structured data extraction.
Structure Data Extraction
Based on the site-level layout templates, a novel approach was proposed in [4] to extract structured data like title/author/publish-date from web forums. Besides features extracted on a single page, we also leverage features extracted from cross pages. Experimental results show that cross page features significantly improve the performance.
Ongoing work is to extend this idea to websites general than forums.
Modeling Semantics and Structure of Forum Thread
In this project, we also did data mining on web forums based on the extracted structured data. For example, a sparse coding approach was proposed in [5,6] to simultaneously model both semantics and structure of discussion threads in forums. And we also investigated the user grouping behavior in forums in [7]; as well as mined reply relationships among posts in [8].
-
Special acknowledgement to team members who once contributed to, or are still working on, this project.
Researchers
Rui Cai (opens in new tab), Jiang-Ming Yang (opens in new tab), Lei Zhang (opens in new tab), Wei Lai, Zhiwei Li, Xin-Jing Wang, Wei-Ying Ma (opens in new tab)
Interns
Yida Wang, Hua Huang, Tao Lei, Chunsong Wang, Chen Lin, Jun Zhu (opens in new tab), Bailu Ding (opens in new tab), Xiaolin Shi (opens in new tab)