
— Philip Pullman, The Subtle Knife (opens in new tab) (Scholastic, 1997; USA, Knopf, 1997)
— Philip Pullman, The Subtle Knife (opens in new tab) (Scholastic, 1997; USA, Knopf, 1997)
 (opens in new tab)Digital technologies have repeatedly redefined the paper world of books. Digital printing has overhauled the publishing processes, and the internet has revolutionised the way audiences and authors connect to share their enthusiasm and criticism. Now the digitization of books themselves, either for searching, browsing, and reading on a computer screen through services like Google Books, or for reading on dedicated devices like Amazon’s Kindle or the Sony Reader are threatening the established order.
(opens in new tab)Digital technologies have repeatedly redefined the paper world of books. Digital printing has overhauled the publishing processes, and the internet has revolutionised the way audiences and authors connect to share their enthusiasm and criticism. Now the digitization of books themselves, either for searching, browsing, and reading on a computer screen through services like Google Books, or for reading on dedicated devices like Amazon’s Kindle or the Sony Reader are threatening the established order.
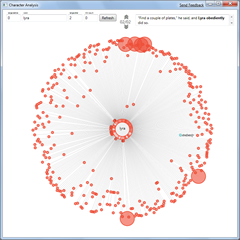
But for this project we side-step these issues and concentrate instead on how the analytical power and display capabilities of computers may be used to enhance our understanding of book texts. We use the term “book texts” rather than the word “books” as we are not trying to build computer systems that might understand books, but rather we use the computer’s ability to treat books as an abstract sequence of words as the starting point for new analytical tools.
Who would use such tools? Anyone with an interest in books, be they authors, readers, publishers, agents, critics, academics, etc may find such tools useful, but we have designed our visualizations with fans and academic readers in mind. These readers form theories about the books that stand alongside the author’s own understanding and we hope that the abstract visualizations provided may help such an endeavour.
 (opens in new tab)The statistical analysis of texts is an important area of work and is used widely in information retrieval (e.g. web search). It is also a mature area of research in its own right, and has been used in the past for things from author attribution to the ordering of works through time. For example in a letter published in 1882 Augustus De Morgan speculated about using statistical techniques to explore authorship questions around St Paul’s Epistles and the Epistle to the Hebrews [Lea76], while more recently Jockers, Witten, and Criddle (opens in new tab)used sophisticated statistical techniques to reassess the authorship of the Book of Mormon.
(opens in new tab)The statistical analysis of texts is an important area of work and is used widely in information retrieval (e.g. web search). It is also a mature area of research in its own right, and has been used in the past for things from author attribution to the ordering of works through time. For example in a letter published in 1882 Augustus De Morgan speculated about using statistical techniques to explore authorship questions around St Paul’s Epistles and the Epistle to the Hebrews [Lea76], while more recently Jockers, Witten, and Criddle (opens in new tab)used sophisticated statistical techniques to reassess the authorship of the Book of Mormon.
In contrast, the abstract visualization of book texts is not a large or a mature field of study, but there are notable and inspirational examples. The following sections list some of these (more on separate tab)
 Our work focuses on the abstract visualization of children’s book series, and in particular the trilogy “His Dark Materials” by Philip Pullman. Pullman’s trilogy is made up of the three novels “The Northern Lights” (called “The Golden Compass” in the USA and in the movie adaptation), “The Subtle Knife”, and “The Amber Spyglass”. We choose this genre partly through personal passion and partly because of the range of potential enthusiastic readers. The best children’s book series (especially before they are completed) are read and discussed by child and adult readers and many of these readers develop their own theories which they share with their friends and with other readers online. Similarly academic interest is piqued and there are conferences and journals dedicated to the study of children’s literature (more on separate tab)
Our work focuses on the abstract visualization of children’s book series, and in particular the trilogy “His Dark Materials” by Philip Pullman. Pullman’s trilogy is made up of the three novels “The Northern Lights” (called “The Golden Compass” in the USA and in the movie adaptation), “The Subtle Knife”, and “The Amber Spyglass”. We choose this genre partly through personal passion and partly because of the range of potential enthusiastic readers. The best children’s book series (especially before they are completed) are read and discussed by child and adult readers and many of these readers develop their own theories which they share with their friends and with other readers online. Similarly academic interest is piqued and there are conferences and journals dedicated to the study of children’s literature (more on separate tab)
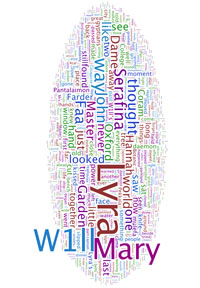 (opens in new tab)There are several directions we’d like to take this work in now.
(opens in new tab)There are several directions we’d like to take this work in now.
We need to take these visualizations out of the research lab and engage both the fans and the academics who are theorising about Pullman’s works. We should engage them with these tools and establish if the tools are useful, how they might be improved, and what other visualizations may be of value to the community.
Throughout this work we took the view that computers were not adept at understanding books, but should just essentially count words and draw the results for people to interpret. However advances in machine learning, and especially toolkits enabling machine learning techniques to be applied quickly to new domains have led us to seek to apply Infer.Net (opens in new tab)to the analysis phase of the visualization.
Inevitably building visualizations leads to 1,001 other ideas as to how the data may be visualized. We would like to add the ability to pivot (e.g. for one flowers bud to open another flower side-by-side). We would like to add animations so that the dynamic movement between visualizations or as a visualization is formed is part of the semantics of the visualization itself.
The visualizations we made are not available for public use – either online or through downloading. This is partly because we have not spent time looking at the rights implications and partly because we have not engineered the code to the quality level required for public use. It would be great to get this to a level where people can try the visualizations we built for themselves without us present.
It would be interesting to apply this work to other children’s book series, to see if the characteristic patterns revealed in the visualizations were different from author to author. We might also move from a reader’s perspective to a learner’s perspective and choose books which often appear on high-school syllabuses. But most intriguing would be to build visualizations that contrast the content and style of different author’s work.
 (opens in new tab)This work was done as a collaboration between Linda Becker (opens in new tab) and Tim Regan (opens in new tab)during Linda’s internship at Microsoft Research’s Cambridge Lab (opens in new tab)in the Summer of 2008. The work would not have been possible without the generous, thought provoking, and supportive help of Pullman’s publishers especially Marion Lloyd (opens in new tab)and Claire Tagg at Scholastic (opens in new tab), Pullman’s agent Caradoc King (opens in new tab), and Philip Pullman (opens in new tab) himself.
(opens in new tab)This work was done as a collaboration between Linda Becker (opens in new tab) and Tim Regan (opens in new tab)during Linda’s internship at Microsoft Research’s Cambridge Lab (opens in new tab)in the Summer of 2008. The work would not have been possible without the generous, thought provoking, and supportive help of Pullman’s publishers especially Marion Lloyd (opens in new tab)and Claire Tagg at Scholastic (opens in new tab), Pullman’s agent Caradoc King (opens in new tab), and Philip Pullman (opens in new tab) himself.
Principal Software Engineering Lead, Azure Sphere