

Real-World Table Interpretation
Bringing out the power of semantics in tabular data
Tables are commonly used to organize information, playing a key role in data analytics, scientific research, and business communication. The ability to automatically extract semantics in tables can empower many downstream applications such as data analytics, robotic process automation (RPA), knowledge base population, etc.
In this project, we explore multiple aspects of semantic table understanding and real-world applications of such technologies.
One of the outcomes of this project is LinkingPark v2, an automatic semantic annotation system for tabular data to knowledge graph matching. LinkingPark features a number of desirable properties including modular design, unsupervised nature, stability, effectiveness, efficiency, and flexibility for multilingual support. LinkingPark can handle Cell-Entity Annotation (CEA), Column-Type Annotation (CTA), and Columns-Property Annotation (CPA) altogether.
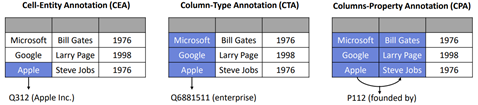
You can find more information on the LinkingPark system whitepaper “The LinkingPark System: Leveraging the Power of Knowledge Graphs in Tabular Data Productivity” or in the Publications tab. The system is in use in product collaborations and accessible internally both via a RESTful API and an accompanying Excel Add-In for user iterative exploration. Please reach out to the Knowledge Computing group for further details on usage/access.
Open Source Code
Linking Park is open-source on GitHub (opens in new tab)! Contributions and collaboration are very welcome!
Demo Video
This video introduction (opens in new tab) showcases some of the capabilities of LinkingPark. It uses an Excel Add-In as user interface.
Awards
A previous prototype of LinkingPark has won second place in the Semantic Web Challenge on Tabular Data to Knowledge Graph Matching 2020 (SemTab 2020 (opens in new tab)).