

Neural Networks-based Speech Enhancement
成立时间:January 8, 2017
Summary
Decades of research in processing audio signals has led to performance saturation. However, recent advances in artificial intelligence (AI) and machine learning (ML) provides a new opportunity to advance the state-of-the-art. In this project, one of the first problems we focus on is enhancing speech signals as they are captured by microphones. Speech enhancement is a precursor to several applications like VoIP, teleconferencing systems, speech recognition, and hearing aids. Its importance has grown further with the emergence of mobile, wearable and smart home devices, which present challenging capture and processing conditions due to their limited processing capabilities, voice-first IO interfaces and increased speaker-microphone distances. The goal of speech enhancement is to take the audio signal from a microphone, clean it and forward clean audio to multiple clients such as speech-recognition software, archival databases and speakers. The process of cleaning is what we focus on in this project. This has traditionally been done with statistical signal processing. However, these techniques make several assumptions that are imprecise. We explore data-driven ways of completing this task in the most efficient, dynamic and accurate manner.
Speech Enhancement Challenges
Recent advances in machine learning (ML) and artificial intelligence (AI) have shown impressive results for the speech enhancement task, i.e. that it is possible to remove almost any kind of background noise, such as barking dogs, kitchen noise, music, babble, traffic and outdoor sounds, etc. This is an exciting novelty compared to traditional statistical signal processing based methods, which usually only attenuate quasi-stationary noise efficiently. However, ML-based speech enhancement is still at the very beginning of being in a mature enough state for being productized and faces the following challenges:
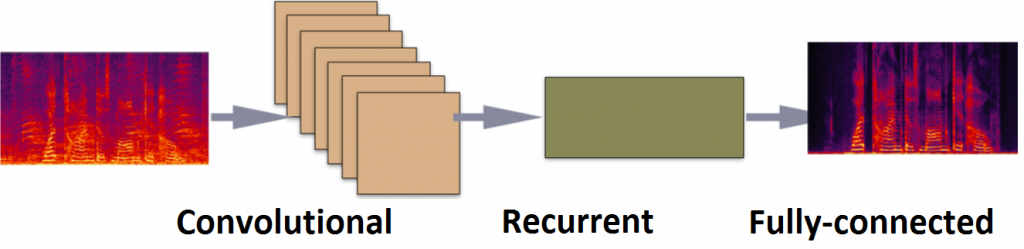
1. Speech quality: While the suppression capability of AI-powered speech enhancement is impressive, speech quality is often degraded. More research is directed in improving the speech quality by improving data generation and augmentation, exploring optimization targets, and improving the network models. In one of our early works we have e.g. used convolutional-recurrent network structures for speech enhancement.
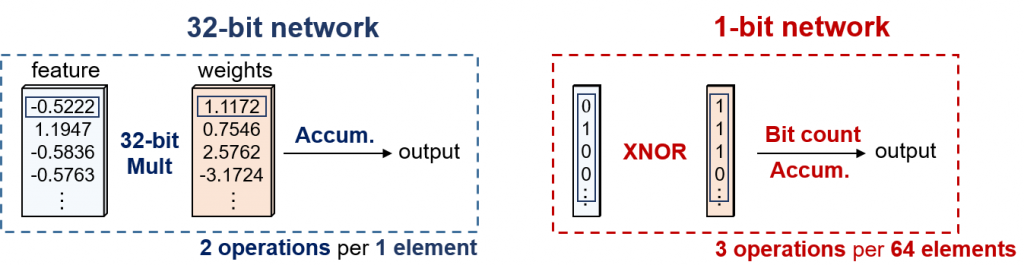
2. Inference efficiency: High audio quality is often obtained with very large neural network models, which have prohibiting high inference complexity and sometimes also processing delay. Actively trying to reduce the model size, complexity, memory footprint, and processing delay is an important part of research, to be able to run these models on resource constrained edge devices. In the past, we already explored increasing model efficiency by bit-precision scaling for speech enhancement and voice activity detection. We also investigated small recurrent networks for enhancement to ensure real-time inference constraints.
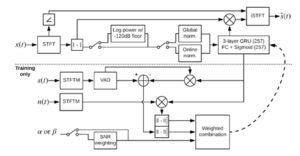
3. Unsupervised learning: Most efficient results in ML are achieved by supervised learning. In the context of training a speech enhancement model, this means that we need to prepare a dataset with noisy and clean target speech. This has the disadvantage of large of effort in creating a robust dataset for all conditions encountered in reality. However, there will be always conditions, which have not been trained for. Unsupervised learning can potentially help to overcome this problem, as a ground truth is not required and theoretically, a model can be built to adapt to unseen noise on-the-fly. We had a first attempt using reinforcement learning to adapt a speech enhancement algorithm to the input signal using recurrent networks.
Audio Quality Measurement
The performance in terms of quality and intelligibility of speech enhancement has traditionally been evaluated by distance metrics between the enhanced and target speech signal, such as PESQ, frequency-weighted SNR, STOI, and so forth. However, in contrast to enhancement for ASR, where the word error rate is a very defined single optimization criterion, these employed metrics in speech enhancement are often only correlated up to a certain extent with the actual subjective speech quality. As conducting listening tests with humans is cost- and time intensive, a lot of recent research is going towards developing ML models that try to predict speech quality. We started this work in summer 2018 developing a first speech quality predictor model for audio calls and are continuing this work to improve the accuracy. Major challenges comprise building a robust enough dataset and incorporate all kinds of degrading distortions, which can be from acoustic nature, processing or transmission artifacts. These speech quality predictors provide us powerful tools to advance speech enhancement models and ultimately, also serve as an optimization function.