
DialoGPT
成立时间:November 1, 2019
DialoGPT: Toward Human-Quality Conversational Response Generation via Large-Scale Pretraining
 The DialoGPT project establishes a foundation for building versatile open-domain chatbots that can deliver engaging and natural conversational responses across a variety of conversational topics, tasks, and information requests, without resorting to heavy hand-crafting.
The DialoGPT project establishes a foundation for building versatile open-domain chatbots that can deliver engaging and natural conversational responses across a variety of conversational topics, tasks, and information requests, without resorting to heavy hand-crafting.
Until recently, such versatile conversational AI systems seemed elusive. The advent of large-scale transformer-based pretraining methods (like GPT-2 (opens in new tab) and BERT) is changing that. The empirical success of pretraining methods in other areas of natural language processing has inspired researchers to apply them to conversational AI, often to good effect (for example, HuggingFace’s transfer learning model (opens in new tab)). However, such models are trained on conventional written text, which is often not representative how people interact. With the dual goal of attaining the topical versatility afforded by scale with a more conversationally interactive tone, DialoGPT takes transformer-based pretraining one step further to leverage massive amounts of publicly-available colloquial text data.
DialoGPT adapts pretraining techniques to response generation using hundreds of Gigabytes of colloquial data. Like GPT-2, DialoGPT is formulated as an autoregressive (AR) language model, and uses a multi-layer transformer as model architecture. Unlike GPT-2, which trains on general text data, DialoGPT draws on 147M multi-turn dialogues extracted from Reddit discussion threads. Our implementation is based on the huggingface pytorch-transformer (opens in new tab) and OpenAI GPT-2 (opens in new tab). We have released a public Github repo (opens in new tab) for DialoGPT, which contains a data extraction script, model training code and model checkpoints (opens in new tab) for pretrained small (117M), medium (345M) and large (762M) models. We hope this release will foster exploration of large-scale pretraining for response generation by the conversational AI research community.
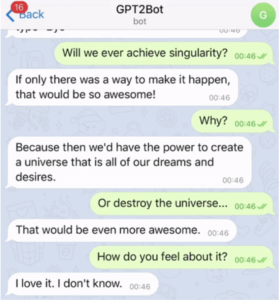
Our assumption has been that our DialoGPT approach should capture the joint distribution of source/prompt and target/response pairs in conversational flow with good granularity. In practice, this is what we observe: sentences generated by DialoGPT are diverse and contain information specific to the source prompt, analogous to the outputs that GPT-2 generates. We have evaluated the model on a public benchmark dataset (DSTC-7), and a new 6k multi- reference test dataset extracted from Reddit postings. Our experiments show a state-of-the-art performance in terms of automatic evaluation (opens in new tab) (including relevance and diversity metrics). Results of evaluation using human judges (opens in new tab) suggest that DialoGPT responses may approach human-level response quality in a single-turn Turing test. Generated examples may be seen here (opens in new tab).
This project aims to facilitate research in large-scale pretraining for conversational data; accordingly it is released as a model only. On its own, the model provides only information about the weights of text spans. The onus of decoder implementation resides with the user. Several 3rd party decoding implementations (opens in new tab) are available, including a 10-line decoding script snippet (opens in new tab) from Huggingface team.
The conversational text data used to train DialoGPT is different from the large written text corpora (e.g. wiki, news) associated with previous pretrained models. It is less formal, more interactive, occasionally trollish, and in general much noisier. These characteristics pose new challenges (and opportunities) in training and decoding. Despite efforts to minimize the amount of overtly offensive data prior to training, DialoGPT can still generate output that may trigger offense. Output may reflect gender and other historical biases implicit in the data and may exhibit a propensity to express agreement with propositions that are unethical, biased or offensive (or the reverse, disagreeing with otherwise ethical statements). These are known issues in current state-of-the-art end-to-end conversation models trained on large naturally-occurring datasets. A major motive for releasing DialoGPT is to facilitate investigation of these issues and develop mitigation strategies. In no case should inappropriate content generated as a result of using DialoGPT be construed to reflect the views or values of either the authors or Microsoft Corporation.
This project is a joint project between MSR AI and Microsoft Dynamics 365 AI Research team. For more details, please see our Github repository (opens in new tab) and our paper (opens in new tab) published on the ACL 2020 demo track. This project has also been featured in the news media (The Register (opens in new tab), InfoQ (opens in new tab), AdWeek (opens in new tab)).