
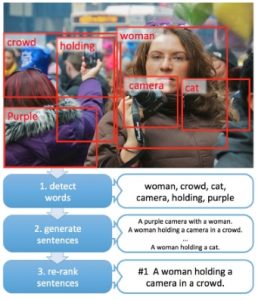
 We introduce a novel approach for automatically generating image descriptions. Visual detectors, language models, and deep multimodal similarity models are learned directly from a dataset of image captions. Our system is state-of-the-art on the official Microsoft COCO benchmark, producing a BLEU-4 score of 29.1%. Human judges consider the captions to be as good as or better than humans 34% of the time.
We introduce a novel approach for automatically generating image descriptions. Visual detectors, language models, and deep multimodal similarity models are learned directly from a dataset of image captions. Our system is state-of-the-art on the official Microsoft COCO benchmark, producing a BLEU-4 score of 29.1%. Human judges consider the captions to be as good as or better than humans 34% of the time.
Personne
Jianfeng Gao
Distinguished Scientist & Vice President