
Microsoft Dialogue Challenge: Building End-to-End Task-Completion Dialogue Systems, at SLT 2018. [Proposal] All the data, source code and schedule information will be updated here.
This project aims to develop intelligent dialogue agents to help users effectively accomplish tasks via natural language conversation. A typical goal-oriented dialogue system contains three major components: natural language understanding (NLU), natural language generation (NLG), and dialogue management (DM) that consists of state tracking and policy learning. Our research focus is on deep reinforcement learning approaches for dialogue management in goal-oriented dialogue settings, including movie ticket booking, trip planning, sales assistant etc.
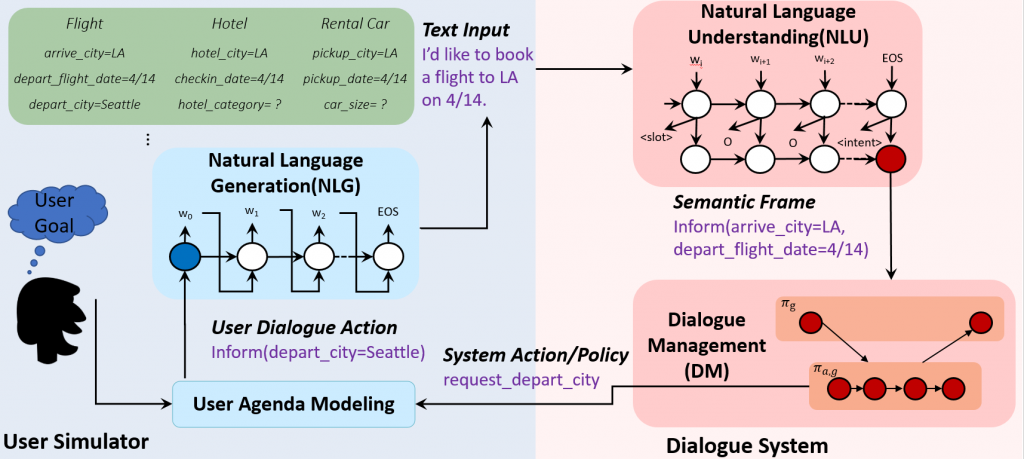
Composite Task Completion Dialogue System
User Simulator
Training reinforcement learners is challenging because they need an environment to operate in. Thus, we developed a user simulator for learning and evaluation. [Li et al. 2016]
Infobot
We developed the first end-to-end reinforcement learning agent with differential knowledge base access. [Dhuwan et al. ACL 2017], and the first end-to-end dialogue policy trained with both supervised and reinforcement learning [Williams et al. 2016].
Task-completion bot
We developed an end-to-end learning framework for task-completion neural dialogue systems [Li et al. IJCNLP 2017]. We also developed an BBQ Networks (Bayes-by-Backprop Q-Networks) which performs efficient exploration for dialogue policy learning [Lipton et al. 2017], as well as efficient actor-critic methods which substantially reduce the sample complexity for end-to-end learning of LSTM-based dialogue policy [Asadi et al. 2016].
Composite Task-completion bot
We developed a composite task-completion dialogue system, based on hierarchical reinforcement learning to learn the dialogue policies that operate at different temporal scales, and demonstrated its significant improvement over flat deep reinforcement learning in both simulation and human evaluation [Peng et al. EMNLP 2017]. (The source code will be released soon.)
Personne
Research Team
Jianfeng Gao
Distinguished Scientist & Vice President
Past Interns & Visitors

Kavosh Asadi
PhD student
Brown University

Yun-Nung (Vivian) Chen
Assistant Professor
National Taiwan University

Bhuwan Dhingra
Ph.D. Intern
Carnegie Mellon University

Zachary Lipton
Ph.D. Intern
University of California, San Diego

Baolin Peng
Ph.D. Intern
The Chinese University of Hong Kong

Da Tang
PhD Intern
Columbia University