
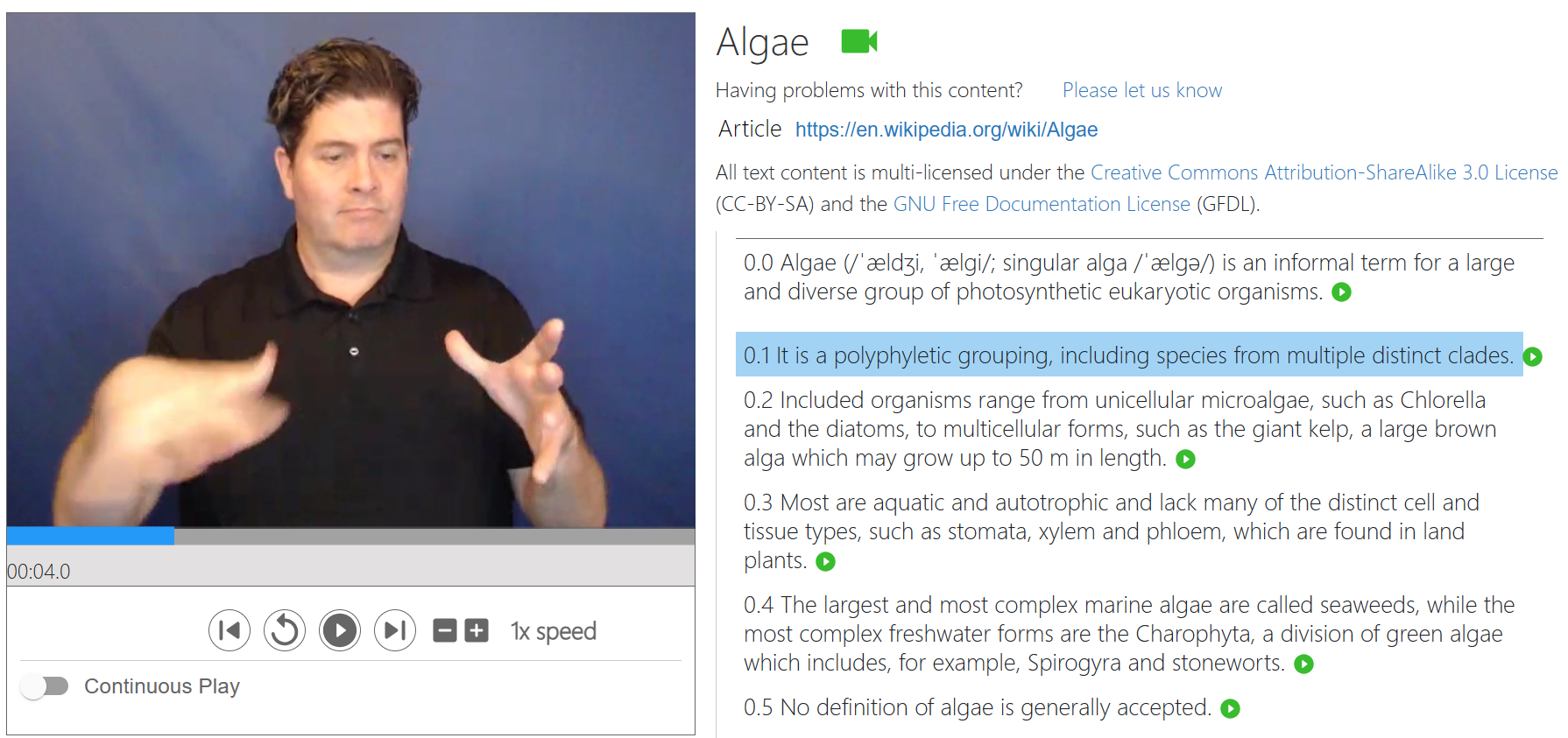
ASL STEM Wiki
Dataset and Benchmark for Interpreting STEM Articles
Motivation
For what purpose was the dataset created? Was there a specific task in mind? Was there a specific gap that needed to be filled? Please provide a description.
This dataset was created for two purposes: 1) to enable a small bilingual informational resource in both English and ASL, and 2) to provide continuous labelled sign language data for research. There is a severe shortage of such publicly available data, which is a primary barrier to research and technology advancement. More information about the bilingual resource can be found in a prior publication [1], and on the prototype website https://aslgames.azurewebsites.net/wiki/ (opens in new tab).
Additional background and all supplementary materials, including the bilingual website link, are available on the project page website https://www.microsoft.com/en-us/research/project/asl-stem-wiki/.
Who created this dataset (e.g., which team, research group) and on behalf of which entity (e.g., company, institution, organization)?
This dataset was created by Microsoft Research.
Who funded the creation of the dataset? If there is an associated grant, please provide the name of the grantor and the grant name and number.
Microsoft funded the creation of the dataset.
Any other comments?
N/A
Composition
What do the instances that comprise the dataset represent (e.g., documents, photos, people, countries)? Are there multiple types of instances (e.g., movies, users, and ratings; people and interactions between them; nodes and edges)? Please provide a description.
The dataset consists of continuous American Sign Language (ASL) videos, with associated metadata. The contents are interpretations of English Wikipedia articles related to STEM topics, recorded by professional ASL interpreters. Each recording corresponds to a single English sentence or section title in the original text. The videos are provided with the corresponding segmented English texts.
How many instances are there in total (of each type, if appropriate)?
The dataset consists of 64,266 videos, each corresponding to an English sentence or section title from a STEM-related Wikipedia article.
Does the dataset contain all possible instances or is it a sample (not necessarily random) of instances from a larger set? If the dataset is a sample, then what is the larger set? Is the sample representative of the larger set (e.g., geographic coverage)? If so, please describe how this representativeness was validated/verified. If it is not representative of the larger set, please describe why not (e.g., to cover a more diverse range of instances, because instances were withheld or unavailable).
The dataset is a sample. It contains a sample of English-to-ASL sentence-by-sentence translations of STEM-related articles from Wikipedia, and the videos contain a sample of 37 professional ASL interpreters.
What data does each instance consist of? “Raw” data (e.g., unprocessed text or images) or features? In either case, please provide a description.
Each data point consists of a video. Each video contains a single professional ASL interpreter executing an ASL translation of an English sentence or section heading from a STEM-related Wikipedia article.
Is there a label or target associated with each instance? If so, please provide a description.
Yes, each video corresponds to a portion of a Wikipedia article. We provide the corresponding text.
Is any information missing from individual instances? If so, please provide a description, explaining why this information is missing (e.g., because it was unavailable). This does not include intentionally removed information, but might include, e.g., redacted text.
No.
Are relationships between individual instances made explicit (e.g., users’ movie ratings, social network links)? If so, please describe how these relationships are made explicit.
Yes, videos are related to one another, in that they correspond to sequential sentences or titles in Wikipedia articles. We provide this sequential information in the text metadata.
Are there recommended data splits (e.g., training, development/validation, testing)? If so, please provide a description of these splits, explaining the rationale behind them.
Are there recommended data splits (e.g., training, development/validation, testing)?}{If so, please provide a description of these splits, explaining the rationale behind them.}
In our paper accompanying the dataset release, we used the following splits:
- training: all recordings of the five control articles (Acid catalysis, EDGE species, Hal Anger (person), Relativistic electromagnetism, Standard score), which provided multiple recordings per sentence
- test: all remaining articles, which provided a single recording per sentence
Dataset users can consider splitting the dataset by article or interpreter, to help preserve the independence of the test set.
Are there any errors, sources of noise, or redundancies in the dataset? If so, please provide a description.
Though the translations were made by professional ASL interpreters, the translations are still human-generated, and may contain errors. Because the translations were made from English to ASL, the former language likely influences the secondary language (e.g. in grammatical structures). The English text was also segmented into sentence units, forcing the translation to occur sentence-by-sentence, which further constrained the flexibility and naturalness of the ASL. Additionally, because the content is STEM-related and sometimes technical, fingerspelling is often used to represent concepts where signs do not exist or may have been unfamiliar to the interpreter.
The dataset is also missing occasional sentences from the original Wikipedia articles. While the ASL interpreters were asked to record translations of entire Wikipedia articles, occasionally portions were skipped, and some additional videos were removed during cleaning. To validate the data, the research team manually reviewed a random sample of videos from each contributor, ran scripts to check for invalid recordings, and manually examined outliers. Removed videos were: 110 with webcam failure, 500 corrupted, 19 with large discrepancies in text and recording length (video < 3s, text ≥5 words), 1 large outlier (>1000s), and 7 shorter than 1s.
Is the dataset self-contained, or does it link to or otherwise rely on external resources (e.g., websites, tweets, other datasets)? If it links to or relies on external resources, a) are there guarantees that they will exist, and remain constant, over time; b) are there official archival versions of the complete dataset (i.e., including the external resources as they existed at the time the dataset was created); c) are there any restrictions (e.g., licenses, fees) associated with any of the external resources that might apply to a future user? Please provide descriptions of all external resources and any restrictions associated with them, as well as links or other access points, as appropriate.
The videos correspond to English Wikipedia articles. We provide the mapping between ASL videos and English text. The Wikipedia text has been published under a Creative Contents license, and is available for public download (https://en.wikipedia.org/wiki/Wikipedia:Database_download (opens in new tab), July 2020).
Does the dataset contain data that might be considered confidential (e.g., data that is protected by legal privilege or by doctor-patient confidentiality, data that includes the content of individuals non-public communications)? If so, please provide a description.
No, the data is not confidential. All participants consented to providing recordings and public release of the dataset.
Does the dataset contain data that, if viewed directly, might be offensive, insulting, threatening, or might otherwise cause anxiety? If so, please describe why.
No, we do not expect contents to be offensive. The topic is STEM.
Does the dataset relate to people? If not, you may skip the remaining questions in this section.
Yes, the videos are of sign language interpreters.
Does the dataset identify any subpopulations (e.g., by age, gender)? If so, please describe how these subpopulations are identified and provide a description of their respective distributions within the dataset.
The people in the videos are professional ASL interpreters.
Is it possible to identify individuals (i.e., one or more natural persons), either directly or indirectly (i.e., in combination with other data) from the dataset? If so, please describe how.
Yes, it is possible to identify individuals in the dataset, since the interpreters’ faces and upper bodies are captured in the videos.
Does the dataset contain data that might be considered sensitive in any way (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history)? If so, please provide a description.
The data may be considered sensitive, in that the interpreters’ faces and upper bodies are captured in the videos.
Any other comments?
N/A
Collection Process
How was the data associated with each instance acquired? Was the data directly observable (e.g., raw text, movie ratings), reported by subjects (e.g., survey responses), or indirectly inferred/derived from other data (e.g., part-of-speech tags, model-based guesses for age or language)? If data was reported by subjects or indirectly inferred/derived from other data, was the data validated/verified? If so, please describe how.
Professional interpreters recorded each video, which was automatically linked to the corresponding English text. This process was facilitated by a web platform that the research team created for this collection (described subsequently).
What mechanisms or procedures were used to collect the data (e.g., hardware apparatus or sensor, manual human curation, software program, software API)? How were these mechanisms or procedures validated?
The data was collected through a website created explicitly for this dataset collection. The platform provides a full English text on the right side of the screen. The interpreters have full access to the text, and can progress through the text and record themselves providing a translation in the website. A record button is available, which triggers recording through their computer’s webcam. The interface also supported playing back recordings and re-recording. The resulting translations are available for content consumers to view, for example to enable access to spot-translations to improve article accessibility to people whose primary language is ASL. The full platform design is described in [1].
If the dataset is a sample from a larger set, what was the sampling strategy (e.g., deterministic, probabilistic with specific sampling probabilities)?
N/A
Who was involved in the data collection process (e.g., students, crowdworkers, contractors) and how were they compensated (e.g., how much were crowdworkers paid)?
Microsoft Research designed and built the collection platform. Professional interpreters provided recorded translations through the web platform. The interpreters were paid at standard hourly ASL interpreter rates for virtual interpretation jobs.
Over what timeframe was the data collected? Does this timeframe match the creation timeframe of the data associated with the instances (e.g., recent crawl of old news articles)? If not, please describe the timeframe in which the data associated with the instances was created.
The videos were collected between March and June 2022.
Were any ethical review processes conducted (e.g., by an institutional review board)? If so, please provide a description of these review processes, including the outcomes, as well as a link or other access point to any supporting documentation.
Yes, the project was reviewed by Microsoft’s Institutional Review Board (IRB). The collection platform and the dataset release also underwent additional Ethics and Compliance reviews by Microsoft.
Does the dataset relate to people? If not, you may skip the remaining questions in this section.
Yes, the dataset consists of videos of human ASL interpreters.
Did you collect the data from the individuals in question directly, or obtain it via third parties or other sources (e.g., websites)?
The videos were recorded by the ASL interpreters.
Were the individuals in question notified about the data collection? If so, please describe (or show with screenshots or other information) how notice was provided, and provide a link or other access point to, or otherwise reproduce, the exact language of the notification itself.
Yes, the interpreters controlled the recording process (e.g. start, stop, re-recording). A screenshot of the recording interface is provided in Figure 3 of [1]. Contributors also engaged in a consent process prior to contributing any data.
Did the individuals in question consent to the collection and use of their data? If so, please describe (or show with screenshots or other information) how consent was requested and provided, and provide a link or other access point to, or otherwise reproduce, the exact language to which the individuals consented.
Yes, participants engaged in a consent process through the web platform prior to contributing. For the exact consent text, please visit https://www.microsoft.com/en-us/research/project/asl-stem-wiki/.
If consent was obtained, were the consenting individuals provided with a mechanism to revoke their consent in the future or for certain uses? If so, please provide a description, as well as a link or other access point to the mechanism (if appropriate).
Yes, participants could contact the research team directly, and could delete any of their recordings through the web platform.
Has an analysis of the potential impact of the dataset and its use on data subjects (e.g., a data protection impact analysis) been conducted? If so, please provide a description of this analysis, including the outcomes, as well as a link or other access point to any supporting documentation.
Yes, a Data Protection Impact Analysis (DPIA) has been conducted, including taking a detailed inventory of the data types collected and stored and retention policy, and was successfully reviewed by Microsoft.
Any other comments?
N/A
Preprocessing/cleaning/labelling
Was any preprocessing/cleaning/labeling of the data done (e.g., discretization or bucketing, tokenization, part-of-speech tagging, SIFT feature extraction, removal of instances, processing of missing values)? If so, please provide a description. If not, you may skip the remainder of the questions in this section.
To validate the data, the research team manually reviewed a random sample of videos from each contributor, ran scripts to check for invalid recordings, and manually examined outliers. Removed videos were: 110 with webcam failure, 500 corrupted, 19 with large discrepancies in text and recording length (video < 3s, text ≥5 words), 1 large outlier (>1000s), and 7 shorter than 1s.
Was the “raw” data saved in addition to the preprocessed/cleaned/labeled data (e.g., to support unanticipated future uses)? If so, please provide a link or other access point to the “raw” data.
No, not publicly.
Is the software used to preprocess/clean/label the instances available? If so, please provide a link or other access point.
No, but these procedures are easily reproducible using public software.
Any other comments?
N/A
Uses
Has the dataset been used for any tasks already? If so, please provide a description.
Yes, we provide fingerspelling detection and alignment baselines in the accompanying paper publication.
Is there a repository that links to any or all papers or systems that use the dataset? If so, please provide a link or other access point.
Yes, the link is available on our project page at https://www.microsoft.com/en-us/research/project/asl-stem-wiki/.
What (other) tasks could the dataset be used for?
The dataset can be used for a range of tasks, including:
Fingerspelling detection and recognition – Our dataset reflects an increased usage of fingerspelling in interpretations of STEM documents. Identifying instances of fingerspelling and mapping these instances onto the corresponding English words can help researchers better understand signing patterns. We provide benchmarks for fingerspelling detection and recognition in our paper accompanying the dataset release. The ability to detect and recognize fingerspelling can also enable richer downstream applications, such as automatic sign suggestion (described subsequently).
Automatic sign suggestion – Also motivated by the prevalence of fingerspelling in STEM interpretations, we suggest developing systems to detect when fingerspelling is used and suggest appropriate ASL signs to use instead. Suggestions would be dependent on the domain and context (e.g. «protein» in the context of nutrition, structural biology, or protein engineering may have distinct ASL signs), as well as on the audience (e.g. the sign to use for an elementary school class may be different from the sign to use with a college audience). Fingerspelling may be appropriate in some cases as well, for example when introducing a new sign that is not well-known.
Translationese/Interpretese – Because our dataset is prompted from an English source sentence, it is prone to having effects of translationese [2], such as English-influenced word order, segmentation of ASL into English sentence boundaries, signs for English homonyms being used instead of the appropriate sign, and increased fingerspelling. We propose training models to detect and repair translationese, as well as potential translation and interpretation studies around interpretese [3] of ASL.
Sign variation – Five of our articles are interpreted by all 37 ASL interpreters in our study. These articles provide a unique opportunity to study variations in how individuals sign and interpret the same English sentence, especially STEM concepts where ASL signs are not stabilized.
Sign linking/retrieval – Related to sign variation, our dataset contains examples of English words that may be interpreted differently across interpreters and context. This data can be used to train models that links different versions of ASL signs for the same concept (e.g. one interpreter may sign «electromagnetism» using the signs for ELECTRICITY and MAGNET, another interpreter may interpret the same word using a sign that visually describes an electromagnetic field).
Automatic STEM translation – Our dataset can be used to train, fine-tune, and/or evaluate model capabilities in translating technical content from English to ASL. Technically, our dataset could be used to develop models to translate from ASL to English, however, this direction is not preferred since our dataset contains interpreted ASL which may differ from unprompted ASL [3].
Is there anything about the composition of the dataset or the way it was collected and preprocessed/cleaned/labeled that might impact future uses? For example, is there anything that a future user might need to know to avoid uses that could result in unfair treatment of individuals or groups (e.g., stereotyping, quality of service issues) or other undesirable harms (e.g., financial harms, legal risks) If so, please provide a description. Is there anything a future user could do to mitigate these undesirable harms?
Dataset users should be aware that the dataset does not consist of natural ASL content. Because the translations were made from English to ASL, the former language likely influences the secondary language (e.g. in grammatical structures). The English text was also segmented into sentence units, forcing the translation to occur sentence-by-sentence, which further constrained the flexibility and naturalness of the ASL. Additionally, because the content is STEM-related and sometimes technical, fingerspelling is often used to represent concepts where signs do not exist or may have been unfamiliar to the interpreter.
It is possible that some of these limitations may be reduced in the future by post-processing or correcting the videos, by combining this dataset with other datasets that do consist of natural ASL-first contents, or by incorporating linguistic knowledge in modeling. Involving fluent ASL team members in key roles in projects can help mediate risks, for example to provide feedback on signing quality, community needs and perspectives, and other relevant guidance and information.
Are there tasks for which the dataset should not be used? If so, please provide a description.
As described above, this dataset is not an example of natural ASL-first signing. As a result, we do not recommend using this dataset alone to understand or model natural ASL-first signing. At a minimum, this dataset would need to be used in conjunction with other datasets and/or domain knowledge about sign language in order to more accurately model naturalistic ASL.
More generally, we recommend using this data with meaningful involvement from Deaf community members in leadership roles with decision-making authority at every step from conception to execution. As described in other works, research and development of sign language technologies that involves Deaf community members increases the quality of the work, and can help to ensure technologies are relevant and wanted. Historically, projects developed without meaningful Deaf involvement have not been well received [4] and have damaged relationships between technologists and deaf communities.
We ask that this dataset is used with an aim of making the world more equitable and just for deaf people, and with a commitment to «do no harm». In that spirit, this dataset should not be used to develop technology that purports to replace sign language interpreters, fluent signing educators, and/or other hard-won accommodations for deaf people.
Any other comments?
N/A
Distribution
Will the dataset be distributed to third parties outside of the entity (e.g., company, institution, organization) on behalf of which the dataset was created? If so, please provide a description.
Yes, the dataset is released publicly, to help advance research and development related to sign language.
How will the dataset will be distributed (e.g., tarball on website, API, GitHub)? Does the dataset have a digital object identifier (DOI)?
The dataset is publicly available for download through the Microsoft Download Center. Links are available through the project page at https://www.microsoft.com/en-us/research/project/asl-stem-wiki/.
When will the dataset be distributed?
The dataset was released on 10/15/2024.
Will the dataset be distributed under a copyright or other intellectual property (IP) license, and/or under applicable terms of use (ToU)? If so, please describe this license and/or ToU, and provide a link or other access point to, or otherwise reproduce, any relevant licensing terms or ToU, as well as any fees associated with these restrictions.
Yes, the dataset will be published under a license that permits use for research purposes. The license is provided at https://www.microsoft.com/en-us/research/project/asl-stem-wiki/dataset-license/.
Have any third parties imposed IP-based or other restrictions on the data associated with the instances? If so, please describe these restrictions, and provide a link or other access point to, or otherwise reproduce, any relevant licensing terms, as well as any fees associated with these restrictions.
The Wikipedia article texts are multi-licensed under the Creative Commons Attribution-ShareAlike 3.0 License (CC-BY-SA) and the GNU Free Documentation License (GFDL).
Do any export controls or other regulatory restrictions apply to the dataset or to individual instances? If so, please describe these restrictions, and provide a link or other access point to, or otherwise reproduce, any supporting documentation.
No.
Any other comments?
N/A
Maintenance
Who will be supporting/hosting/maintaining the dataset?
The dataset will be hosted on Microsoft Download Center.
How can the owner/curator/manager of the dataset be contacted (e.g., email address)?
Please contact [email protected] with any questions.
Is there an erratum? If so, please provide a link or other access point.
A public-facing website is associated with the dataset (see https://www.microsoft.com/en-us/research/project/asl-stem-wiki/). We will link to erratum on this website if necessary.
Will the dataset be updated (e.g., to correct labeling errors, add new instances, delete instances)? If so, please describe how often, by whom, and how updates will be communicated to users (e.g., mailing list, GitHub)?
If updates are necessary, we will update the dataset. We will release our dataset with a version number, to distinguish it with any future updated versions.
If the dataset relates to people, are there applicable limits on the retention of the data associated with the instances (e.g., were individuals in question told that their data would be retained for a fixed period of time and then deleted)? If so, please describe these limits and explain how they will be enforced.
The dataset will be left up indefinitely, to maximize utility to research. Participants were informed that their contributions might be released in a public dataset.
Will older versions of the dataset continue to be supported/hosted/maintained? If so, please describe how. If not, please describe how its obsolescence will be communicated to users.
All versions of the dataset will be released with a version number on Microsoft Download Center to enable differentiation.
If others want to extend/augment/build on/contribute to the dataset, is there a mechanism for them to do so? If so, please provide a description. Will these contributions be validated/verified? If so, please describe how. If not, why not? Is there a process for communicating/distributing these contributions to other users? If so, please provide a description.
We do not have a mechanism for others to contribute to our dataset directly. However, others could create comparable datasets by recording ASL translations of English texts.
Any other comments?
N /A
References
[1] Abraham Glasser, Fyodor Minakov, and Danielle Bragg. ASL Wiki: An Exploratory Interface for Crowdsourcing ASL Translations. In Proceedings of the 24th International ACM SIGACCESS Conference on Computers and Accessibility, pages 1–13, 2022.
[2] Moshe Koppel and Noam Ordan. Translationese and Its Dialects. In Proceedings of the 49th annual meeting of the Association for Computational Linguistics: Human Language Technologies, pages 1318–1326, 2011.
[3] Miriam Shlesinger. Towards a Definition of Interpretese: An intermodal, corpus-based study. Efforts and Models in Interpreting and Translation Research. A Tribute to Daniel Gile. Amsterdam/Philadelphia: John Benjamins, pages 237–253, 2009.
[4] Michael Erard. Why Sign-Language Gloves Don’t Help Deaf People. 2017.