
新闻与深度文章

| Hoifung Poon, Theodore Zhao, Aiden Gu, Mu Wei, 和 Sheng Wang
BiomedParse reimagines medical image analysis, integrating advanced AI to capture complex insights across imaging types—a step forward for diagnostics and precision medicine.

In this issue: CaaSPER: vertical autoscaling algorithm dynamically maintains optimal CPU utilization; Improved scene landmark detection for camera localization runs faster, uses less storage; ESUS simplifies usability questionnaires for technical products and services.

We’re proud to have 100+ accepted papers At NeurIPS 2023, plus 18 workshops. Several submissions were chosen as oral presentations and spotlight posters, reflecting groundbreaking concepts, methods, or applications. Here’s an overview of those submissions.

New evaluation methods and a commitment to continual improvement are musts if we’re to build multimodal AI systems that advance human goals. Learn about cutting-edge research into the responsible development and use of multimodal AI at Microsoft.

Large language models (LLMs), such as ChatGPT, are able to generate human-like, fluent responses for many downstream tasks, e.g., task-oriented dialog and question answering. However, applying LLMs to real-world, mission-critical applications remains challenging mainly due to their tendency to generate…

Welcome to Research Focus, a new series of blog posts that highlights notable publications, events, code/datasets, new hires and other milestones from across the research community at Microsoft. Barun Patra, Saksham Singhal, Shaohan Huang, Zewen Chi, Li Dong, Furu Wei,…

Human eyes have a dynamic focusing system that adjusts the focal regions in order to see the surroundings at all distances. When we look far away, up close, and back again, our eyes change focus rapidly to allow us to…

Website: https://computer-vision-in-the-wild.github.io/eccv-2022/ (opens in new tab) Workshop: The research community has recently witnessed a trend in building transferable visual models that can effortlessly adapt to a wide range of downstream computer vision (CV) and multimodal (MM) tasks. We are organizing…
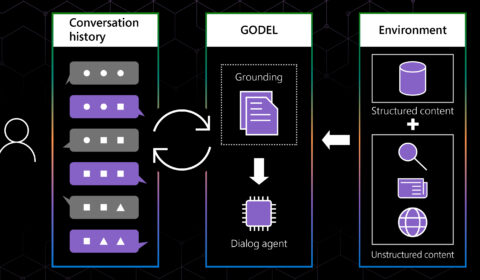
| Baolin Peng, Michel Galley, Lars Liden, Chris Brockett, Zhou Yu, 和 Jianfeng Gao
They make restaurant recommendations, help us pay bills, and remind us of appointments. Many people have come to rely on virtual assistants and chatbots to perform a wide range of routine tasks. But what if a single dialog agent, the…