

PACT paper (opens in new tab) | Video (opens in new tab)| Github code (opens in new tab)
Recent advances in machine learning architectures have induced a paradigm shift from task-specific models towards large general-purpose networks. For instance, in the past few years we have witnessed a revolution in the domains of natural language and computer vision with models such as GPT-3 (opens in new tab), BERT (opens in new tab) and DALL-E (opens in new tab). The use of general-purpose models is highly appealing because they are trained on a broad array of datasets and can be applied to a wide variety of downstream tasks, therefore providing general skills which can be used directly or with minimal finetuning to new applications.
The field of robotics, however, is still mostly riddled with single-purpose systems architectures whose modules and connections, whether traditional or learning-based, require significant human design expertise. Inspired by these large pre-trained models, this work introduces a general-purpose robotics representation that can serve as a starting point for multiple tasks for a mobile agent, such as navigation, mapping and localization.
We present the Perception-Action Causal Transformer (PACT), a generative transformer-based architecture that aims to build representations directly from robot data in a self-supervised fashion. Through autoregressive prediction of states and actions over time, our model implicitly encodes dynamics and behaviors for a particular robot. This representation can then function as a single starting point to achieve distinct tasks through fine-tuning with minimal data.

Continue reading to learn more about this technology, or check out these additional resources:
- Read the technical details of PACT in the paper (opens in new tab)
- View our machine learning models on the open-sourced Github repository (opens in new tab)
- Watch the video below:
Unlocking self-supervision of representations for robotics
Inspired by large pretrained language models, this work introduces a paradigm for pretraining general purpose representation models that can be used for multiple robotics tasks.
At their core, most robotic agents process a perception-action loop between their states/observations, and associated actions. We argue that if a robot can fully understand the transitions associated with states and actions, that leads to the ability of learning a high-quality mental model of how the robot interacts with the world. Conceptually, this is equivalent to how a large language model understands the rules of grammar in a language.
In this work we introduce the Perception-Action Causal Transformer (PACT), a Transformer-based generative model that is trained on sequences of states and actions coming from datasets of robot trajectories. By learning to autoregressively predict such sequences, PACT implicitly encodes general purpose information such as the progression of observations given actions (robot dynamics), and interactions between states and actions (robot policy).
State observations in robotics can be composed of distinct modalities such as RGB images or LiDAR scans. Similarly, robot actions can be of several types as well – such as steering angles, motor commands, or discrete choices from a predefined library of actions. In order to convert such a wide variety of data into a format that is easily accessible by the transformer, we use a tokenization procedure. PACT itself is designed to be a general architecture, and is agnostic to the nature of states and actions:

What can we do with this model?
Analogous to how a language model like GPT-3 learns to auto-regressively output a sequence of reasonable words to complete a sentence, the pretrained PACT model learns to output a reasonable sequence of actions for a robot. Without a particular goal in mind, it learns to follow the perception-action statistical distributions seen in the pretraining phase, and can navigate safely in the environment.

As mentioned before, downstream tasks in robotics can take several forms beyond just safe navigation. We finetune the representations learned by PACT for various tasks which are common in robotics scenarios such as localization, mapping, and navigation, for two types of robots. The first is the MuSHR car (opens in new tab), which is an open-sourced RC car platform equipped with cameras, LiDAR and onboard computers. The second robot is a purely virtual agent in the Habitat (opens in new tab) simulator.


For each downstream task, we add a small task-specific downstream module on top of the PACT model which is finetuned with the downstream datasets. Through empirical analysis, we observe that this method of learning finetuning small task-specific modules on top of PACT is significantly more efficient than training models from scratch for each task. The next figure shows examples of networks used for localization (merging embeddings from a pair of consecutive states), and local mapping (merging all embeddings from the transformer sequence):


PACT as a generative robotics model:
Similar to how a model like GPT-3 operates with text prompts, we can also bias the future distribution of states and actions produced by our model by prompting the transformer sequence with specific initial values. The next figure displays heatmaps with state distributions for multiple runs where the car was initialized in the same position and orientation, and the only difference being the prompting of the very first 15 action tokens. The figure highlights that prompting with straight trajectories results in future actions that tend to keep the vehicle on a straighter course when compared to the actions that are generated from prompts including turns:
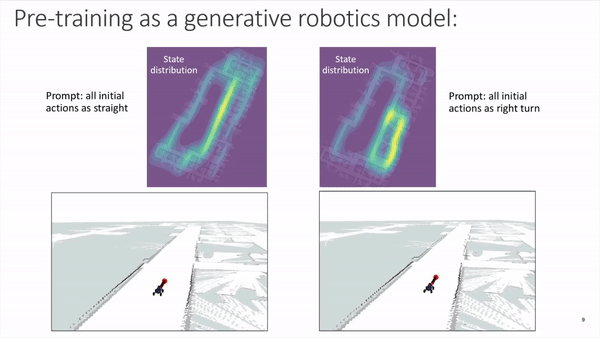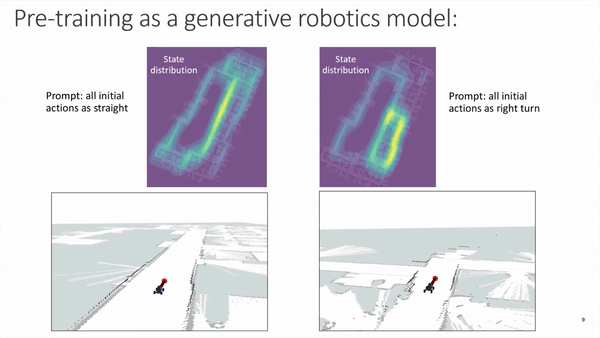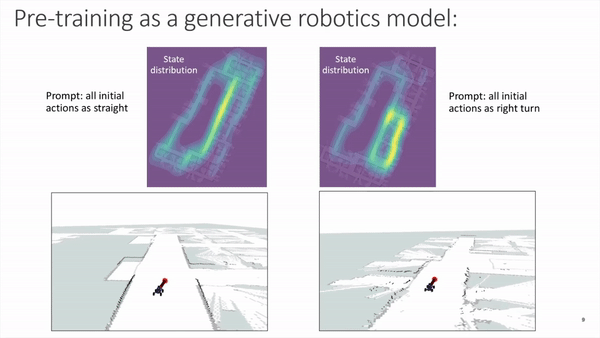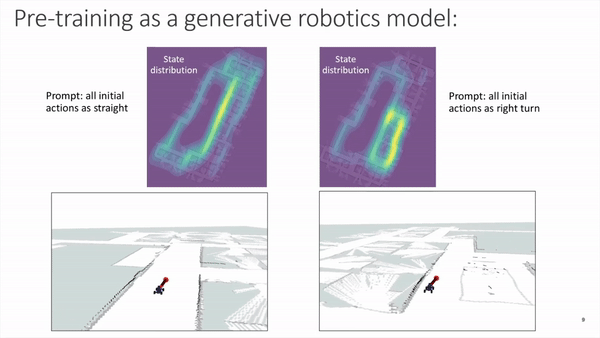
Making robotics more accessible
We are excited to release these technologies with the aim of bringing autonomous robotics closer to a broader public audience. Our goal is to allow anyone to easily “train the brains of a robot”, without the need for very specialized technical knowledge on the design of features and model architectures. Our Perception-Action Causal Transformer (PACT) framework, which facilitates the idea of a single starting point for a variety of robotics tasks, takes a big step forward towards this direction.
This work is being undertaken by a team at Microsoft Autonomous Systems and Robotics Research. The researchers included in this project are: Rogerio Bonatti, Sai Vemprala, Shuang Ma, Felipe Vieira Frujeri, Shuhang Chen and Ashish Kapoor.