

Humans understand the world by perceiving and fusing information from multiple channels, such as images viewed by the eyes, voices heard by the ears, and other forms of sensory input. One of the core aspirations in AI is to develop algorithms that endow computers with a similar ability: to effectively learn from multimodal data like vision-language to make sense of the world around us. For example, vision-language (VL) systems allow searching the relevant images for a text query (or vice versa) and describing the content of an image using natural language.
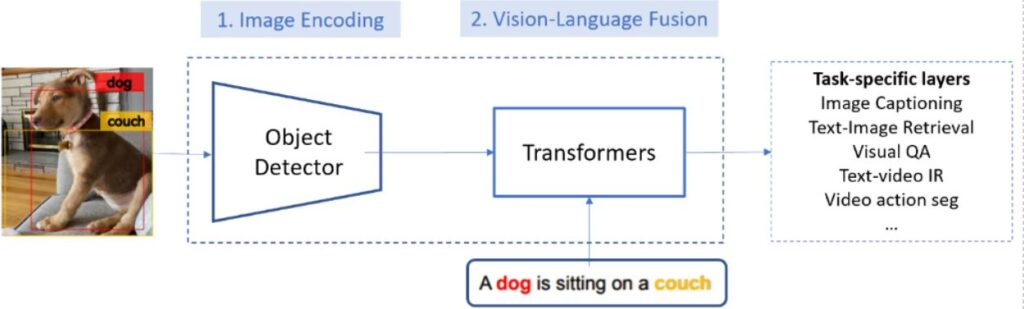
As illustrated in Figure 1, a typical VL system uses a modular architecture with two modules to achieve VL understanding:
- An image encoding module, also known as a visual feature extractor, is implemented using convolutional neural network (CNN) models to generate feature maps of input image. The CNN-based object detection model trained on the Visual Genome (VG) dataset is the most popular choice before our work.
- A vision-language fusion module maps the encoded image and text into vectors in the same semantic space so that their semantic similarity can be computed using cosine distance of their vectors. The module is typically implemented using a Transformer-based model, such as OSCAR.
Recently, vision-language pretraining (VLP) has made great progress in improving the vision-language fusion module by pretraining it on a large-scale paired image-text corpus. The most representative approach is to train large Transformer-based models on massive image-text pair data in a self-supervised manner, for example, predicting the masked elements based on their context. The pretrained vision-language fusion model can be fine-tuned to adapt to various downstream vision-language tasks. However, existing VLP methods treat the image encoding module as a black box and leave the visual feature improvement untouched since the development of the classical bottom-up region features in 2017, despite that there has been much research progress on improving image encoding and object detection.
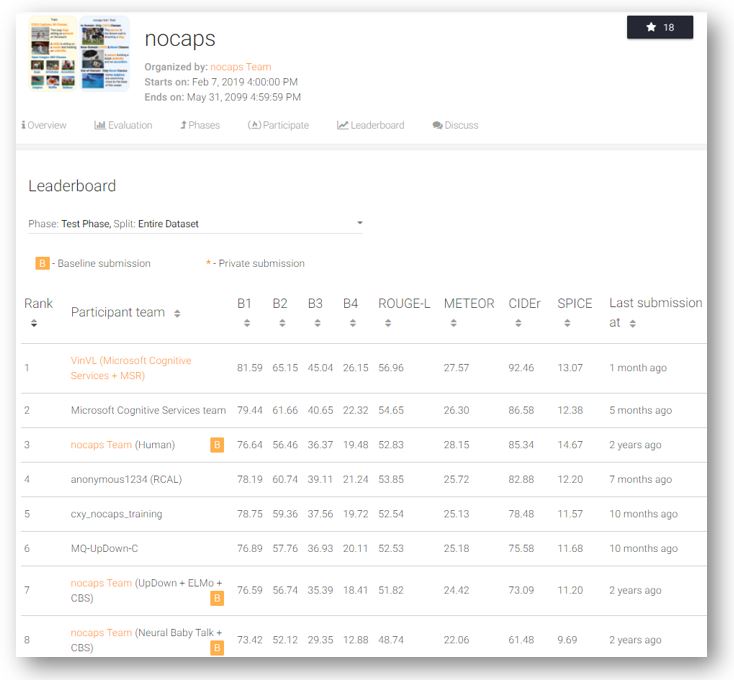
Here, we introduce recent Microsoft work on improving the image encoding module. Researchers from Microsoft have developed a new object-attribute detection model for image encoding, dubbed VinVL (Visual features in Vision-Language), and performed a comprehensive empirical study to show that visual features matter significantly in VL models. Combining VinVL with state-of-the-art VL fusion modules such as OSCAR (opens in new tab)and VIVO (opens in new tab), the Microsoft VL system sets new state of the art on all seven major VL benchmarks, achieving top position in the most competitive VL leaderboards, including Visual Question Answering (VQA) (opens in new tab), Microsoft COCO Image Captioning (opens in new tab), and Novel Object Captioning (nocaps) (opens in new tab). Most notably, the Microsoft VL system significantly surpasses human performance on the nocaps leaderboard in terms of CIDEr (92.5 vs. 85.3).
Microsoft will release the VinVL model and the source code to the public. Please refer to the research paper and GitHub repository. In addition, VinVL is being integrated into the Azure Cognitive Services, powering a wide range of multimodal scenarios (such as Seeing AI, Image Captioning in Office and LinkedIn, and others) to benefit millions of users through the Microsoft AI at Scale initiative.
VinVL: A generic object-attribute detection model
As opposed to classical computer vision tasks such as object detection, VL tasks require understanding more diverse visual concepts and aligning them with corresponding concepts in the text modality. On one hand, most popular object detection benchmarks (such as COCO, Open Images, Objects365) contain annotations for up to 600 object classes, mainly focusing on objects with a well-defined shape (such as car, person) but missing visual objects occupying amorphous regions (such as grass, sky), which are typically useful for describing an image. The limited and biased object classes make these object detection datasets insufficient for training very useful VL understanding models for real-world applications. On the other hand, although the VG dataset has annotations for more diverse and unbiased object and attribute classes, it contains only 110,000 images and is statistically too small to learn a reliable image encoding model.
To train our object-attribute detection model for VL tasks, we constructed a large object detection dataset containing 2.49M images for 1,848 object classes and 524 attribute classes, by merging four public object detection datasets, that is, COCO, Open Images, Objects365 and VG. As most datasets do not have attribute annotations, we adopted a pretraining and fine-tuning strategy to build our object-attribute detection model. We first pretrained an object detection model on the merged dataset, and then fine-tuned the model with an additional attribute branch on VG, making it capable of detecting both objects and attributes. The resultant object-attribute detection model is a Faster-RCNN model with 152 convolutional layers and 133M parameters, which is the largest image encoding model for VL tasks reported.
Spotlight: On-demand video

AI Explainer: Foundation models and the next era of AI
Explore how the transformer architecture, larger models and more data, and in-context learning have helped advance AI from perception to creation.
Our object-attribute detection model can detect 1,594 object classes and 524 visual attributes. As a result, the model can detect and encode nearly all the semantically meaningful regions in an input image, according to our experiments. As illustrated in Figure 2, compared with detections of a classical object detection model (left), our model (right) can detect more visual objects and attributes in an image and encode them with richer visual features, which are crucial for a wide range of VL tasks.

State-of-the-art performance on vision-language tasks
Since the image encoding module is fundamental to VL systems, as illustrated in Figure 1, our new image encoding can be used together with many existing VL fusion modules to improve the performance of VL tasks. For example, as reported in Table 1, by simply replacing visual features produced by the popular bottom-up model with the ones produced by our model, but keeping the VL fusion module (for example, OSCAR and VIVO) intact1, we observe significant improvement on all seven established VL tasks, often outperforming previous SoTA models by a significantly large margin.
[1] Note that we still perform training for the VL fusion module, but use the same model architecture, training data, and training recipe.

To account for parameter efficiency, we compare models of different sizes in Table 2. Our base model outperforms previous large models on most tasks, indicating that with better image encoding the VL fusion module can be much more parameter efficient.

Our new VL models, which consist of the new object-attribute detection model as its image encoding module and OSCAR as its VL fusion module, sit comfortably atop several AI benchmarks as of December 31, 2020, including Visual Question Answering (VQA) (opens in new tab), Microsoft COCO Image Captioning (opens in new tab), and Novel Object Captioning (nocaps) (opens in new tab). Most notably, our VL model performance on nocaps substantially surpasses human performance in terms of CIDEr (92.5 vs. 85.3). On the GQA benchmark (opens in new tab), our model is also the first VL model that outperforms NSM, which contains some sophisticated reasoning components deliberately designed for that specific task.


Looking forward
VinVL has demonstrated great potential in improving image encoding for VL understanding. Our newly developed image encoding model can benefit a wide range of VL tasks, as illustrated by examples in this paper. Despite the promising results we obtained, such as surpassing human performance on image captioning benchmarks, our model is by no means reaching the human-level intelligence of VL understanding. Interesting directions of future works include: (1) further scale up the object-attribute detection pretraining by leveraging massive image classification/tagging data, and (2) extend the methods of cross-modal VL representation learning to building perception-grounded language models that can ground visual concepts in natural language and vice versa like humans do.
Acknowledgments: This research was conducted by Pengchuan Zhang, Xiujun Li, Xiaowei Hu, Jianwei Yang, Lei Zhang, Lijuan Wang, Yejin Choi, and Jianfeng Gao. Additional thanks go to the Microsoft Research Service Engineering Group for providing computer resources for large-scale modeling. The baseline models used in our experiments are based on the open-source code released in the GitHub repository; we acknowledge all the authors who made their code public, which tremendously accelerates our project progress.


