Cloud Intelligence/AIOps blog series, part 4
In the previous posts in this series, we introduced our research vision for Cloud Intelligence/AIOps (part 1) and how advanced AI can help design, build, and manage large-scale cloud platforms effectively and efficiently; we looked at solutions that are making many aspects of cloud operations more autonomous and proactive (part 2); and we discussed an important aspect of cloud management: RL-based tuning of application configuration parameters (part 3). In this post, we focus on the broader challenges of autonomously managing the entire cloud platform.
In an ideal world, almost all operations of a large-scale cloud platform would be autonomous, and the platform would always be at, or converging to, the operators’ desired state. However, this is not possible for a variety of reasons. Cloud applications and infrastructure are incredibly complex, and they change too much, too fast. For the foreseeable future, there will continue to be problems that are novel and/or too complex for automated solutions, no matter how intelligent, to address. These may arise due to complex cascading or unlikely simultaneous failures, unexpected interactions between components, challenging (or malicious) changes in workloads such as the rapid increase in traffic due to the COVID pandemic, or even external factors such as the need to reduce power usage in a particular region.
At the same time, rapid advances in machine learning and AI are enabling an increase in the automation of several aspects of cloud operations. Our second post in this series listed a number of these, including detection or problematic deployments, fault localization, log parsing, diagnosis of failures, prediction of capacity, and optimized container reallocation.
Microsoft research podcast

What’s Your Story: Lex Story
Model maker and fabricator Lex Story helps bring research to life through prototyping. He discusses his take on failure; the encouragement and advice that has supported his pursuit of art and science; and the sabbatical that might inspire his next career move.

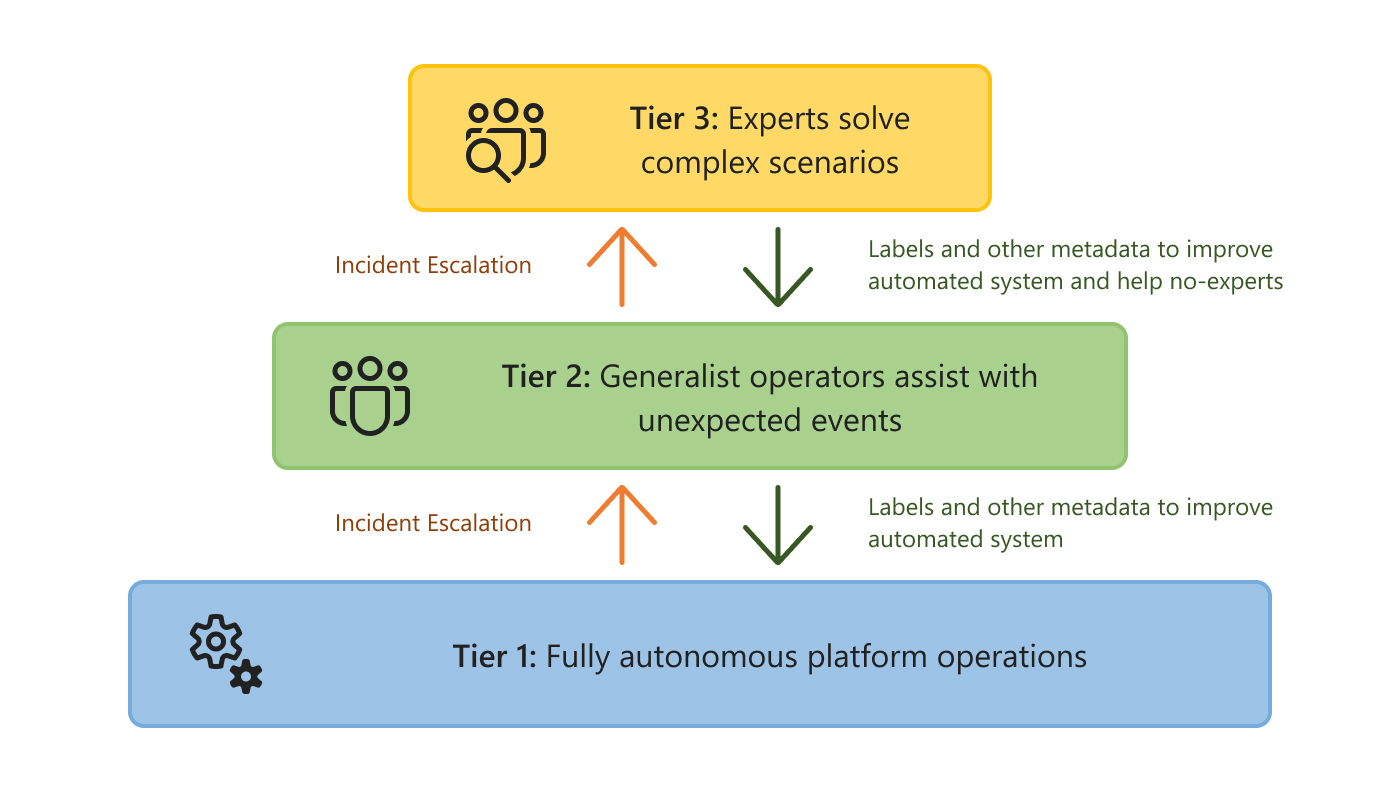
To reconcile these two realities, we introduce the concept of Tiered AIOps. The idea is to separate systems and issues into tiers of different levels of automation and human intervention. This separation comes in stages (Figure 1). The first stage has only two tiers: one where AI progressively automates routine operations and can mitigate and solve simple incidents without a human in the loop, and a second tier where expert human operators manage the long tail of incidents and scenarios that the AI systems cannot handle. As the AI in the first tier becomes more powerful, the same number of experts can manage larger and more complex cloud systems. However, this is not enough.
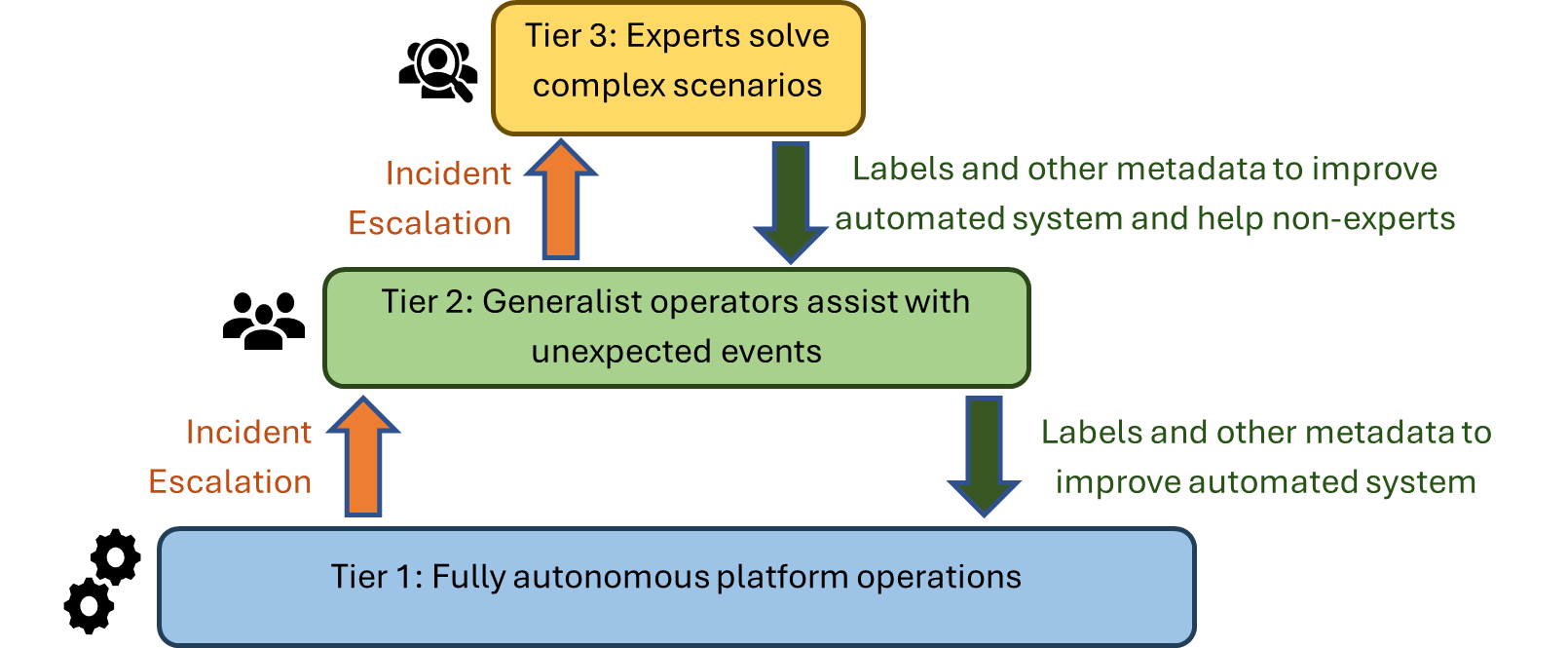
New AI tools enable a final, even more scalable stage, where human expertise can also be separated into two tiers. In this stage, the middle tier involves situations and problems that the AI in the first level cannot handle, but which can be solved by non-expert, generalist human operators. AI in this second tier helps these operators manage the platform by lowering the level of expertise needed to respond to incidents. For example, the AI could automatically localize the source of an incident, recommend mitigation actions, and provide risk estimates and explanations to help operators reason about the best mitigating action to take. Finally, the last tier relies on expert engineers for complex and high-impact incidents that automated systems and generalists are unable to solve. In other words, we have the following tiers (Figure 2):
- Tier 1: Fully autonomous platform operation. Automates what can be learned or predicted. Includes intelligent and proactive systems to prevent failures and resolution of incidents that follow patterns of past incidents.
- Tier 2: Infrastructure for non-expert operators to manage systems and incidents. Receives context from events and incidents that are not handled in the first tier. AI systems provide context, summaries, and mitigation recommendations to generalist operators.
- Tier 3: Infrastructure for experts to manage systems and incidents that are novel or highly complex. Receives context from events and incidents not handled in the first two tiers. Can enable experts to interact and manage a remote installation.
There are two types of AI systems involved: first, those that enable increasing levels of automation in the first and second tiers, and; second, the AI systems (different types of co-pilots) that assist operators. It is the latter type that enables the division between the second and third tiers, and also reduces the risk of imperfect or incomplete systems in the first tier. This separation between the top two tiers is also crucial for the operation of air-gapped clouds and makes it more feasible to deploy new datacenters in locations where there might not be the same level of expert operators.
The key idea in the Tiered AIOps concept is to simultaneously expand automation and increase the number of incidents that can be handled by the first tier, while recognizing that all three tiers are critical. The research agenda is to build systems and models to support automation and incident response in all three tiers.
Escalating incidents. Each tier must have safeguards to (automatically or not) escalate an issue to the next tier. For example, when the first tier detects that there is insufficient data, or that the confidence (risk) in a prediction is lower (higher) than a threshold, it should escalate, with the right context, to the next tier.
Migrating learnings. On the other hand, over time and with gained experience (which can be encoded in troubleshooting guides, new monitors, AI models, or better training data), repeated incidents and operations migrate toward the lower tiers, allowing operators to allocate costly expertise to highly complex and impactful incidents and decisions.
We will now discuss some work on extending the first tier with on-node learning, how to use new AI systems (large language models or simply LLMs) to assist operators in mitigating incidents and to move toward enabling the second tier, and, finally, how the third tier enables air-gapped clouds.
Tier 1: On-node learning
Managing a cloud platform requires control loops and agents with many different granularities and time scales. Some agents need to be located on individual nodes, either because of latency requirements of the decisions they make, or because they depend on telemetry that is too fine-grained and large to leave the node. Examples of these agents include configuration (credentials, firewalls, operating system updates), services like virtual machine (VM) creation, monitoring and logging, watchdogs, resource controls (e.g., power, memory, or CPU allocation), and access daemons.
Any agent that can use data about current workload characteristics or system state to guide dynamic adjustment of their behavior can potentially take advantage of machine learning (ML). However, current ML solutions such as Resource Central (SOSP’17) require data and decisions to run in a dedicated service outside of the server nodes. The problem is that for some agents this is not feasible, as they either have to make fast decisions or require data that cannot leave the node.
In SOL: Safe On-Node Learning in Cloud Platforms (ASPLOS’22), we proposed a framework that allows local agents to use modern ML techniques in a safe, robust, and effective way. We identified three classes of local agents that can benefit from ML. First, agents that assign resources (CPU, memory, power) benefit from near real-time workload information. Making these decisions quickly and with fine-grained telemetry enables better assignments with smaller impact to customer quality of service (QoS). Second, monitoring and logging agents, which must run on each node, can benefit from online learning algorithms, such as multi-armed bandits to smartly decide which telemetry data to sample and at which frequency, while staying within a sampling budget. Lastly, watchdogs, which monitor for metrics that indicate failures, can benefit from learning algorithms to detect problems and take mitigating actions sooner, as well as detect and diagnose more complex problems that simpler systems would not detect.
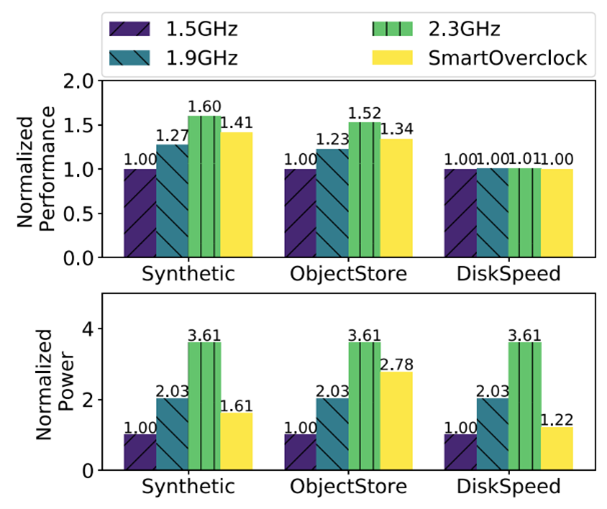
SOL makes it easy to integrate protections against invalid data, inaccurate or drifting AI models, and delayed predictions, and to add safeguards in the actions the models can take, through a simple interface. As examples, we developed agents to do CPU overclocking, CPU harvesting, and memory page hotness classification. In our experiments (Figure 3), the overclocking agent, for example, achieved near-peak normalized performance for different workloads, at nearly half of the power draw, while responding well to many failure conditions in the monitoring itself. See our paper for more details.
- Publication SOL: Safe On-Node Learning in Cloud Platforms
Tier 2: Incident similarity and mitigation with LLMs
As an example of how AI systems can enable the second tier, we are exploring how LLMs can help in mitigating and finding the root cause of incidents in cloud operations. When an incident happens in a cloud system, either generated by automated alarms or by customer-reported issues, a team of one or more on-call engineers must quickly find ways to mitigate the incident (resolving the symptoms), and then find the cause of the incident for a permanent fix and to avoid the incident in the future.
There are many steps involved in this process, and they are highly variable. There is also context that relates to the incident, which grows as both automated systems and on-call engineers perform tests, look at logs, and go through a cycle of forming, testing, and validating hypotheses. We are investigating using LLMs to help with several of these steps, including automatically generating summaries of the cumulative status of an incident, finding similar incidents in the database of past incidents, and proposing mitigation steps based on these similar incidents. There is also an ever-growing library of internal troubleshooting guides (TSGs) created by engineers, together with internal and external documentation on the systems involved. We are using LLMs to extract and summarize information from these combined sources in a way that is relevant to the on-call engineer.
We are also using LLMs to find the root cause of incidents. In a recent paper published in ISCE (2023), the Microsoft 365 Systems Innovation research group demonstrated the usefulness of LLMs in determining the root cause of incidents from the title and summary of the incident. In a survey conducted as part of the work, more than 70% of the on-call engineers gave a rating of 3 out of 5 or better on the usefulness of the recommendations in a real-time incident resolution setting.
There is still enormous untapped potential in using these methods, along with some interesting challenges. In aggregate, these efforts are a great step toward the foundation for the second tier in our vision. They can assist on-call engineers, enable junior engineers to be much more effective in handling more incidents, reduce the time to mitigation, and, finally, give room for the most expert engineers to work on the third tier, focusing on complex, atypical, and novel incidents.
Tier 3: Air-gapped clouds
We now turn to an example where the separation between the second and third tiers could enable significantly simplified operations. Air-gapped datacenters, characterized by their isolated nature and restricted access, provide a secure environment for managing sensitive data while prioritizing privacy. In such datacenters, direct access is limited and highly controlled, being operated locally by authorized employees, ensuring that data is handled with utmost care and confidentiality. However, this level of isolation also presents unique challenges when it comes to managing the day-to-day operations and addressing potential issues, as Microsoft’s expert operators do not have physical or direct access to the infrastructure.
In such an environment, future tiered AIOps could improve operations, while maintaining the strict data and communication isolation requirements. The first tier would play a critical role by significantly reducing the occurrence of incidents through the implementation of automated operations. However, the second and third tiers would be equally vital. The second tier would empower local operators on-site to address most issues that the first tier cannot. Even with AI assistance, there would be instances requiring additional expertise beyond that which is available locally. Unfortunately, the experts in the third tier may not even have access to remote desktops, or to the results of queries or commands. LLMs would serve a crucial role here, as they could become an ideal intermediary between tiers 2 and 3, sharing high-level descriptions of problems without sending sensitive information.
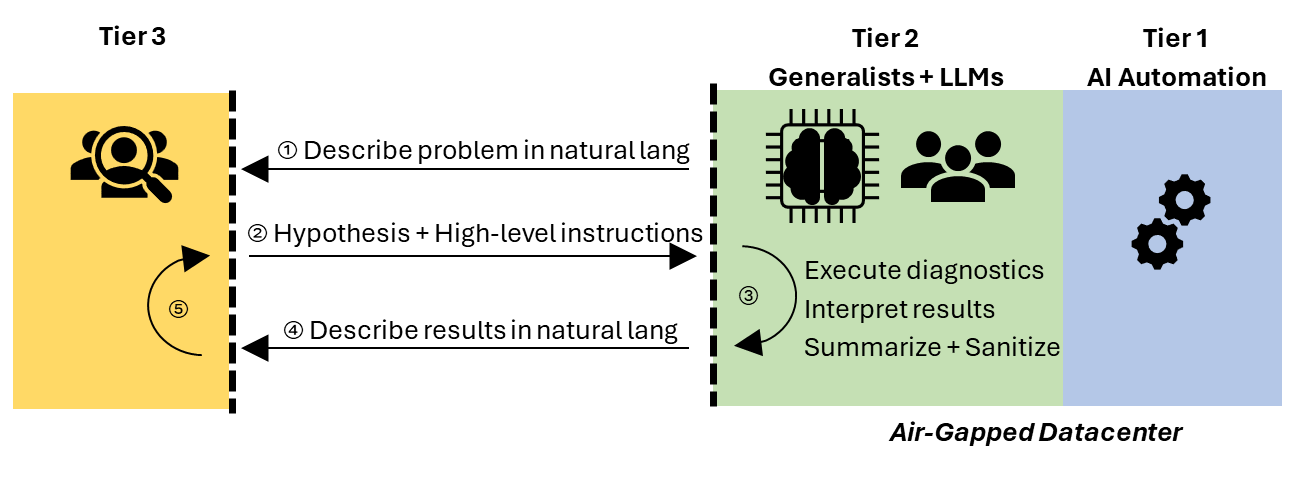
In an interactive session (Figure 4), an LLM with access to the air-gapped datacenter systems could summarize and sanitize the problem description in natural language (①). A remote expert in Tier 3 would then formulate hypotheses and send high-level instructions in natural language for more investigation or for mitigation (②). The LLM could use the high-level instructions to form a specialized plan. For example, it could query devices with a knowledge of the datacenter topology that the expert does not have; interpret, summarize, and sanitize the results (with or without the help of the generalist, on-site operators) (③); and send the interpretation of the results back to the experts, again in natural language (④). Depending on the problem, this cycle could repeat until the problem is solved (⑤). Crucially, while the operators at the air-gapped cloud would be in the loop, they wouldn’t need deep expertise in all systems to perform the required actions and interpret the results.
Conclusion
Cloud platform operators have seen massive, continuous growth in scale. To remain competitive and viable, we must decouple the scaling of human support operations from this growth. AI offers great hope in increasing automation of platform management, but because of constant change in the systems, environment, and demands, there will likely always be decisions and incidents requiring expert human input. In this post, we described our vision of Tiered AIOps as the way to enable and achieve this decoupling and maximize the effectiveness of both AI tools and human expertise.