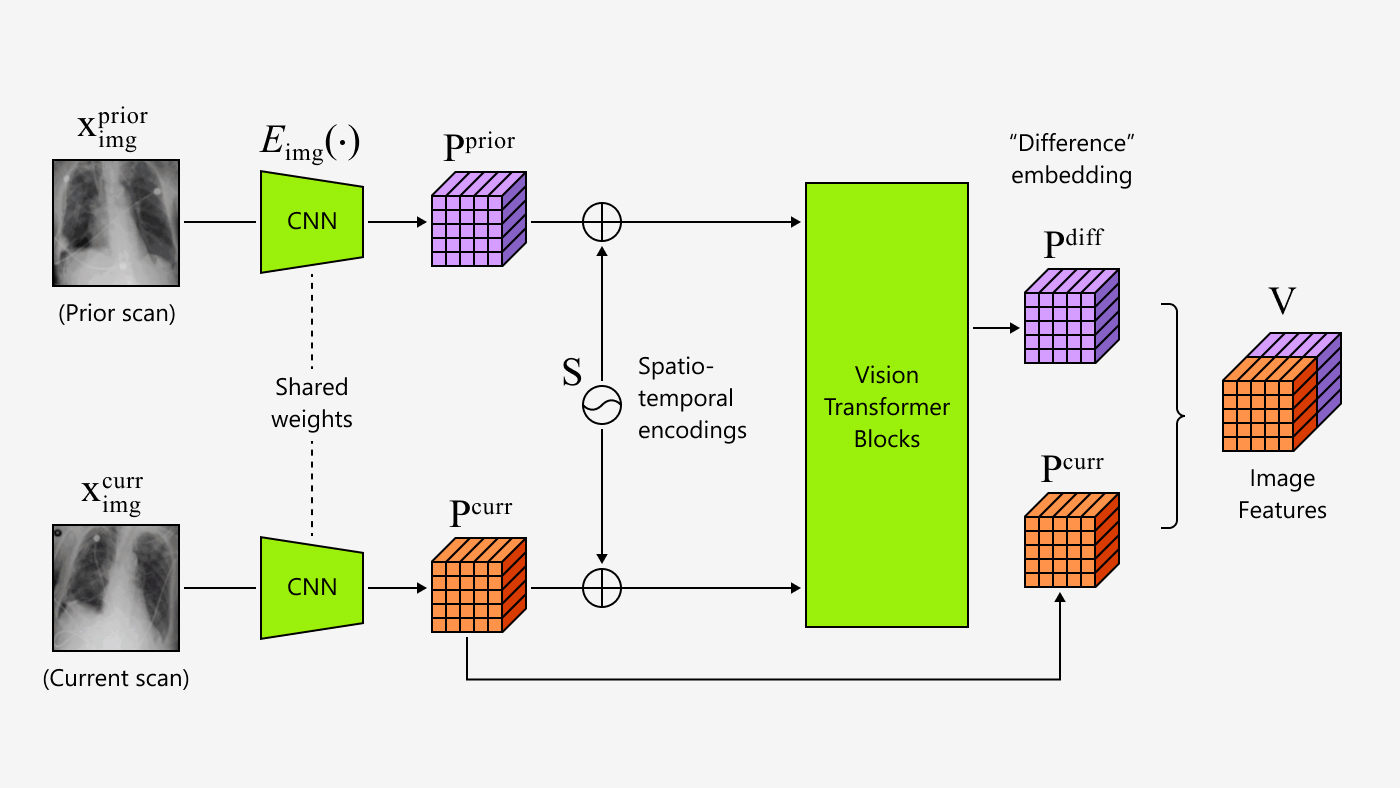
Today, the Microsoft Turing team (opens in new tab) is thrilled to introduce Turing Bletchley, a 2.5-billion parameter Universal Image Language Representation model (T-UILR) that can perform image-language tasks in 94 languages. T-Bletchley has an image encoder and a universal language encoder that vectorize input image and text respectively so that semantically similar images and texts align with each other. This model shows uniquely powerful capabilities and a groundbreaking advancement in image language understanding.
T-Bletchley outperforms state-of-the-art models, like Google’s ALIGN (opens in new tab), on English image-language data sets (ImageNet, CIFAR, and COCO), and outperforms MULE, (opens in new tab) SMALR, (opens in new tab) and M3P (opens in new tab) on universal image language data sets (Multi30k and COCO). To see T-Bletchley in action navigate to the demo (opens in new tab).
Significance of multi-modal and universal

Language and vision are inherently linked. When we hear the statement “a beautiful sunset on the beach” we imagine an image similar to the one above. Models that focus only on language fail to capture this link. To these models, sentences are no more than a grammatically correct sequence of words.
Furthermore, vision is a global modality. The same sight of the beach sunset can be narrated in any language (“una hermosa puesta de sol en la playa”, “un beau coucher de soleil sur la plage”, “Matahari terbenam yang indah di pantai”, etc.), and it would not change the corresponding visual representation. Traditional multi-modal models tie vision to a particular language (most commonly English) and therefore fail to capture this universal property of vision.
With T-Bletchley, we address both these shortcomings. We take a multi-modal approach that advances a computer’s ability to understand language as well as understand images natively, just from pixels. Additionally, we consider language modality with a universal-first approach when developing the model. The result is a one-of-a-kind universal multi-modal model that understands images and text across 94 different languages, resulting in some impressive capabilities. For example, by utilizing a common image-language vector space, without using any metadata or extra information like surrounding text, T-Bletchley can retrieve images that match a text description provided in any language. It can also find images that answer text-based questions in any language, or images that are semantically like another image.
Spotlight: Blog post

MedFuzz: Exploring the robustness of LLMs on medical challenge problems
Medfuzz tests LLMs by breaking benchmark assumptions, exposing vulnerabilities to bolster real-world accuracy.
T-Bletchley in action
To test the capabilities of T-Bletchley, we built an image retrieval system consisting of 30 million randomly sampled images from the web that were unseen by the model during training. The images – without any captions, alt-text or other forms of text metadata – were encoded by the image encoder and stored in an index (opens in new tab).
We built two types of retrieval systems – text-to-image and image-to-image. We vectorized the input queries (for text-to-image with the text encoder and for image-to-image with the image encoder). We use the encoded vector as key and query the index to find its nearest neighbors in the vector space using the approximate nearest neighbor (ANN) algorithm HNSW. The nearest neighbors are then displayed as the image retrieval results.
Today’s image retrieval systems depend heavily on text metadata that is available for images, e.g., image captions, alt-text, surrounding text, image URL, etc. T-Bletchley is unique in that the system can do image retrieval from just the encoded image vectors and does not use any text metadata. This is a big step in true image understanding as compared to today’s systems. Moreover, the demo was built directly with the pre-trained model and not finetuned with any image retrieval task.
In addition, today’s image retrieval systems also use object tagging algorithms applied to images which augment the text metadata (i.e., add tags like car, house, beach, etc. generated from the image). Since the object tagging systems are trained by human-labeled data, the number of classes (tags) is extremely limited. T-Bletchley is trained with unsupervised data, and as a result, it understands a very large number of objects, actions, and many other concepts (dancing, programming, racing, etc.) of the real world.
Below are some examples that showcase the capabilities of T-Bletchley in an image retrieval system.
Universal text-to-image retrieval
Below are examples of images retrieved using text-based queries in multiple languages:
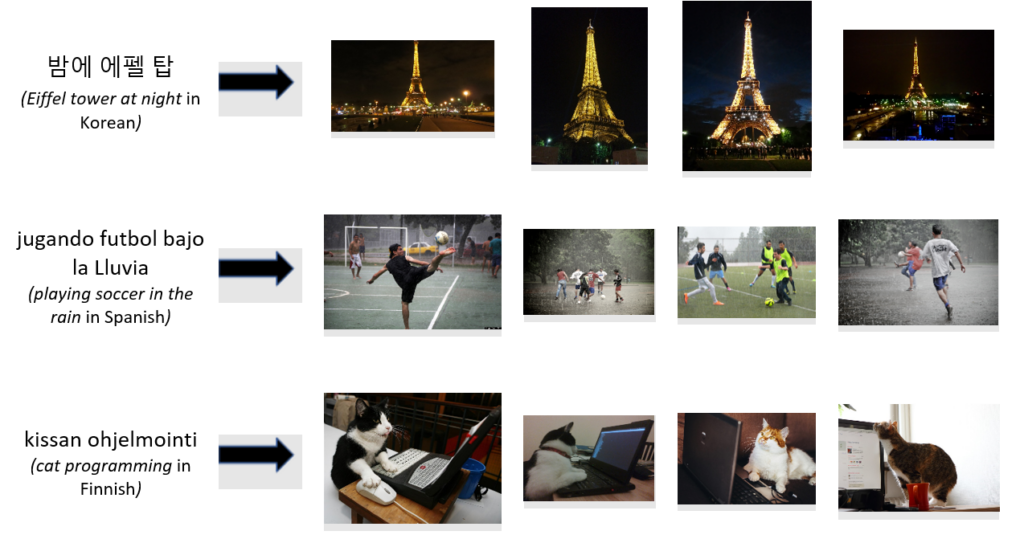
The third example shows that T-Bletchley “understands” the act of programming and has carved out a vector subspace dedicated solely for images of cats programming. True image understanding can be used to improve current retrieval systems to place a greater weight on the image itself.
Code-switched retrieval

T-Bletchley can even retrieve images from non-English language queries written with English script!

T-Bletchley can understand sentences containing multiple languages and scripts:

Image-to-image retrieval
To evaluate image retrieval, we encode the given image using the image encoder and retrieve the closest image vectors and corresponding images from the index. Because T-Bletchley was trained to pick the best caption for an image, it tends to prefer semantically similar images instead of visually similar ones.
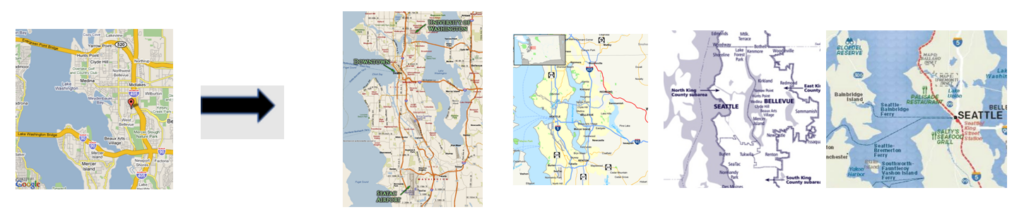
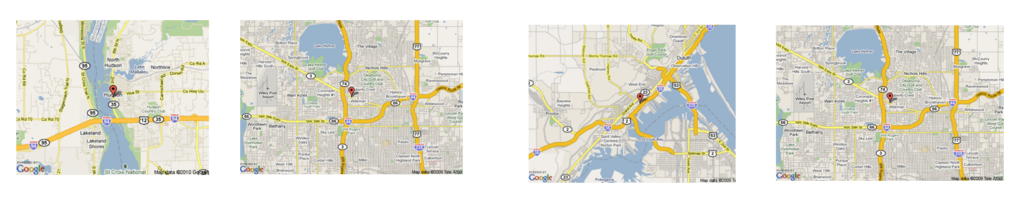
The images retrieved by T-Bletchley are not necessarily similar in appearance to the query image. However, the images, all of the same geography, are ‘semantically similar.’ T-Bletchley does not return the following images from the retrieval set that look like the input image.
Understanding text within images
T-Bletchley is also able to understand text within images without the use of OCR technologies. In the following examples, images are directly passed to the image encoder and stored as 1024 dimensional vectors, and only the cosine similarity between these vectors is used to retrieve similar images.
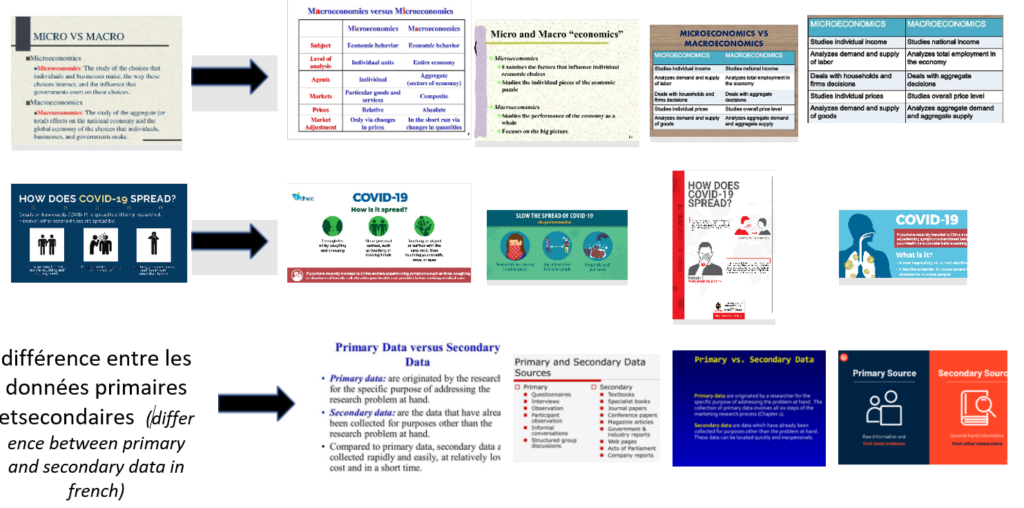
In the first example, T-Bletchley understands that the text in the image is about the differences between microeconomics and macroeconomics and retrieves similar slides. In the second example, T-Bletchley retrieves images related to COVID-19 even though T-Bletchley’s training data pre-dates COVID-19.
This capability is universal—it can be used in multiple languages. The examples below show retrieval in French and Arabic.

T-Bletchley: model development
Dataset
T-Bletchley was trained using billions of image-caption pairs drawn from the web.
Examples of the dataset are depicted below.

A large, diverse training dataset resulted in a robust model that can handle a wide variety of images. To achieve universality, we trained the model on a parallel corpus of 500 million translation pairs. These pairs were created by extracting sentences from document-aligned webpages from common crawl corpus. Adding the Translated Text Contrasted Task allowed us to create a language-agnostic vector representation of captions, which helped make the model much more universal.
Model architecture & training
T-Bletchley consists of transformer-based image and text encoders which are both analogous to the BERT-large (opens in new tab) architecture.
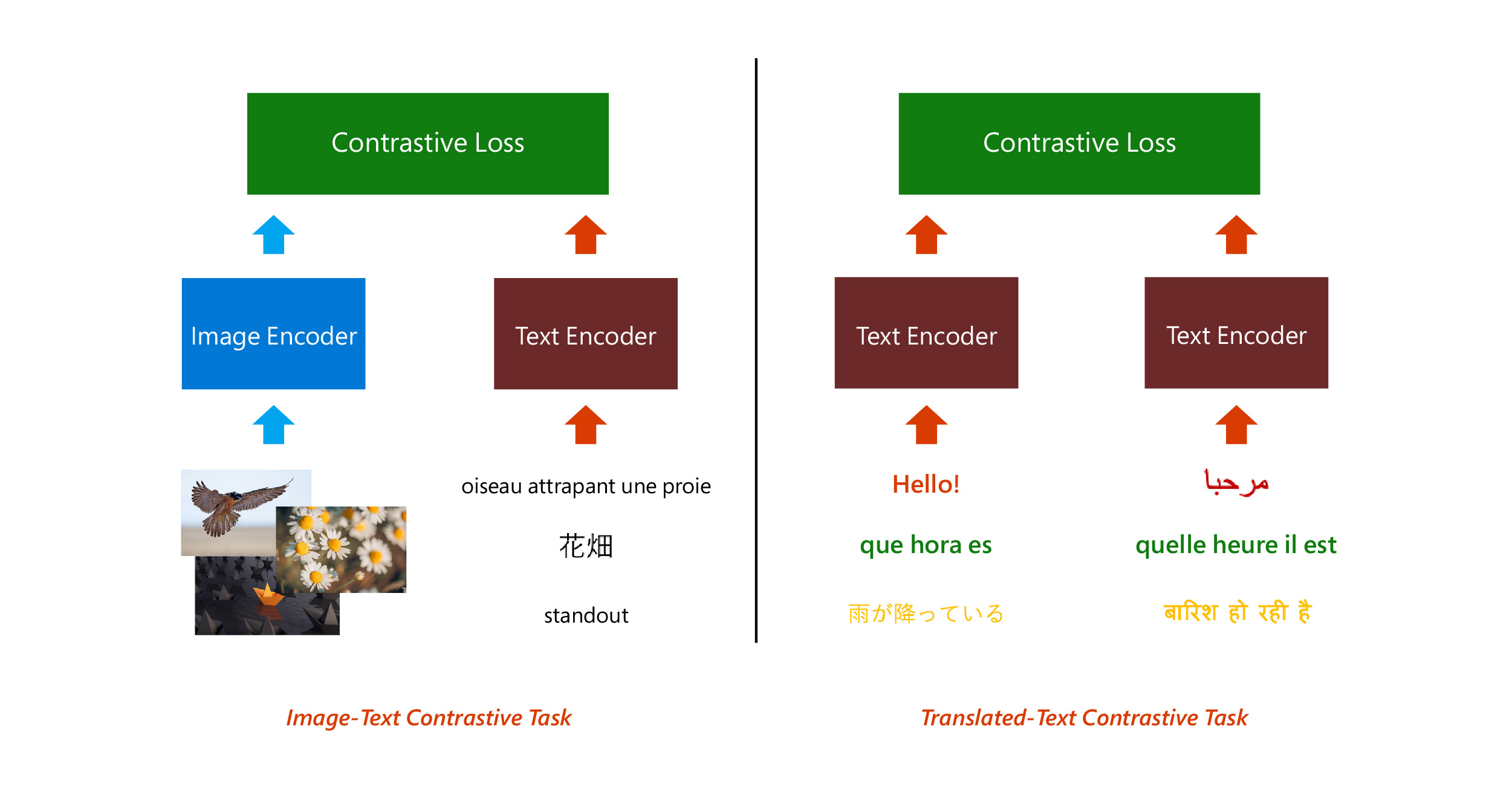
Images and captions were independently encoded, and the model was then trained by applying a contrastive loss on the generated image and text vectors. Similarly, to create a language-agnostic representation, each sentence from a translation pair was independently encoded and a contrastive loss was applied over the resulting batch of vectors.
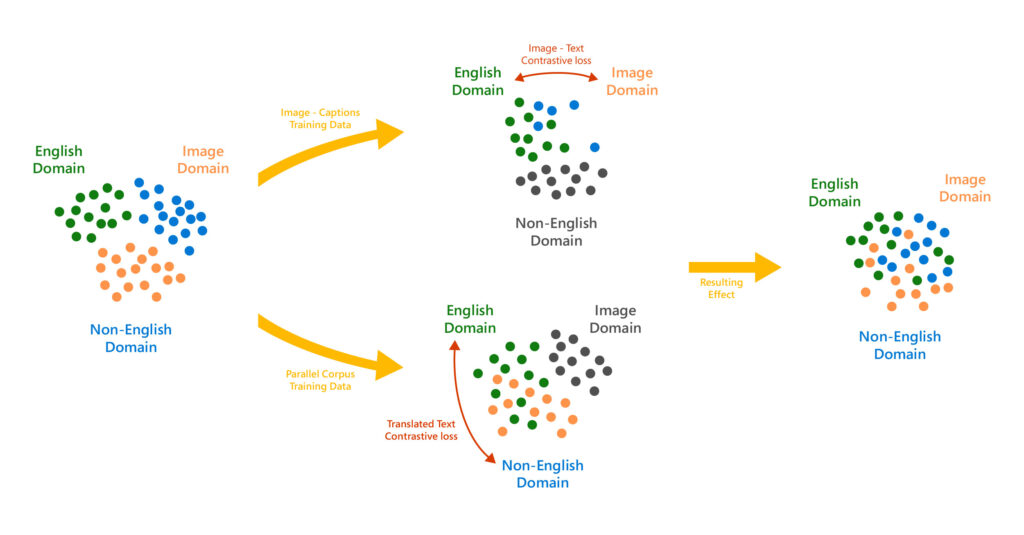
In this way, despite the image caption pairs being predominantly in English, we managed to align captions in different languages with corresponding images.
We leveraged the kernels in the DeepSpeed library (compatible with PyTorch) for our transformer’s implementation and the ZeRO optimizer for training the model.
In-depth model evaluation
T-Bletchley advances the state of the art across multiple public benchmarks.
English
For this evaluation, we followed the prompt engineering and ensembling followed in Google’s ALIGN (opens in new tab) paper. T-Bletchley outperforms Google’s ALIGN model on English image-language benchmarks and sets a new state of the art standard in zero shot image classification, an area pioneered by OpenAI’s CLIP model (opens in new tab).
| Model | ImageNet | CIFAR-100 | CIFAR-10 | COCO R@1 image -> text | COCO R@1 text -> image |
| ALIGN (opens in new tab) | 76.4 | – | – | 58.6 | 45.6 |
| T-Bletchley | 79.0 | 83.5 | 97.7 | 59.1 | 43.3 |
When fine-tuned for retrieval, T-Bletchley outperforms ALIGN, the previous state of the art, by more than two points on the COCO test set.
| Model | Flickr 30k Recall @1 image -> text text->image | COCO Recall @1 image ->text text->image |
| OSCAR (opens in new tab) | – – | 73.5 57.5 |
| ALIGN (opens in new tab) | 95.3 84.9 | 77.0 59.5 |
| T-Bletchley | 97.1 87.4 | 80.2 62.3 |
T-Bletchley achieves state-of-the-art results in English-specific tasks compared to English-only models. T-Bletchley’s English performance is not hindered by universal language support!
Universal
T-Bletchley’s universal retrieval capabilities were evaluated on the Multi30k, COCO-CN and COCO-JP datasets and compared to multilingual models. Even before fine-tuning, T-Bletchley significantly outperforms previous models.
| Setting | Model | Multi30k French German Czech | COCO Chinese Japanese |
| Zero Shot | M3P (opens in new tab) T-Bletchley | 27.1 36.8 20.4 85.0 83.2 81.2 | 32.3 33.3 81.5 64.8 |
When T-Bletchley is fine-tuned, the model sets new state-of-the-art results in multiple languages, shown in the table below.
| Setting | Model | Multi30k French German Czech | COCO Chinese Japanese |
| Finetuned | MULE (opens in new tab) SMALR (opens in new tab) M3P (opens in new tab) T-Bletchley | 62.3 64.1 57.7 65.9 69.8 64.8 73.9 82.7 72.2 94.6 94.3 93.6 | 75.6 75.9 76.7 77.5 86.2 87.9 89.0 86.3 |
Future applications
The goal of T-Bletchley is to create a model that understands text and images as seamlessly as humans do. The first version of T-Bletchley represents a significant breakthrough in this mission. We expect the T-Bletchley model to improve image question and answering, image search, and image-to-image search experiences in Bing, Microsoft Office and Azure.
Note on Responsible AI: Like other publicly available models, the Microsoft Turing models are trained with billions of pages of publicly available text and images, and hence may have picked up biases around gender, race and more from these public documents. Mitigating negative effects from these biases is a difficult, industry-wide issue and Microsoft is committed to the advancement and use of AI grounded in principles that put people first and benefit society. We are putting these Microsoft AI principles into practice throughout the company and have taken extensive precautionary measures to prevent these implicit biases from getting exhibited when using the models in our products. We strongly encourage developers to do the same by putting appropriate guardrails and mitigations in place before taking these models to production.