

By Xiaodong He, Principal Researcher, Microsoft Research
For human beings, reading comprehension is a basic task, performed daily. As early as in elementary school, we can read an article, and answer questions about its key ideas and details.
Microsoft Research Blog

Microsoft Research Forum Episode 3: Globally inclusive and equitable AI, new use cases for AI, and more
In the latest episode of Microsoft Research Forum, researchers explored the importance of globally inclusive and equitable AI, shared updates on AutoGen and MatterGen, presented novel use cases for AI, including industrial applications and the potential of multimodal models to improve assistive technologies.
But for AI, full reading comprehension is still an elusive goal–but a necessary one if we’re going to measure and achieve general intelligence AI. In practice, reading comprehension is necessary for many real-world scenarios, including customer support, recommendations, question answering, dialog and customer relationship management. It has incredible potential for situations such as helping a doctor quickly find important information amid thousands of documents, saving their time for higher-value and potentially life-saving work.
Therefore, building machines that are able to perform machine reading comprehension (MRC) is of great interest. In search applications, machine comprehension will give a precise answer rather than a URL that contains the answer somewhere within a lengthy web page. Moreover, machine comprehension models can understand specific knowledge embedded in articles that usually cover narrow and specific domains, where the search data that algorithms depend upon is sparse.
Microsoft is focused on machine reading and is currently leading a competition in the field. Multiple projects at Microsoft, including Deep Learning for Machine Comprehension, have also set their sights on MRC. Despite great progress, a key problem has been overlooked until recently–how to build an MRC system for a new domain?
Recently, several researchers from Microsoft Research AI, including Po-Sen Huang, Xiaodong He and intern David Golub, from Stanford University, developed a transfer learning algorithm for MRC to attack this problem. Their work is going to be presented at EMNLP 2017, a top natural language processing conference. This is a key step towards developing a scalable solution to extend MRC to a wider range of domains.
It is an example of the progress we are making toward a broader goal we have at Microsoft: creating technology with more sophisticated and nuanced capabilities. “We’re not just going to build a bunch of algorithms to solve theoretical problems. We’re using them to solve real problems and testing them on real data,” said Rangan Majumder in the machine reading blog.
Currently, most state-of-the-art machine reading systems are built on supervised training data–trained end-to-end on data examples, containing not only the articles but also manually labeled questions about articles and corresponding answers. With these examples, the deep learning-based MRC model learns to understand the questions and infer the answers from the article, which involves multiple steps of reasoning and inference.
However, for many domains or verticals, this supervised training data does not exist. For example, if we need to build a new machine reading system to help doctors find important information about a new disease, there could be many documents available, but there is a lack of manually labeled questions about the articles, and the corresponding answers. This challenge is magnified by both the need to build a separate MRC system for each different disease, and that the volume of literature is increasing rapidly. Therefore, it is of crucial importance to figure out how to transfer an MRC system to a new domain where no manually labeled questions and answers are available, but there is a body of documents.
Microsoft researchers developed a novel model called “two stage synthesis network,” or SynNet, to address this critical need. In this approach, based on the supervised data available in one domain, the SynNet first learns a general pattern of identifying potential “interestingness” in an article. These are key knowledge points, named entities, or semantic concepts that are usually answers that people may ask for. Then, in the second stage, the model learns to form natural language questions around these potential answers, within the context of the article. Once trained, the SynNet can be applied to a new domain, read the documents in the new domain and then generate pseudo questions and answers against these documents. Then, it forms the necessary training data to train an MRC system for that new domain, which could be a new disease, an employee handbook of a new company, or a new product manual.
The idea of generating synthetic data to augment insufficient training data has been explored before. For example, for the target task of translation, Rico Sennrich and colleagues present a method in their paper to generate synthetic translations given real sentences to refine an existing machine translation system. However, unlike machine translation, for tasks like MRC, we need to synthesize both questions and answers for an article. Moreover, while the question is a syntactically fluent natural language sentence, the answer is mostly a salient semantic concept in the paragraph, such as a named entity, an action, or a number. Since the answer has a different linguistic structure than the question, it may be more appropriate to view answers and questions as two different types of data.
In our approach, we decompose the process of generating question-answer pairs into two steps: The answer generation conditioned on the paragraph and the question generation conditioned on the paragraph and the answer. We generate the answer first because answers are usually key semantic concepts, while questions can be viewed as a full sentence composed to inquire about the concept.
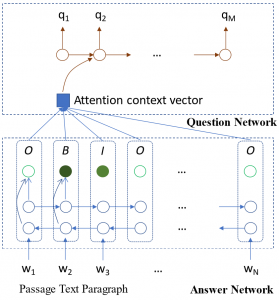
The SynNet is trained to synthesize the answer and the question of a given paragraph. The first stage of the model, an answer synthesis module, uses a bi-directional long short-term memory (LSTM) to predict inside-outside beginning (IOB) tags on the input paragraph, which mark out key semantic concepts that are likely answers. The second stage, a question synthesis module, uses a uni-directional LSTM to generate the question, while attending on embeddings of the words in the paragraph and IOB IDs. Although multiple spans in the paragraph could be identified as potential answers, we pick one span when generating the question.
Two examples of generated questions and answers from articles are illustrated below:


Using the SynNet, we were able to get more accurate results on a new domain without any additional training data, approaching to the performance of a fully supervised MRC system.
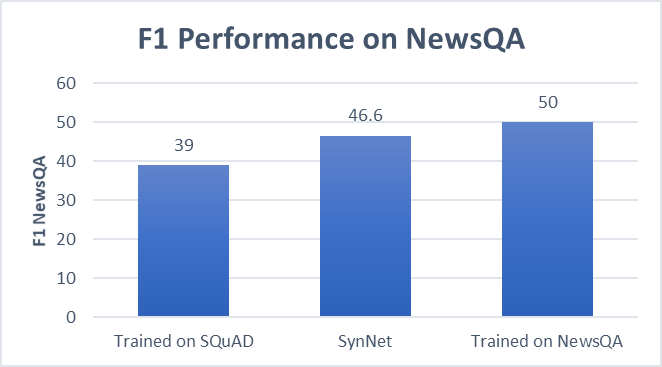
SynNet, trained on SQuAD (Wikipedia articles), performs almost as well on the NewsQA domain (news articles), as a system fully trained on NewsQA.
The SynNet is like a teacher, who, based on her experience in previous domains, creates questions and answers from articles in the new domain, and uses these materials to teach her students to perform reading comprehension in the new domain. Accordingly, Microsoft researchers also developed a set of neural machine reading models, including the recently developed ReasoNet that has shown a lot of promise, which are like the students who learn from the teaching materials to answer questions based on the article.
To our knowledge, this is the first attempt to apply MRC domain transferring. We are looking forward to developing scalable solutions that rapidly expand the capability of MRC to release the game-changing potential of machine reading!
Related:
- Get started with the Stanford Question Answering Dataset on GitHub
- Improving Neural Machine Translation Models with Monolingual Data
- Visit the Microsoft Research Deep Learning Group



