The games industry has long been a frontier of innovation for AI. In the early 2000s, programmers hand-coded neural networks to breathe life into virtual worlds (opens in new tab), creating engaging AI characters (opens in new tab) that interact with players. Fast forward two decades, neural networks have grown from their humble beginnings to colossal architectures with billions of parameters, powering real-world applications like ChatGPT (opens in new tab) and Microsoft Copilots (opens in new tab). The catalyst for this seismic shift in AI scale and capability is the advent of automatic optimization. AutoDiff frameworks like PyTorch (opens in new tab) and Tensorflow (opens in new tab) have democratized scalable gradient-based end-to-end optimization. This breakthrough has been instrumental in the development of Large Foundation Models (LFMs) that now sit at the core of AI.
Today, the AI systems we interact with are more than just neural network models. They contain intricate workflows that seamlessly integrate customized machine learning models, orchestration code, retrieval modules, and various tools and functions. These components work in concert to create the sophisticated AI experiences that have become an integral part of our digital lives. Nonetheless, up to now, we do not have tools to automatically train these extra components. They are handcrafted through extensive engineering, just like how neural networks were engineered in the early 2000s.
End-to-end automatic optimization of AI systems
The latest research from Microsoft and Stanford University introduces Trace (opens in new tab), a groundbreaking framework poised to revolutionize the automatic optimization of AI systems. Here are three highlights of the transformative potential of Trace:
- End-to-end optimization: Trace treats AI systems as computational graphs, akin to neural networks, and optimizes them end-to-end through a generalized back-propagation approach.
- Dynamic adaptation: It handles the dynamic nature of AI systems, where the graph can change with varying inputs and parameters and needs to adapt to various kinds of feedback.
- Versatile applications: Trace can optimize heterogenous parameters (such as prompts and codes) in AI systems. Empirical studies showcase Trace’s ability to optimize diverse problems, including hyperparameter tuning, large language model (LLM) agents, and robot control, often outperforming specialized optimizers.
In a nutshell, Trace is a new AutoDiff-like tool for training AI systems without using gradients. This generalization is made possible by a new mathematical formulation of optimization, Optimization with Trace Oracle (OPTO), which can describe end-to-end optimization of AI systems with general feedback (such as numerical losses, natural language, and errors). Instead of propagating gradients, which are not well-defined for AI systems beyond neural networks, Trace propagates Minimal Subgraphs which can then be used to also recover gradients where applicable. Trace is implemented as a PyTorch-like Python library with which users can easily create AI systems and refine them, akin to training neural networks.
In this blog post, we are excited to announce the release of the Trace Python library (opens in new tab). With the help of demos, we’ll show you how this powerful tool can be used to build AI agents that learn and adapt from their experiences, eliminating the need for specialized engineering.
Spotlight: Blog post

MedFuzz: Exploring the robustness of LLMs on medical challenge problems
Medfuzz tests LLMs by breaking benchmark assumptions, exposing vulnerabilities to bolster real-world accuracy.
Warm up: Building a Battleship game AI agent through learning
To start, consider building an AI agent for the classic Battleship board game. In Battleship, a player needs to devise strategies to cleverly locate and attack the opponent’s ships on a hidden board as fast as possible. To build an AI agent with Trace, one simply needs to program the workflow and declare the parameters, like programming a neural network architecture. Here we will design an agent with two components: a reason function and an act function, as illustrated in Figure 1a. We provide a basic description of what these two functions should do as docstrings. We leave the functions’ content to be blank and set them to be trainable. At this point, the agent doesn’t know how the Battleship API works. It must not only learn how to play the game, but also learn how to use the unknown API.


We iteratively train this AI agent to play the game through a simple Python for loop, seen in Figure 1b. In each iteration, the agent (that is, policy) sees the board configuration and tries to shoot at a target location on a training board. The environment returns in text whether it’s a hit or a miss. Then, we run Trace to propagate this environment feedback through agent’s decision logic to update the parameters (for example, the policy is like a two-layer network with a reason layer and an act layer). These iterations mimic how a human programmer might approach the problem. They run the policy and change the code based on the observed feedback, try different heuristics to solve this problem, and may rewrite the code a few times to fix any execution errors by using stack traces.
In Figure 2, we show the results of this learning agent, where the agent is trained by an LLM-based optimizer OptoPrime in Trace. The performance is measured as the scores of the agent playing on new randomly generated games (different from the training board). We see that the agent understands the Battleship game and proposes the enumeration strategy after one iteration; then, after a few more tries, it starts to develop complex strategies for playing the game.

Super-fast reinforcement learning agent for robot control
We can extend the same idea of end-to-end optimization to train more complicated AI systems. In this example, we want to learn a policy code to control a robotic manipulator. Compared to the Battleship example, the problem here has a longer horizon, since the policy would need to drive the robot for multiple time steps before receiving any feedback. Traditionally, such a problem is framed as a reinforcement learning (RL) problem, and usually learning a policy with RL requires tens of thousands of training episodes. We show Trace can be used to effectively solve such a problem, with just dozens of episodes — a 1,000 times speed-up. We trace an entire episode and perform end-to-end updates through these steps (using the same OptoPrime optimizer). In this way, effectively, Trace performs back-propagation through time (BPTT (opens in new tab)).
We conduct experiments using a simulated Sawyer robot arm in the Meta-World (opens in new tab) environment of LLF-Bench (opens in new tab), as shown in Figure 3. The agent needs to decide a target pose for the robot, which will then be used as a set point for a position controller, to perform a pick-and-place task. Each episode has 10 timesteps, which results in a graph of depth around 30. The agent receives language feedback as intermediate observations (from LLF-Bench) and finally feedback about success and episode return (i.e. cumulative reward for RL) in texts at the end. Like the Battleship example, we initialize the policy code to be a dummy function and let it adapt through interactions, demonstrated in Figure 4. We repetitively train the agent starting from one initial condition, then test it on 10 new held-out initial conditions for generalization. Very quickly, after 13 episodes, we see that the agent learns complex rules to solve the problem, as shown in Figure 3 and Figure 4.
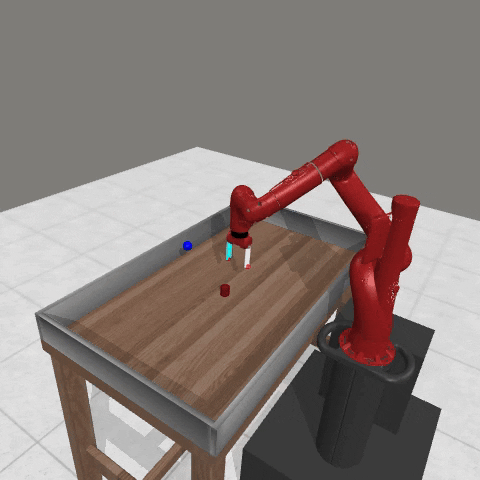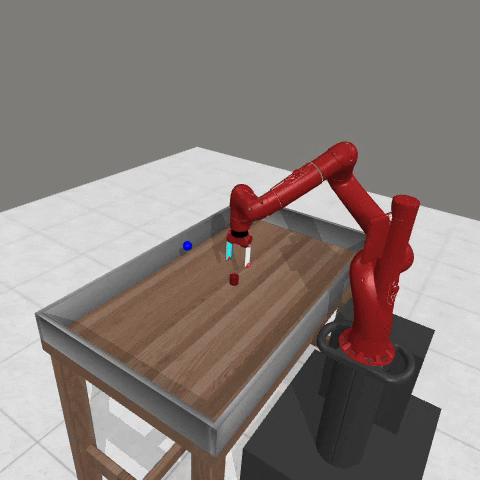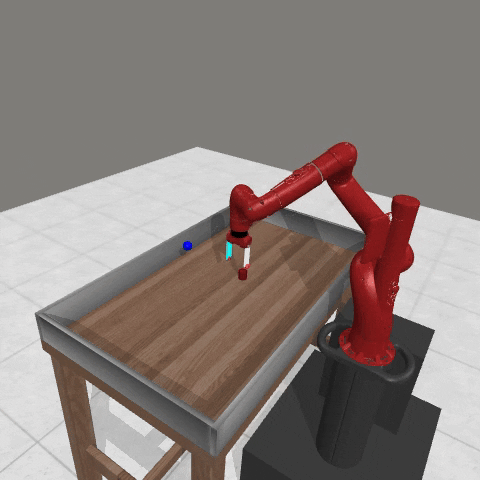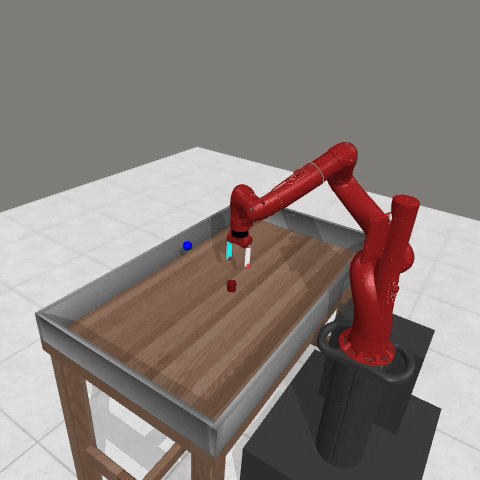
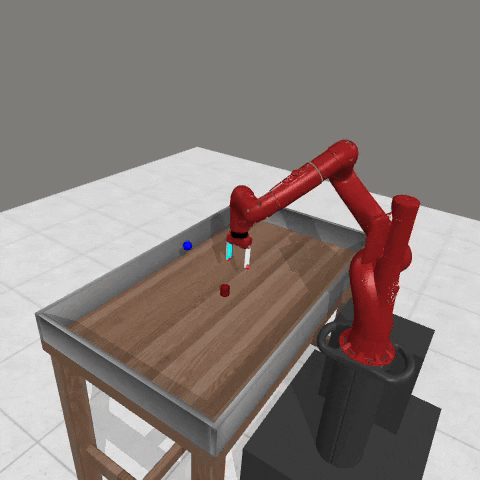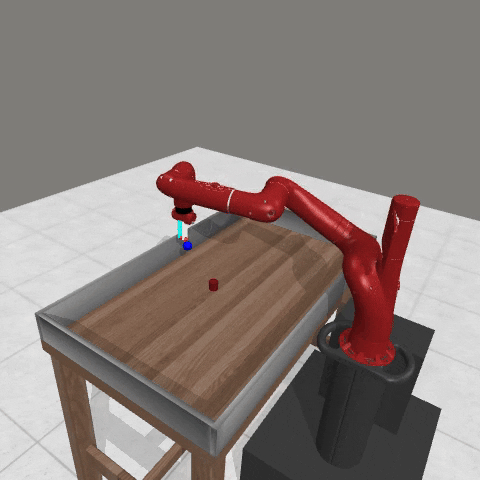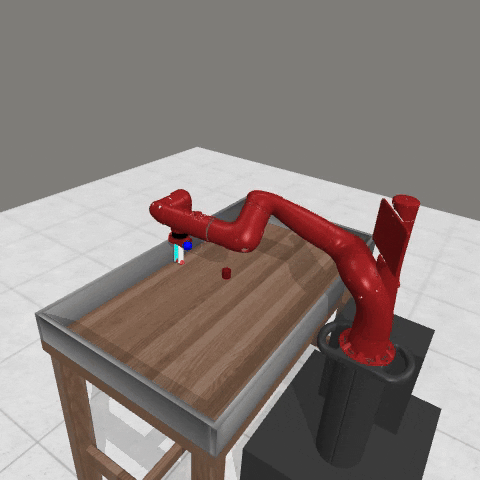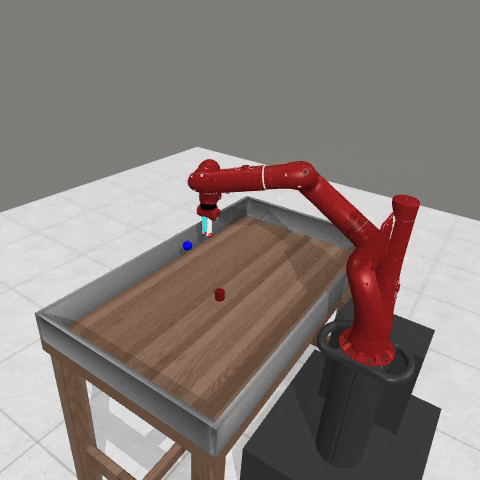

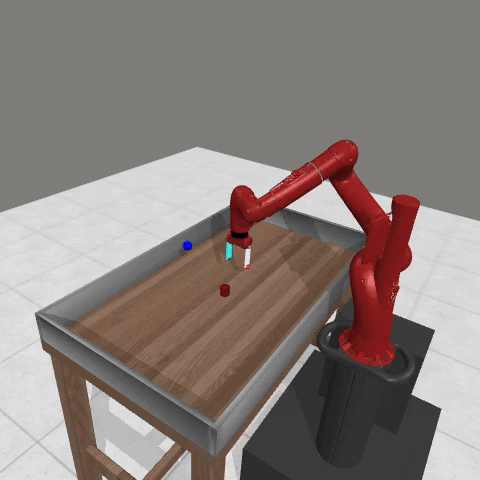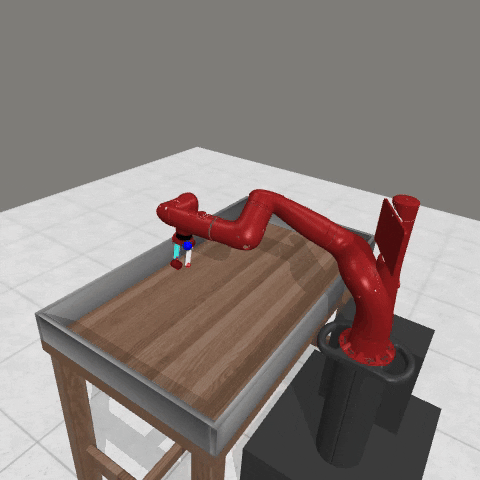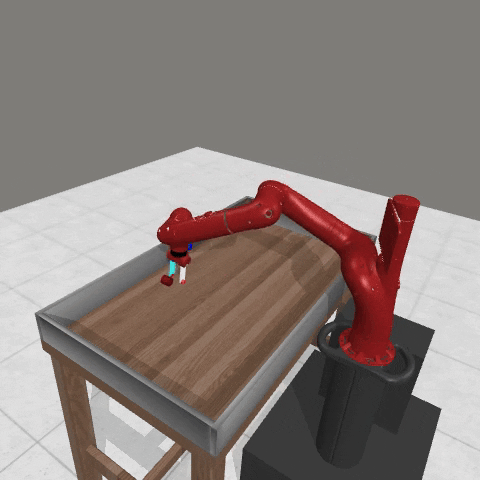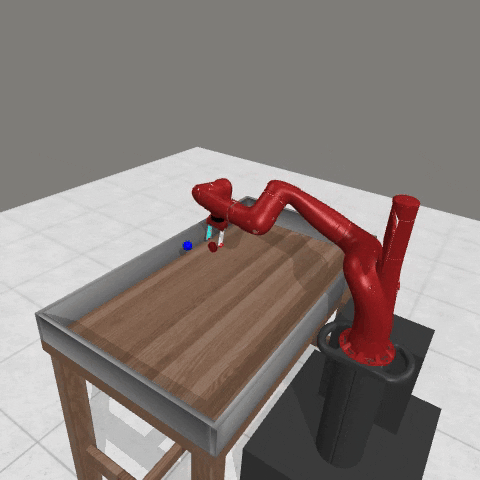

Figure 3: Trace rapidly learns a generalizable robot controller in the MetaWorld simulated environment. The learning starts from a trivial policy and the robot does not know the exact rule and dynamics of the task. The video shows Trace learns a policy to successfully perform the pick-place task after 13 iterations, through language feedback (e.g., «The previous step’s reward was 0.008. The latest arm movement was in a wrong direction. Finishing the task is now more distant than previously. Moving to [-0.07 0.68 0.12 0. ] now is a good idea.”). The video shows the robot tested on 10 held-out initial configurations not seen in training. From left to right: iteration 0 (initial policy which does not move the robot; the video shows the 10 testing configurations), iteration 1 (the robot learned to reach the goal but forgot to pick up the object first), iteration 3 and iteration 9 (The robot learned to pick up the object, attempted to place it to the goal location, but failed), iteration 13 (The robot learned to successfully perform pick-place for all unseen 10 initial configurations, which is the desired behavior.)


Finale: Self-adapting multi-agent LLM systems
Trace is not limited to code optimization. The Trace framework supports optimizing heterogenous parameters, including codes, prompts, and hyperparameters. Here we demonstrate Trace’s ability to optimize prompts of multiple LLM agents in solving complex household tasks in the VirtualHome (opens in new tab) simulated environment.
Many tasks require multi-agent collaboration to solve efficiently. But crafting the right prompts for multiple LLM agents requires careful engineering. Trace can seamlessly optimize agents’ behaviors based on environmental feedback. Trace automatically constructs the interaction graph of agents and updates each agent’s behavior factoring in the behavior of other agents. Then the agents can automatically evolve to acquire specialized capabilities such as behavioral roles, freeing system designers from the painstaking process of hand-tuning multiple LLM prompts.
We use Trace and OptoPrime to improve ReAct agents that have been carefully orchestrated (opens in new tab) to complete the VirtualHome tasks. In each step, the agent can interact with the environment (like opening a cabinet) or send a message to another agent when they see each other. We declare the plan of each LLM-based agent (a part of their prompt) as a trainable parameter and use reward as feedback. The experimental results are shown in Figure 5 where agents optimized by Trace can complete the tasks using fewer actions and environment interactions. We observed fascinating emergent pro-social behaviors from agents without being explicitly told to communicate as illustrated in Figure 6. This pro-social interaction behavior changes with different tasks. For example, agents did not communicate with each other for the task of “book reading,” but they collaborated when asked to “put forks and plates into a dishwasher,” which we show in Figure 7. We also observed other patterns such as role specialization, where one agent became the lead in a given task, and was followed by another agent to assist.



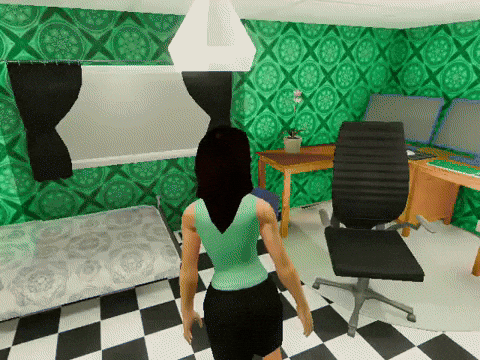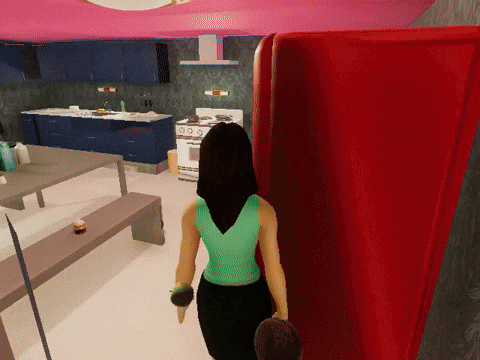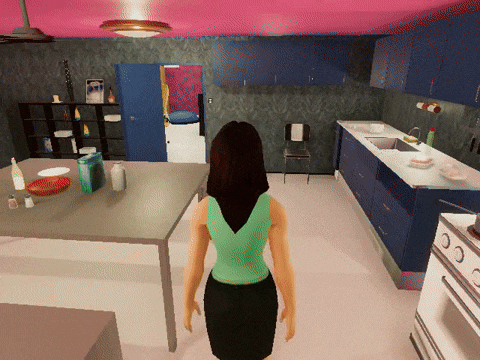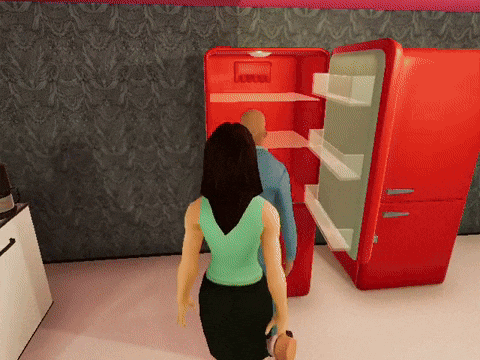
Figure 6: Demo videos of how Trace agents behave to finish each of the three tasks.
[send_message] < Agent 1 > to < Agent 2 >: I am handing you the < cutleryfork >. Please grab another piece of cutlery or plate to help!
[send_message] < Agent 2 > to < Agent 1 >: Can you also hand me the < plate > you are holding?
[send_message] < Agent 1 > to < Agent 2 >: Here's the < cutleryfork >. I'll go grab the < plate > now.
...
[send_message] < Agent 1 > to < Agent 2 >: Let's head to the kitchen and put the < cutleryfork > and < plate > into the dishwasher.Figure 7: Trace learns pro-social behavior in the Dishwasher task. Trace optimized agents send messages to attempt to collaborate while simple ReAct agent will only carry out the tasks.
Trace heralds a new era of interactive agents that adapt automatically using various feedback types. This innovation could be the key to unlocking the full potential of AI systems, making them more efficient and responsive than ever before. After witnessing the awesome power of Deep Neural Networks, stay tuned for the next revolution in AI design — Deep Agent Networks!