Today, development of generalizable AI models requires access to sufficient data and compute resources, which may create challenges for some researchers. Democratizing access to technology across the research community can advance the development of generalizable AI models. By applying the core software development concept of modularity to AI, we can build models that are powerful, efficient, adaptable, and transparent.
Until recently, AI models were primarily built using monolithic architecture. Though powerful, these models can be challenging to customize and edit compared to modular models with easily interpretable functional components. Today, developers employ modularity to make services more reliable, faster to refine, and easier for multiple users to contribute to simultaneously. One promising research direction that supports this involves shifting AI development towards a modular approach (opens in new tab), which could enhance flexibility and improve scalability.
One such approach is to use numerous fine-tuned models designed for specific tasks, known as expert models, and coordinate them to solve broader tasks (see Towards Modular LLMs by Building and Reusing a Library of LoRAs – Microsoft Research (opens in new tab), Learning to Route Among Specialized Experts for Zero-Shot Generalization (opens in new tab)). These expert models can be developed in a decentralized way. Similar to the benefits of using a microservice architecture, this modular AI approach can be more flexible, cheaper to develop, and more compliant with relevant privacy and legal policies. However, while substantial research has been done on training optimization, coordination methods remain largely unexplored.
Our team is exploring the potential of modular models by focusing on two themes: i) optimizing the training of expert models and ii) refining how expert models coordinate to form a collaborative model. One method for coordinating expert models is to adaptively select the most relevant independently developed expert models for specific tasks or queries. This approach, called MoErging, is similar to Mixture-of-Experts (MoE) approaches but differs in that the routing mechanism is learned after the individual experts are trained. As an initial step, we contributed to creating a taxonomy for organizing recent MoErging methods with the goal of helping establish a shared language for the research community and facilitating easier and fairer comparisons between different methods.
Assessing existing MoErging methods
Most MoErging methods were developed within the past year, so they don’t reference each and are difficult to compare. To enable comparison of MoErging methods, we recently collaborated on a survey that establishes a taxonomy for comparing methods and organizes MoErging design choices into three steps:
- Expert design: Identifies and uses expert models trained asynchronously by distributed contributors.
- Routing design: Routes tasks to the appropriate expert models.
- Application design: Applies the merged models to specific tasks or domains.
Each step is broken down into more detailed choices. For example, in expert design, expert training can be custom or standard, and training data can be private or shared. Custom training requires MoErging to have specific training procedures, while the standard training does not. Similarly, shared data means that the training data must be accessible for routing. Otherwise, the training data is considered private.
The benefits of modular models discussed below assume that training data doesn’t need to be shared. However, a review of current MoErging methods finds that some approaches do require sharing training data, making certain benefits no longer applicable.

GigaPath: Whole-Slide Foundation Model for Digital Pathology
Digital pathology helps decode tumor microenvironments for precision immunotherapy. In joint work with Providence and UW, we’re sharing Prov-GigaPath, the first whole-slide pathology foundation model, for advancing clinical research.
The survey evaluates 29 different MoErging methods using its taxonomy, which categorizes the design choices into two expert design choices, five routing design choices, and two application design options, shown in Figure 1.
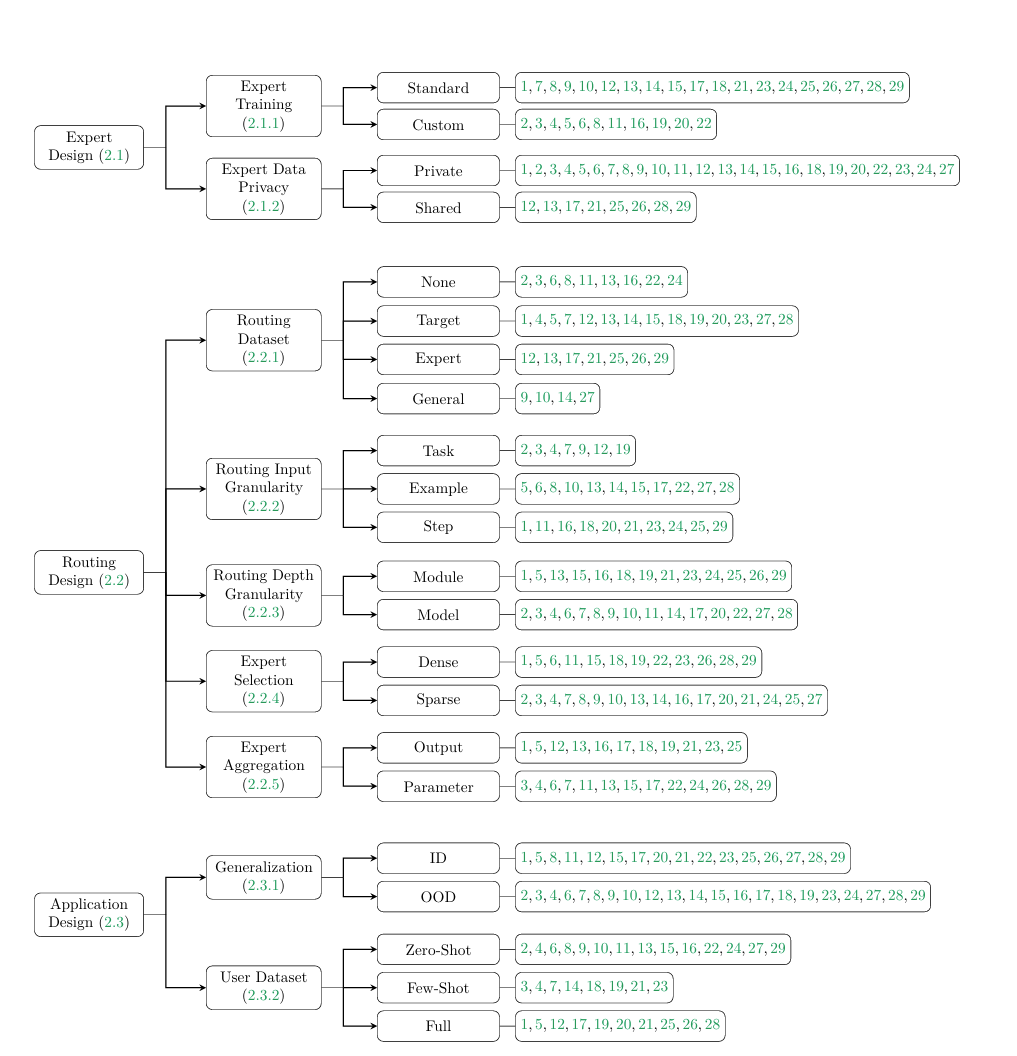
One takeaway from the survey is that most MoErging methods can be grouped into four categories based on their routing design choices:
- Classifier-based routing: Methods that train the router as a classifier using expert datasets or unseen data.
- Embedding-based routing: Methods that compute embeddings of expert training sets and compare them to a query embedding for routing.
- Nonrouter methods: Methods that do not explicitly train a router but instead initialize the router in an unsupervised manner.
- Task-specific routing: Methods that learn a task-specific routing distribution over the target dataset to improve performance on a specific task.
While the differences within each category are minor, the differences across categories are significant because they determine the level of data access required for implementation. As a result, data access is a primary factor in determining which methods are applicable and feasible in various settings.
Our taxonomy also covers recent approaches to building agentic systems, which could be viewed as specific types of MoErging methods where experts are full language models and routing decisions are made on a step-by-step or example-by-example basis. The optimal level for MoErging may vary depending on the task and the computational resources available to each stakeholder.
Potential benefits and use cases of modular models
Modular models can unlock new benefits and use cases for AI, offering a promising approach to addressing challenges in current AI development. Moving forward, further substantial research is needed to validate this potential and assess feasibility.
Modular AI may:
- Allow privacy-conscious contributions. Teams with sensitive or proprietary data, such as personally identifiable information (PII) and copyrighted content, can contribute expert models and benefit from larger projects without sharing their data. This capacity can make it easier to comply with data privacy and legal standards, which could be valuable for healthcare teams that would benefit from general model capabilities without combining their sensitive data with other training data.
- Drive model transparency and accountability. Modular models allow specific expert models to be identified and, if necessary, removed or retrained. For example, if a module trained on PII, copyrighted, or biased data is identified, it can be removed more easily, eliminating the need for retraining and helping ensure compliance with privacy and ethical standards.
- Facilitate model extensibility and continual improvement. Modularity supports continual improvements, allowing new capabilities from expert models to be integrated as they are available. This approach is akin to making localized edits, allowing for continuous, cost-effective improvement.
- Lower the barrier to AI development for those with limited compute and data resources. Modular AI can reduce the need for extensive data and compute by creating a system where pretrained experts can be reused, benefiting academics, startups, and teams focused on niche use cases. For example, an AI agent tasked with booking flights on a specific website with limited training data could leverage general navigation and booking skills from other trained AI experts, enabling generalizable and broadly applicable skills without requiring domain-specific training data. We explore this process of transferring skills across tasks in our paper “Multi-Head Routing For Cross-Task Generalization.”
- Support personalization. Modular models make it possible to equip AI agents with experts tailored to individual users or systems. For instance, AI designed to emulate five-time World Chess Champion Magnus Carlsen could enhance a player’s preparation to play a match against him. Experiments suggest that storing knowledge or user profiles in on-demand modules can match or surpass the performance of retrieval-augmented generation (RAG), potentially reducing latency and improving the user’s experience in custom AI applications.
Current limitations and looking forward
In this blog, we focused on a type of modular approach that involves training foundation models, which requires substantial compute power and large amounts of data. Despite the advantages of modularity, such as increased flexibility, efficiency, and adaptability, the development of foundation models remains resource-intensive, necessitating high-performance computing and robust datasets to support fine-tuning.
Recent work has begun to address these challenges by distributing the pretraining process of foundation models (opens in new tab). Looking ahead, a promising research direction focuses on exploring how to create a minimal dataset for training “empty foundation models” while shifting most of their capabilities to external pluggable modules.
Modular methods are evolving rapidly, and we’re excited by their potential. Modularity has the capacity to democratize AI development, improve model accountability, and support efficient continuous learning. With the MoErging taxonomy, we aim to establish a shared language that fosters engagement within the research community. This research is in the early stages, and we welcome community collaboration. If you’re interested in working with us, please reach out to [email protected].
Acknowledgements
We would like to thank paper collaborators: Prateek Yadav, Colin Raffel, Mohammed Muqeeth, Haokun Liu, Tianlong Chen, Mohit Bansal, Leshem Choshen, Edoardo Ponti, Zhan Su, Matheus Pereira, Nicolas Le Roux, Nabil Omi, Siddhartha Sen, Anurag Sarkar, Jordan T. Ash, Oleksiy Ostapenko, and Laurent Charlin.