
AI has made major strides in the last decade, from beating the world champion of Go (opens in new tab), to learning how to program (opens in new tab), to telling fantastical short stories (opens in new tab). However, a basic human trait continues to elude machines: common sense. Common sense is a big term with plenty of baggage, but it typically includes shared background knowledge (I know certain facts about the world, like «the sky is blue,» and I know that you know them too), elements of logic, and the ability to infer what is plausible. It looms large as one of the hardest and most central problems in AI. Machines can seem glaringly unintelligent when they lack common sense.
Spotlight: On-demand video

AI Explainer: Foundation models and the next era of AI
Explore how the transformer architecture, larger models and more data, and in-context learning have helped advance AI from perception to creation.
This is especially true when it comes to language because language is ambiguous. Common sense enables us to fill in the semantic blanks when a statement doesn’t fully specify what it describes. Imagine telling a machine:
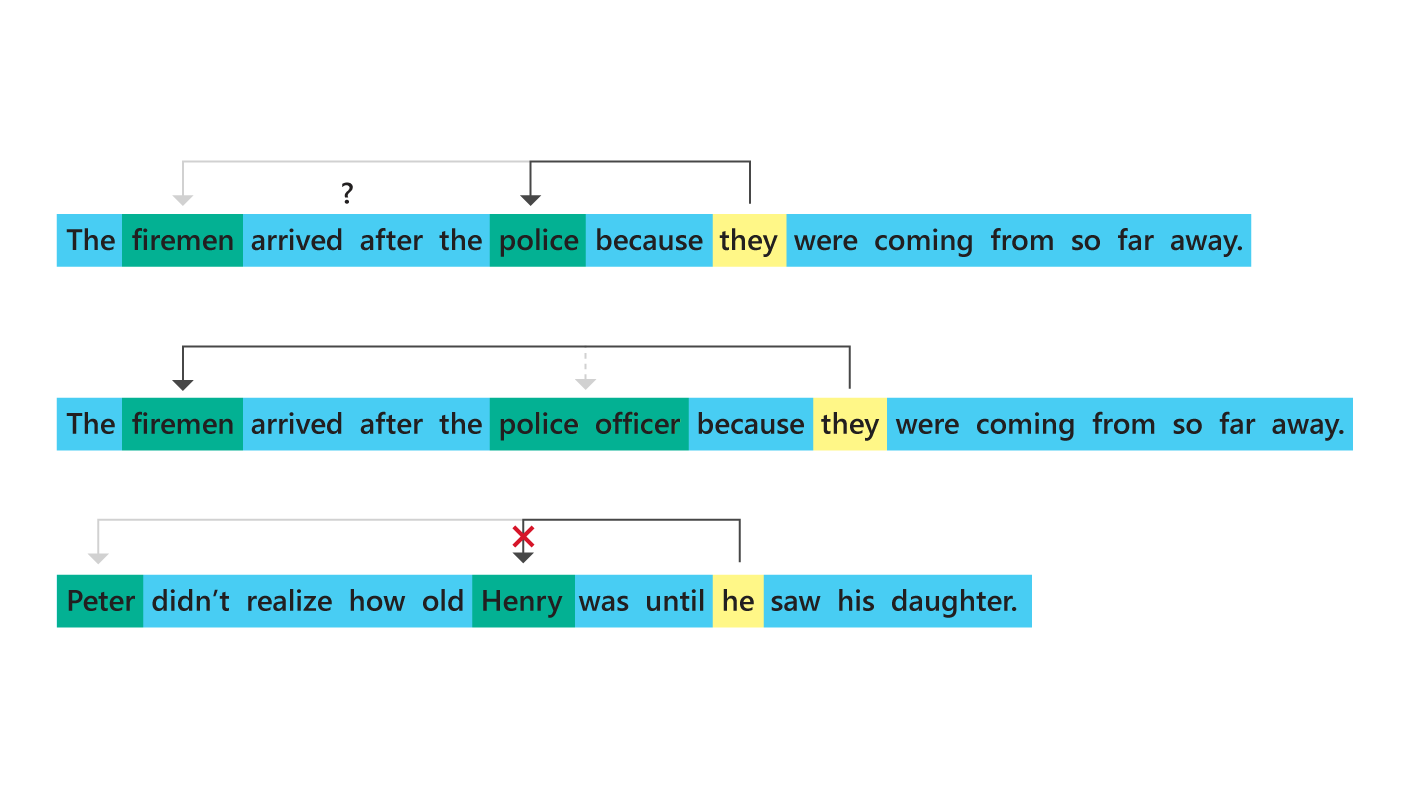
The firemen arrived after the police because they were coming from so far away.
Does the machine recognize who was coming from so far away in this scenario? Only if it understands common concepts of distance and time; that is, that being more distant from a thing means taking more time to reach it. Humans acquire this knowledge from experience and learn to utilize and refer to it at will. The question is: How do we endow machines with similar abilities and, just as important, how do we measure progress towards this goal?
Mila/McGill University researchers and students collaborated with Microsoft researchers on a recent paper, «The KnowRef Coreference Corpus: Removing Gender and Number Cues for Difficult Pronominal Anaphora Resolution (opens in new tab),» which attempts to answer this question. It will appear at the 2019 Annual Meeting of the Association for Computational Linguistics (ACL) in Florence, Italy (opens in new tab). The paper introduces a new resource for training and evaluating common sense in machines, the KnowRef coreference corpus. This benchmark contains over 8,000 annotated text passages from the web that exhibit natural, knowledge-oriented instances of pronominal coreference.
The challenge of pronominal coreference for AI
The language problem given above is an example of pronominal coreference. There is a statement with two antecedents (the firemen and the police) followed by an ambiguous pronoun (they) that refers uniquely to one antecedent. The challenge is to figure out which antecedent the pronoun refers to. Not every instance of pronominal coreference is tricky, though. Oftentimes, there are lexical giveaways like number and gender that make the solution obvious. Consider this slight reformulation of the previous problem:
The firemen arrived after the police officer because they were coming from so far away.
Because the second antecedent is singular, it’s more obvious that they refers to the firemen. Common sense understanding of distance and time is no longer necessary. You can imagine similar examples where gendered words and pronouns (fireman/he) resolve ambiguity.
The previous test for common sense in coreference
The Winograd Schema Challenge (opens in new tab) (WSC) is a benchmark made up of the trickier kind of coreference, where lexical cues don’t reveal the answer. It was the direct inspiration for KnowRef. The WSC has been called an “alternative Turing test,” garnering considerable attention in the natural language processing and AI communities as a measure of common sense in machines. The last year has seen exciting new approaches to the WSC, from large-scale training of massive language models, like BERT (opens in new tab) and GPT-2 (opens in new tab), to our own approach (opens in new tab) based on knowledge hunting on the web. None has yet come close to human-level performance.
Beyond the desired challenge to common sense, however, the WSC presents several difficulties. First, it isn’t large enough (fewer than 300 instances) to form a proper train/test split nor to measure results with high confidence. Because the WSC is so small, it’s likely that a significant proportion of recent progress can be attributed to chance and word-association exploits (opens in new tab). Second, the Winograd schemas were authored mainly by two expert linguists with a specific goal in mind: stumping machines. Since they don’t occur naturally in text, it’s unclear whether a system that aces the WSC will generalize to less-contrived scenarios.
Building on the Winograd Schema Challenge with KnowRef
What if we could automatically identify WSC-like instances in natural text to compile a much larger dataset? Could this be used to train and more confidently evaluate state-of-the-art models? That’s the approach we tested with KnowRef. To construct our corpus, we basically reversed the reformulation process seen above. We found text snippets on the web with two antecedents and a coreferential pronoun where the pronoun’s resolution was clear—it matched in number or gender with only one of the antecedents—and then modified the non-matching antecedent so that it would match.
By forcing the antecedents to correspond in number and gender, we prevent machines from exploiting these cues, and we hope the only thing left to exploit will be common sense. We developed a suite of automatic methods to enact the reformulation process (see our paper for details) and used it to gather data on Wikipedia and Reddit. It’s easiest when the antecedents are gendered proper nouns, like “Alice” and “Bob,” since we can swap out one name with another that matches the pronoun’s gender.
KnowRef results and the human-machine performance gap
Our experiments show that KnowRef is a challenging benchmark. We demonstrate that various systems, whether rule-based, feature-rich, or neural, perform significantly worse than humans on the task. See Table 1 for numbers comparing the performance of humans, BERT, a state-of-the-art neural coreference system, and other models.
| Model | Task Accuracy |
| Random | 0.50 |
| Human | 0.92 |
| Rule (opens in new tab) | 0.52 |
| Stat (opens in new tab) | 0.50 |
| Deep-RL (opens in new tab) | 0.49 |
| E2E (opens in new tab) | 0.58 |
| E2E (trained on CoNLL only) | 0.60 |
| E2E (KnowRef + CoNLL training) | 0.65 |
| BERT | 0.61 |
Table 1: Performance of various systems on the KnowRef test set.
Human subjects displayed strong inter-annotator agreement and judged KnowRef’s passages to be resistant to lexical giveaways. Looking into the human-machine performance gap more closely, our analysis shows that on KnowRef, even state-of-the-art models fail to capture semantic context; they base many decisions on the gender or number of antecedents rather than any common sense. In neural models, these cues are wrapped up in the dimensions of standard and contextualized word embeddings. Let’s look at an example:
Peter didn’t realize how old Henry was until he saw his daughter.
In this KnowRef instance, even BERT fails to resolve he to Peter. This changes if Henry is replaced with the name Harriet (and his with her).
Can we more strongly discourage this lexical focus in models? We devised a data-augmentation trick for KnowRef and similar datasets called antecedent switching for this purpose. In antecedent switching, we duplicate each KnowRef instance but switch the antecedents’ positions. In the vast majority of cases, this should switch the correct answer as well. Our thought was that exposing models to both duplicates would teach them to redirect their focus from the candidates themselves (with their gender and number cues) to the context around them (where common sense should kick in).
| Model | Accuracy | Δ |
| BERT | 0.71 | +10% |
| E2E | 0.61 | +3% |
| E2E (KnowRef + CoNLL training) | 0.66 | +1% |
Table 2: Accuracy and gain for several models on the KnowRef test set after augmenting the training set.
We found that models trained on the augmented data performed much better, as you can see in Table 2. We also show that, promisingly, antecedent switching yields improvements on other tasks as well. We use it to achieve state-of-the-art accuracy and gender balance on the GAP coreference task (opens in new tab), which was designed explicitly to test gender bias. Fine-tuning BERT on an augmented version of the GAP training data improves test performance by 1.9 F1 points.
The flurry of recent progress on the WSC shows that common sense remains an important frontier for AI. We hope that our KnowRef corpus will spur further progress and provide researchers with a more reliable means to benchmark results. We look forward to seeing you at ACL 2019 to discuss this work in more detail!



