This paper has been accepted at the 18th European Conference on Computer Vision (ECCV 2024) (opens in new tab), the premier gathering on computer vision and machine learning.

Biomedical vision models are computational tools that analyze medical images, like X-rays, MRIs, and CT scans, and are used to predict medical conditions and outcomes. These models assist medical practitioners in disease diagnosis, treatment planning, disease monitoring, and risk assessment. However, datasets used to train these models can be small and not representative of real-world conditions, which often leads to these models performing worse in actual medical settings. To avoid misdiagnoses and other errors, these models must be rigorously tested and adjusted to perform reliably across different conditions.
To mitigate the dataset challenge of not having enough diverse data and to improve the testing of biomedical vision models, we developed “RadEdit: Stress-testing biomedical vision models via diffusion image editing,” presented at ECCV 2024. Aligned with the Microsoft Responsible AI principles of reliability and safety, RadEdit helps researchers identify when and how models might fail before they are deployed in a medical setting. RadEdit uses generative image editing to simulate different dataset shifts (e.g., a shift in the patients’ demographics), helping researchers to identify weaknesses in the model. By employing text-to-image diffusion models trained on a wide array of chest X-ray datasets, RadEdit can generate synthetic yet realistic X-rays.
RadEdit’s approach involves using multiple image masks (binary images representing designated regions of a reference image), as illustrated in Figure 1, to limit changes to specific areas of the image, therefore preserving their integrity. It generates synthetic datasets free from spurious correlations and artifacts, addressing shortcomings in existing editing techniques. Traditional editing techniques often overlook biases within the generative model, leading to synthetic data that perpetuate these biases. Alternatively, these other editing techniques restrict edits to the point of unrealistic outputs.
Spotlight: blog post

GraphRAG auto-tuning provides rapid adaptation to new domains
GraphRAG uses LLM-generated knowledge graphs to substantially improve complex Q&A over retrieval-augmented generation (RAG). Discover automatic tuning of GraphRAG for new datasets, making it more accurate and relevant.
How RadEdit works
RadEdit improves biomedical image editing using three key inputs, as illustrated in Figure 1:
- Text prompt: Defines the desired modifications. For example, a disease can be added with a description like “Consolidation”
- Edit mask: A binary mask indicating the main area to be modified, such as the “right lung”
- Keep mask: A binary mask outlining parts of the original image to be preserved, like the “left lung”
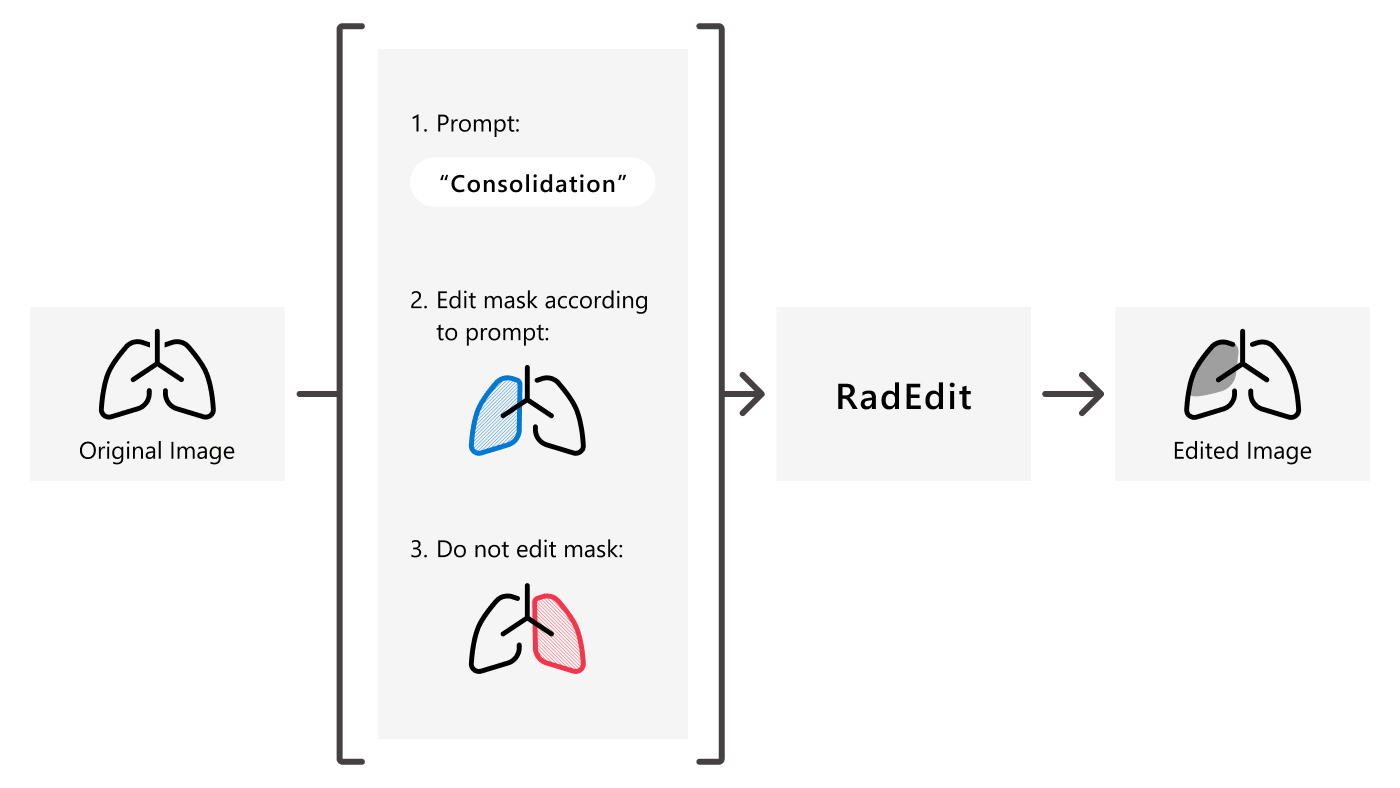
RadEdit depends on a diffusion model for image editing, where the image is first converted to a latent noise representation by inverting the diffusion generative process. The noise representation is then iteratively denoised over multiple time steps. During each step, RadEdit:
- Uses the text prompt to conditionally generate pixels within the edit mask with classifier-free guidance.
- Generates the remaining pixels based on the original image and edited area.
- Replicates the content of the original image within the “keep” mask, ensuring that this area remains unaltered.
Finally, a quality check ensures that the edited image is faithful to the editing prompt. RadEdit uses Microsoft’s BioViL-T to compute an image-text alignment score that we can then use to filter out low-quality and unfaithful edits.
Simulating dataset shifts
A key feature of RadEdit is its ability to simulate dataset shifts with precise spatial control for comprehensive model performance evaluation. This includes differences in image acquisition, the appearance of underlying pathologies, and population characteristics.
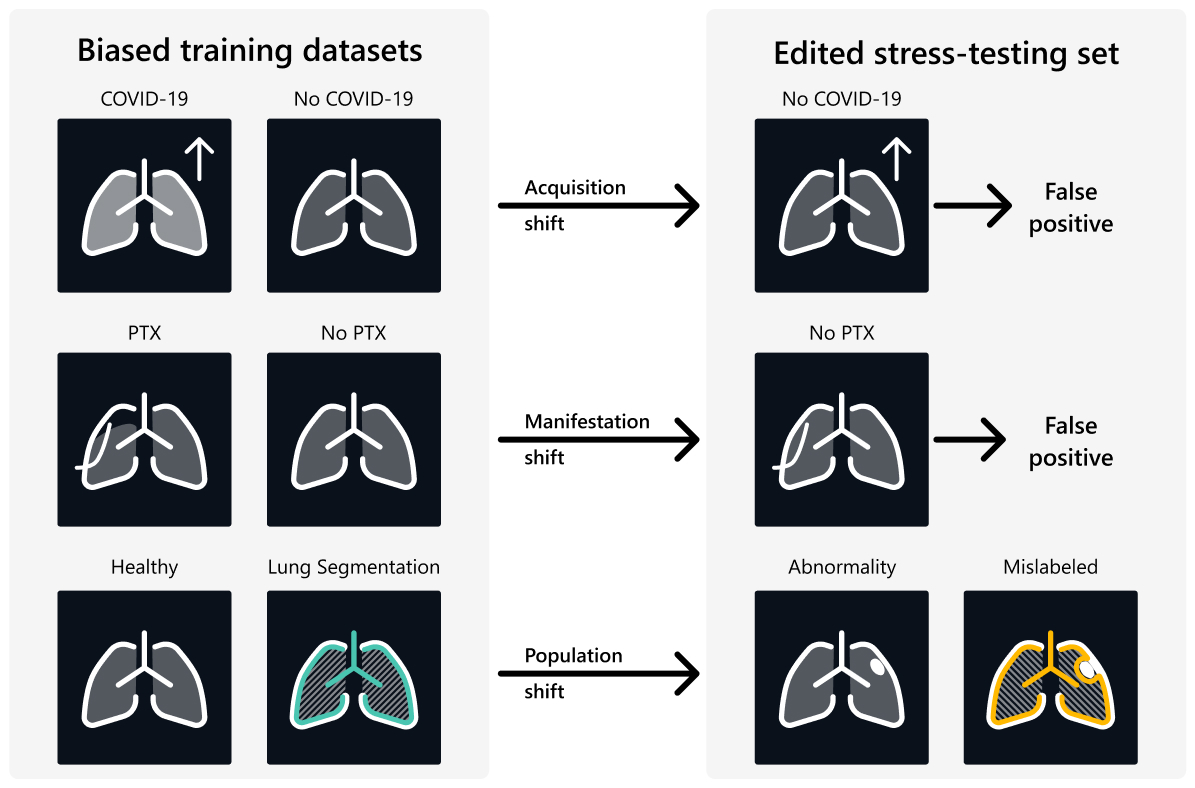
Particularly notable is RadEdit’s ability to simulate image variations from different sources (e.g., different hospitals), helping researchers identify potential biases in models trained solely on data from one source. For example, in a COVID-19 study, if all positive cases in a dataset come from a single hospital and all negative cases come from a different hospital, a model trained on detecting COVID-19 might over-rely on hospital-specific indicators from the X-ray images. Among others, we considered the laterality markers in the corners of an X-ray (e.g., a highly visible letter “L” on the left side of the X-ray) as well as the amount of black space on the image edges to be hospital-specific indicators. To test if a model relies too much on differences in image acquisition, we created synthetic data using RadEdit, where we removed COVID-19 features while retaining hospital-specific indicators. After creating the synthetic dataset with the COVID-19 features no longer present, we can test if the COVID-10 detection model still predicts COVID-19. This would indicate that the model is biased with respect to hospital-specific indicators.
RadEdit can also remove specific diseases, like pneumothorax (collapsed lung), from an image while keeping treatment features like chest drains. This helps researchers understand how models detect and understand “visual shortcuts.” Because RadEdit maintains the size and location of the main anatomical structures (like lungs, ribs, and heart), it can also be used to stress-test segmentation models. For example, RadEdit can add rare abnormalities or medical devices to lung images to test how well segmentation models handle new variations, ensuring they generalize accurately across different populations. Figure 2 illustrates these three examples of stress-testing scenarios.
Stress-testing multimodal models
We have used RadEdit to stress-test image classification and segmentation models, and we see potential for future applications in complex multimodal tasks like generating radiology reports. RadEdit can help identify limitations in multimodal large language models (MLLMs) like Microsoft’s MAIRA-1 and MAIRA-2, especially when dealing with rare conditions or unusual combinations of findings not well-represented in the training data. These MLLMs take one or more radiological images and relevant clinical information as input to produce detailed text reports.
RadEdit can generate synthetic image-report pairs for challenging scenarios. For example, manually editing a report to describe a rare combination of findings and then using RadEdit to edit the corresponding image, creates a valuable test case for the MLLM. This approach allows us to stress-test MLLM with diverse synthetic data, identifying weaknesses or biases and ensuring the model is more robust in real-world scenarios. This is a crucial step for using these models safely and effectively in clinical settings.
Implications and looking forward
RadEdit offers significant advantages for the biomedical research community. It helps identify biases and blind spots before deployment, helping to ensure that biomedical vision models perform reliably in clinical settings. By simulating dataset shifts, RadEdit reduces the need to collect additional evaluation data, saving time and resources.
RadEdit is applicable to a wide range of settings and can be used to stress-test state-of-the-art foundation models like Microsoft’s Rad-DINO (opens in new tab) and BiomedParse (opens in new tab). By integrating RadEdit into their research workflow, researchers can validate that their biomedical vision models are not only state-of-the-art but also more prepared for the complexities of real-world deployment. In the future, we envision RadEdit being applied to more complex multimodal tasks, such as generating radiology reports.
The code for RadEdit as well as the weights of the diffusion model we used can be found under https://huggingface.co/microsoft/radedit (opens in new tab).
Acknowledgments
We would like to thank our paper coauthors: Fernando Pérez-García, Sam Bond-Taylor, Pedro P. Sanchez, Boris van Breugel, Harshita Sharma, Valentina Salvatelli, Maria T. A. Wetscherek, Hannah Richardson, Matthew P. Lungren, Aditya Nori, and Ozan Oktay, as well as all our collaborators across Microsoft Cloud for Healthcare and Microsoft Health Futures.
RadEdit is intended for research purposes only and not for any commercial or clinical use.