The recent surge in large language model (LLM) use is causing significant challenges for cloud providers, requiring them to deploy more GPUs at an unprecedented rate. However, the capacity to provision the power needed to run these GPUs is limited, and with demand for computation surpassing supply, it is not uncommon for user queries to be denied. Therefore, any approach to making the existing infrastructure more efficient—enabling it to serve more queries faster under the same power budget—can have very tangible benefits to both cloud providers and users.
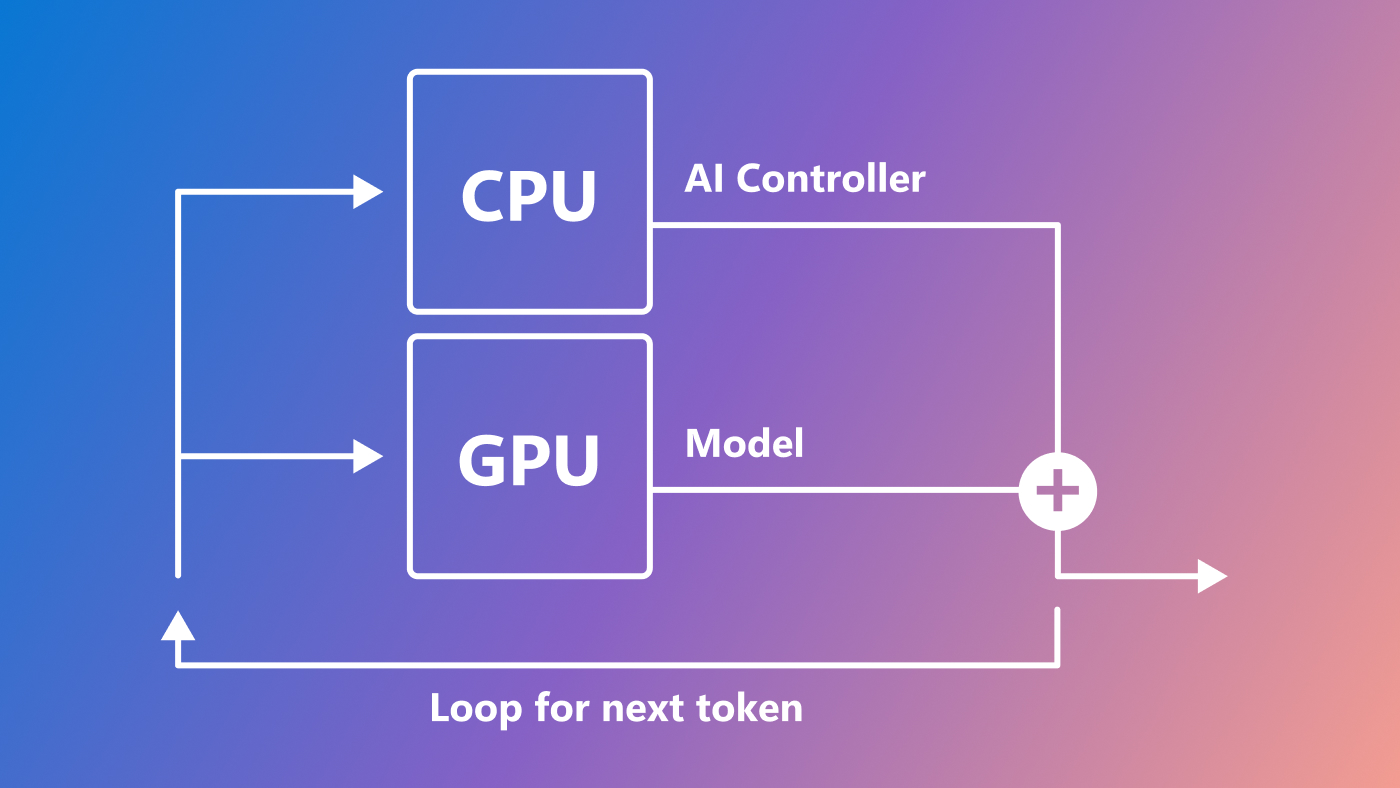
One aspect of LLM inference that currently limits efficient use of resources is that it has two distinct phases with different characteristics: the prompt phase and the token-generation phase. During the prompt phase, LLMs process all user input, or prompts, in parallel, efficiently utilizing GPU compute. However, during the token-generation phase, LLMs generate each output token sequentially and are limited by GPU memory bandwidth. Even when employing state-of-the-art batching mechanisms, the discrepancy between these two phases results in low overall hardware utilization, leading to much higher costs when offering LLMs to users. Figure 1 illustrates the differences between these two phases.

Splitting the phases with Splitwise
At Azure Research – Systems, we tackled this by creating Splitwise, a technique designed to optimally utilize available hardware by separating the prompt computation and token-generation phases onto separate machines. This approach is underpinned by the insight that prompt processing and token-generation are distinct in their computational, memory, and power requirements. By separating these two phases, we can enhance hardware utilization during both phases. Our paper, “Splitwise: Efficient Generative LLM Inference Using Phase Splitting,” details our methods for developing and testing this technique, including an exploration of how different types of GPUs perform during each phase.
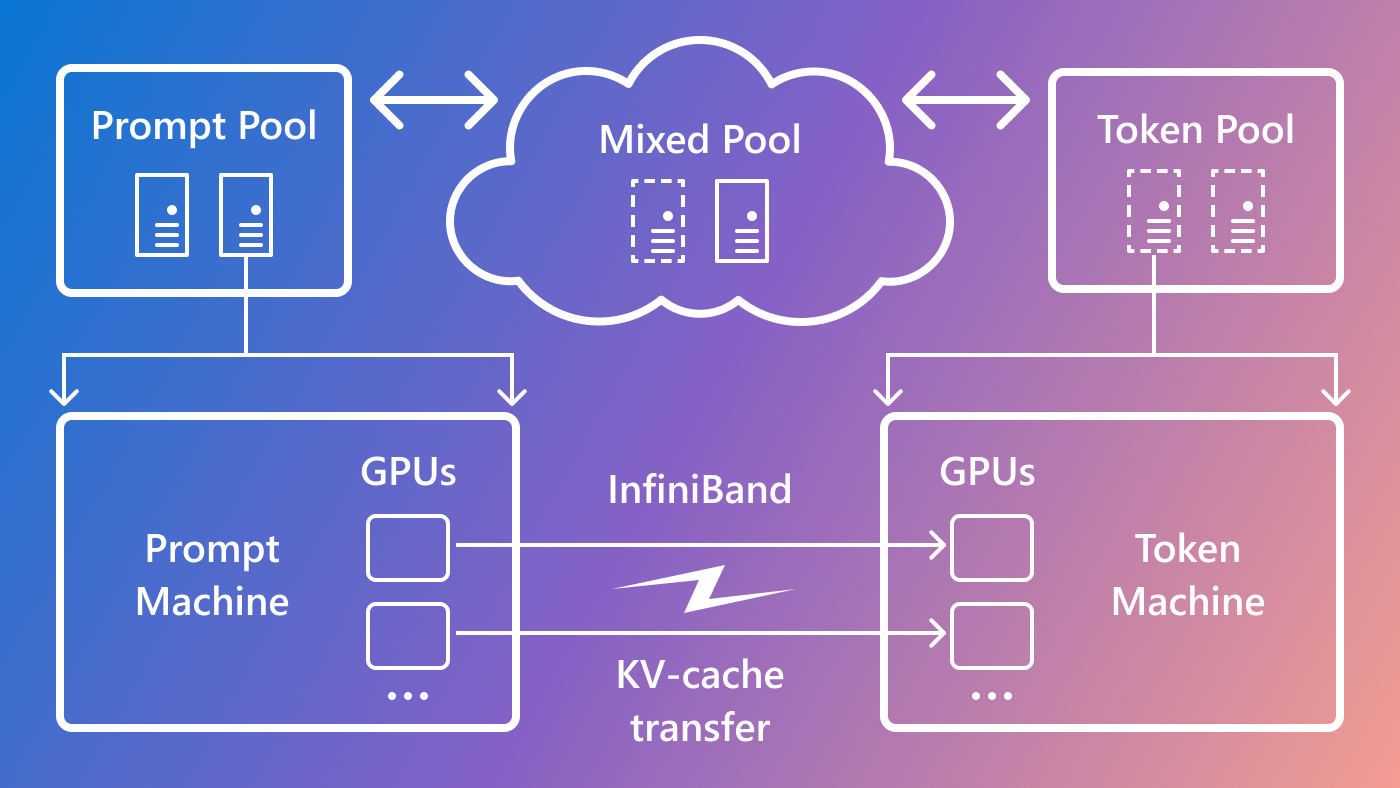
To create a sustainable approach for GPU provisioning, we used Splitwise to design GPU clusters with three primary objectives: maximizing throughput, minimizing costs, and reducing power. In addition to separating the two LLM inference phases into two distinct machine pools, we include a third machine pool for mixed batching across the prompt and token phases, sized dynamically based on real-time computational demands. Lastly, we transferred the state context (i.e., KV-cache in the LLM transformer attention layers) from the prompt to the token machines over InfiniBand without any perceivable latency impact to the user. This high-level system architecture is illustrated in Figure 2.
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
Tests show Splitwise maximizes throughput while lowering costs
To evaluate its performance, we used Splitwise to design clusters with different types of GPUs, including NVIDIA DGX-A100 and DGX-H100, while optimizing cost, power, and throughput under specific latency service level agreements (SLAs) for each query. Table 1 shows the machine types we used for each cluster design. Our application of Splitwise encompassed two use cases: code and conversation using the Llama-2-70B (opens in new tab) and BLOOM-176B (opens in new tab) LLMs.

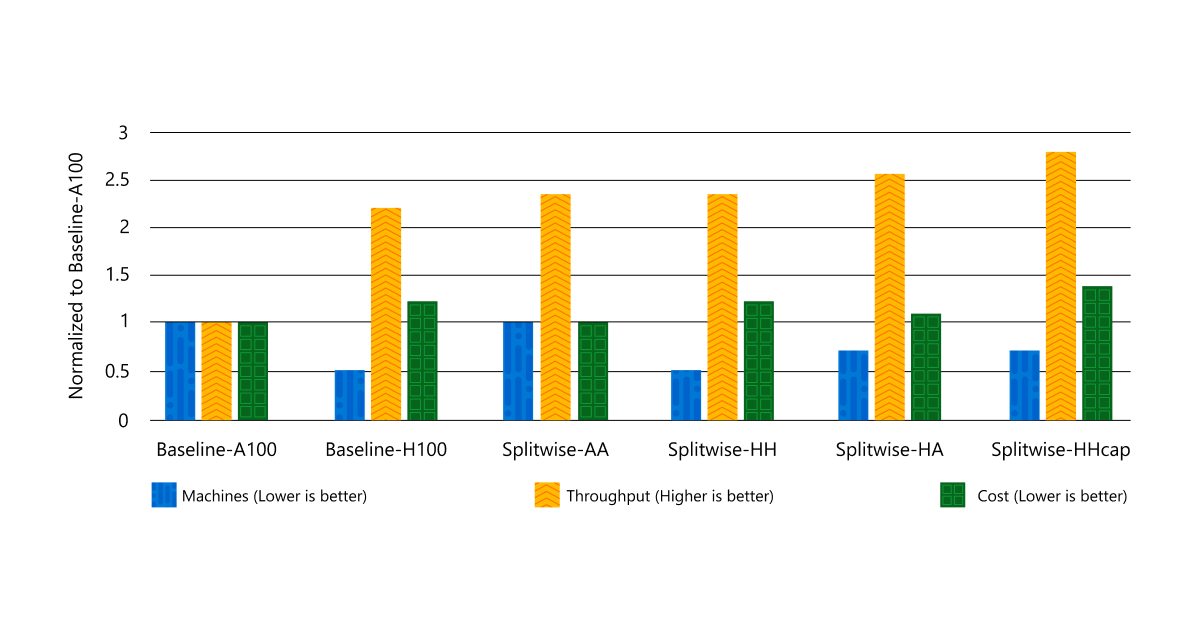
Our findings demonstrate that Splitwise successfully achieves our three goals of maximizing throughput, minimizing costs, and reducing power. Through our evaluation, we observed that the Splitwise cluster design can maximize throughput at the same cost compared with an A100 baseline cluster. Moreover, Splitwise delivers much higher throughput while operating within the same provisioned power constraints as the baseline cluster. Figure 3 shows that compared with Baseline-H100, we can achieve 1.4x higher throughput at 20 percent lower cost. Alternatively, we can achieve 2.35x more throughput with the same cost and power budgets.
Looking forward
Splitwise marks a leap toward efficient, high-performance LLM deployments. By separating the prompt and token phases, we can unlock new potential in GPU use. Looking forward, we at Microsoft Azure envision tailored machine pools driving maximum throughput, reduced costs, and power efficiency, and we will continue to focus on making LLM inference efficient and sustainable.
Our approach is now part of vLLM (opens in new tab) and can also be implemented with other frameworks.
Acknowledgements
This work was done in collaboration with our intern, Pratyush Patel from the University of Washington. We also appreciate the help and guidance of Suriya Kalivardhan, Gopi Kumar, and Chetan Bansal.