At Microsoft Bing, our mission is to delight users everywhere with the best search experience. We serve a diverse set of customers all over the planet who issue queries in over 100 languages. In search we’ve found about 15% of queries submitted by customers have misspellings. When queries are misspelled, we match the wrong set of documents and trigger incorrect answers, which can produce a suboptimal results page for our customers. Therefore, spelling correction is the very first component in the Bing search stack because searching for the correct spelling of what users mean improves all downstream search components. Our spelling correction technology powers several product experiences across Microsoft. Since it is important to us to provide all customers with access to accurate, state-of-the-art spelling correction, we are improving search so that it is inclusive of more languages from around the world with the help of AI at Scale.
We have had high-quality spelling correction for about two dozen languages for quite some time. However, that left users who issued queries in many more languages dealing with inferior results or manually correcting queries themselves. In order to make Bing more inclusive, we set out to expand our current spelling correction service to 100-plus languages, setting the same high bar for quality that we set for the original two dozen languages. We’ve found we need a very large number of data points to train a high-quality spelling correction model for each language, and sourcing data in over 100 languages would be incredibly difficult logistically—not to mention costly in both time and money.
A speller for 100-plus languages in Microsoft
Despite these challenges, we have recently launched our large-scale multilingual spelling correction models worldwide with high precision and high recall in 100-plus languages! These models, technology we collectively call Speller100, are currently helping to improve search results for these languages in Bing. This is a huge step forward, especially when considering that spelling correction was available for just a few dozen languages a short time ago. This was made possible by leveraging recent advances in AI, particularly zero-shot learning combined with carefully designed large-scale pretraining tasks, and we also draw on historical linguistics theories.
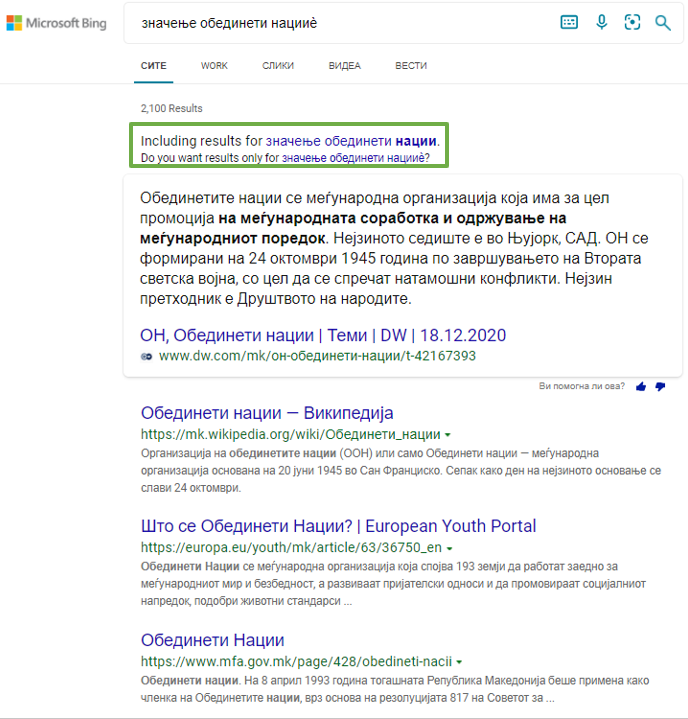
Should be spelled as {значење обединети нации}
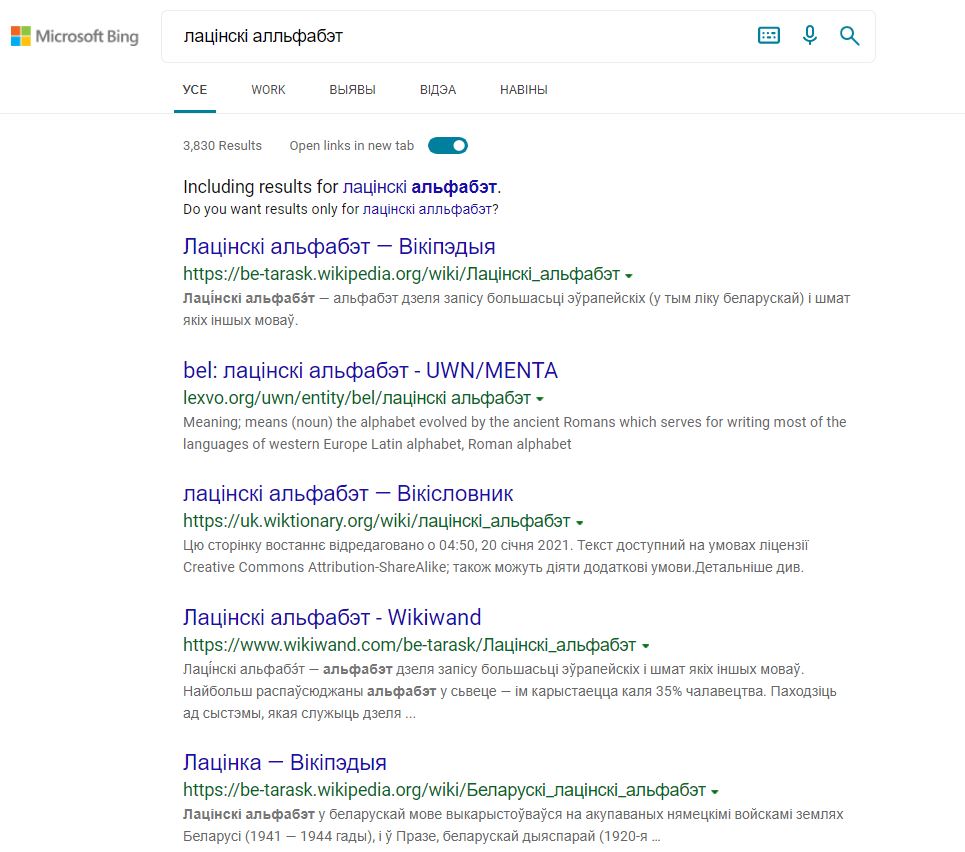
Should be spelled as {лацінскі альфабэт}
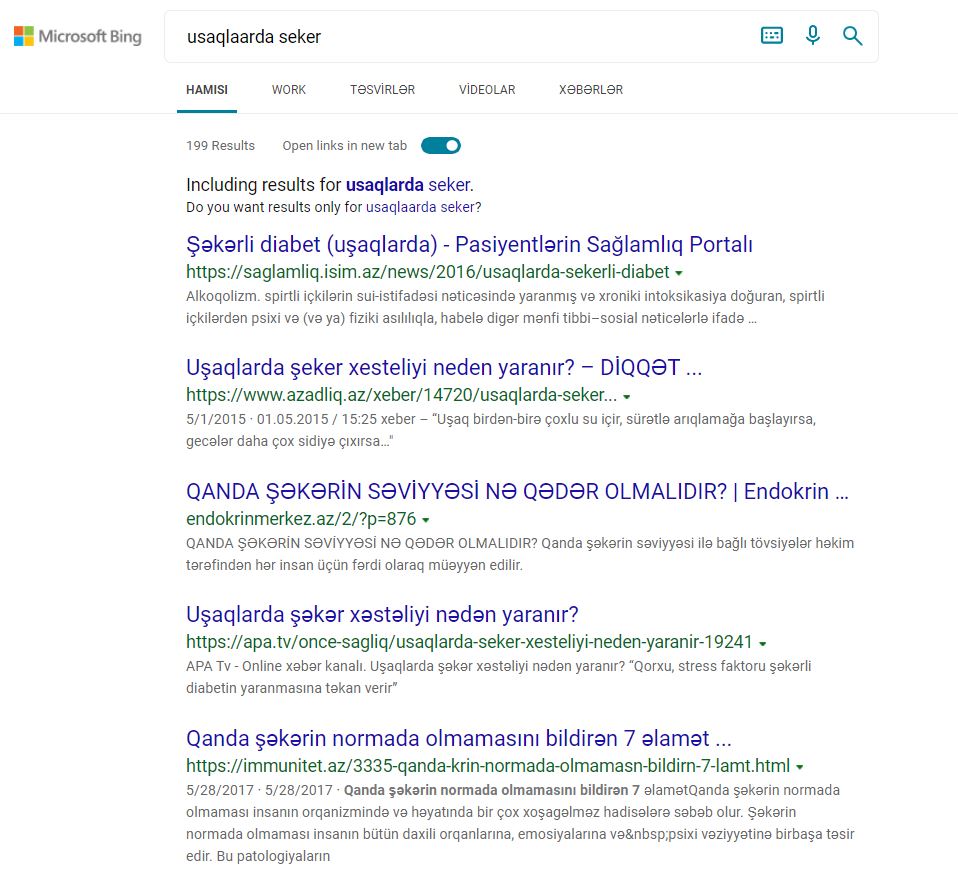
Should be spelled as {usaqlarda seker}
Should be spelled as {طبی کتابونه}
translation: {phases of the moon}
Should be spelled as {ázy mesiaca}
translation: {History of Russia}
Should be spelled as {istoria rusilor}
Traditionally, spelling correction solutions have leveraged noisy channel theory and made great improvements in building better statistical error models and language models. Search engines have long used web documents for robust language models. For precise and high-performing error models, search engines have largely leveraged user feedback on autocorrection recourse links. This practice has been very effective, especially for languages where user feedback data has been gathered on a large scale. For a language with very little web presence and user feedback, it’s challenging to gather an adequate amount of training data.
In order to create spelling correction solutions for these latter types of languages, models cannot rely solely on training data to learn the spelling of a language. The foundation of Speller100 is based on the concept of language families—for our purposes, larger groups of languages based on similarities that multiple languages share. Another concept, zero-shot learning, allows a model to accurately learn and correct spelling without any additional language-specific labeled training data. Imagine someone had taught you how to spell in English and you automatically learned to also spell in German, Dutch, Afrikaans, Scots, and Luxembourgish. That is what zero-shot learning enables, and it is a key component in Speller100 that allows us to expand to languages with very little to no data.
Unlocking the power of task-driven pretraining
We’ve seen significant advancements in natural language processing (NLP) in the last year through large Transformer networks like BERT, UniLM, and DeBERTa. These models are trained with tasks like Masked Language Model (MLM), next-sentence prediction, and translation. Even though commonly used WordPiece or SentencePiece subword segmentation algorithms break down words into smaller constituents, existing pretraining tasks all operate at the word, phrase, or even sentence level for semantic understanding. Spelling, however, is a different task altogether.
Broadly speaking, there are two types of spelling errors. One is non-word error, and the other is real-word error. Non-word error occurs when a word is not in the vocabulary for a given language at all; real-word error occurs when the word itself is valid but doesn’t fit in the larger context. Both errors are character-level mutations within reasonable edit distance to the desired words.
At the core, spelling correction is about building an error model and a language model. The MLM task makes very good language models, even for those languages with very little web presence. However, we haven’t seen much innovation on the error model for pretraining tasks. For large-scale language family–based multilingual spelling correction, we designed a spelling correction pretraining task to enrich standard Transformer-based models.
Spelling correction is a sequence-to-sequence (s2s) problem that converts a text with typos into its correct form. Also, if typos are considered noises in text, spelling correction can be considered as a denoising process that converts corrupted text into its original text. Deep learning is the state-of-the-art technology used for s2s applications.
Our deep learning approach is inspired by Facebook AI Research’s BART (opens in new tab), a word-level denoising s2s autoencoder pretraining for natural language generation (NLG), translation, and comprehension. BART is trained by corrupting text with an arbitrary noise function and learning a model to reconstruct the original text. Our model differs from BART in that we frame spelling correction as a character-level s2s denoising autoencoder problem and build out pretraining data with character-level mutations in order to mimic spelling errors. We have designed noise functions to generate common errors of rotation, insertion, deletion, and replacement. See the figure below for examples of these common errors.

The use of a noise function significantly reduced our demand on human-labeled annotations, which are often required in machine learning. This is quite useful for languages for which we have little or no training data. With a noise function, we can obtain a pretrained model (see figure below), and then fine-tuning the model becomes zero-shot or few-shot learning scenarios for those languages.
Thanks to noise functions, we no longer need a large corpus of misspelled queries and can make do with regular text extracted from web pages. This text can easily be extracted through web crawling, and there is a sufficient amount of text for the training of hundreds of languages. It then becomes practical to build a speller using a deep-based s2s model for these languages.
Here is the model architecture:
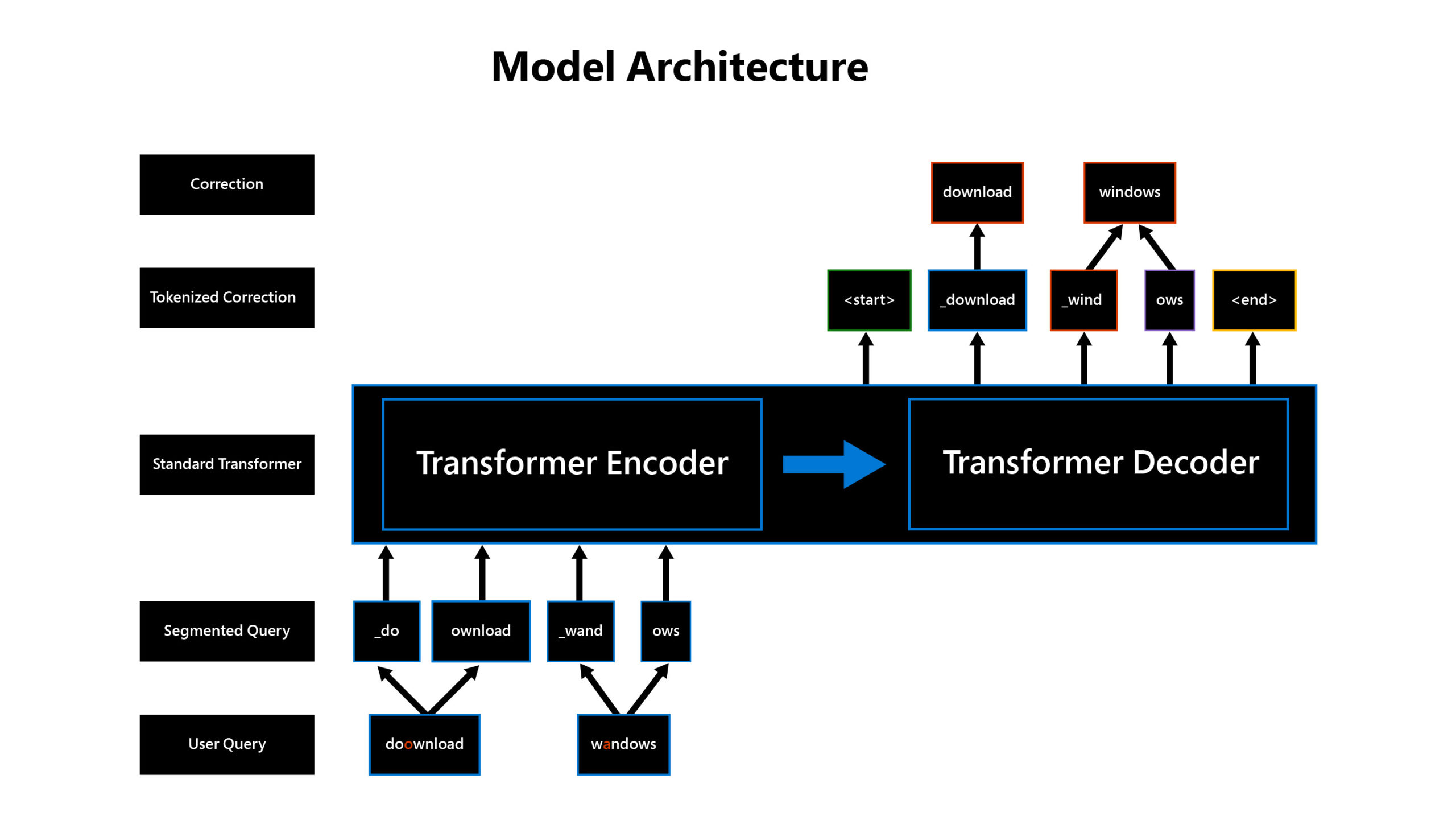
This pretraining task proves to be a first solid step to solve multilingual spelling correction for 100-plus languages. It helps to reach 50% of correction recall for top candidates in languages for which we have zero training data.
Utilizing a language’s family for efficient and effective zero-shot learning
50% of recall is obviously not good enough for a production system. In the case of Bing, where roughly 15% of queries are misspelled, that would mean that 7.5% of all queries would not have proper spelling correction. For languages with zero training data, our next design proves to be crucial too. We tapped into the zero-shot learning property of deep models effectively and efficiently by producing models to target language families.
It’s well known in the historical linguistics world that languages are rarely isolated. Most of the world’s languages are known to be related to others. A group of languages descended from the same ancestor form a language family. They share a lot in orthography—the spelling and other written conventions of a language—which stems from morphological and phonetical similarities.
Below is an illustration of orthographic similarities between languages in the Germanic languages (opens in new tab).
| English | Dutch | Afrikaans | German | Luxembourgish |
|---|---|---|---|---|
| two | twee | twee | zwei | zwee |
| blood | bloed | bloed | Blut | Blutt |
| finger | vinger | vinger | Finger | Fanger |
| download | downloaden | aflaai | herunterladen | eroflueden |
This orthographic, morphological, and semantic similarity between languages in the same group makes a zero-shot learning error model very efficient and effective. High-quality error model training data is abundant in high-resource languages, like English and German in the Germanic language family; we also have a reasonable amount of data in Dutch; however, in the same language family, we have a severe shortage of training data in Afrikaans or Luxembourgish. Zero-shot learning makes learning spelling prediction for these low-resource or no-resource languages possible. We simply build a dozen or so language family–based models to maximize the zero-shot benefit and keep the model compact enough for runtime. This proves to be optimal for both relevance and engineering.
The user experience impact of Speller100
We believe Speller100 is the most comprehensive spelling correction system ever made in terms of language coverage and accuracy. With this technology, we have improved the search results for all Bing users by expanding accurate spelling correction to over 100 languages. We have observed a double-digit improvement in both spelling correction precision and recall. After conducting Bing online A/B testing, here are the results:
- The number of pages with no results reduced by up to 30%.
- The number of times users had to manually reformulate their query reduced by 5%.
- The number of times users clicked on our spelling suggestion increased from single digits to 67%.
- The number of times users clicked on any item on the page went from single digits to 70%.
These are great indications that we have made our users’ experience better! Shipping Speller100 to Bing is obviously just the first step. We hope to implement this technology in many more Microsoft products soon.
If you are interested in applying the latest deep learning techniques to innovate in search, our Search and AI team is hiring globally (opens in new tab).