Microsoft researchers are delving beyond the boundaries of information retrieval to optimize how we access and manage information in different areas. Not only are they advancing the realm most synonymous with information retrieval, search engines, but they are also researching new information access processes, utilizing machine learning in email intent identification and task management applications. In these latter areas, one goal is to directly improve how an individual’s time is spent when interacting with information, whether that happens in the email inbox or with the help of a digital assistant.
Three papers by Microsoft researchers have brought new techniques and ideas to the information retrieval field and will be presented at the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval (opens in new tab) in Paris this month. There are a number of other papers and workshops being presented by Microsoft researchers at the conference: a full schedule for SIGIR 2019 can be found here (opens in new tab).
Spotlight: On-demand video

AI Explainer: Foundation models and the next era of AI
Explore how the transformer architecture, larger models and more data, and in-context learning have helped advance AI from perception to creation.
One of the papers being presented comes from researchers in the Adaptive Systems and Interaction group in MSR AI (opens in new tab). These researchers have specifically created a web crawl scheduling algorithm that allows search engines to gather updated webpage information more efficiently under politeness constraints. In other words, as Microsoft researcher Andrey Kolobov puts it, this research makes a search engine “a better citizen of the web.”
Microsoft researchers will be presenting two additional papers at the conference that focus on people’s interaction with technology.
In “Context-Aware Intent Identification in Email Conversations (opens in new tab),” researchers work to understand email intents, an important step toward increasing people’s productivity when interacting with their email. After analyzing annotated email intents, the researchers propose a deep learning model that incorporates context to identify email intents.
In “Task Completion Detection (opens in new tab),” researchers from the Knowledge Technologies and Intelligent Experiences (opens in new tab) and Language and Information Technologies (opens in new tab) groups collaborate on building technologies that help people engage more efficiently with their task lists. This paper describes deep learning models that can make accurate predictions about whether a listed task has already been completed.
Better task management using task completion detection
Intelligent systems such as digital assistants (Cortana, Alexa, and others) store and remind people about their pending personal and work tasks. Tasks can be explicitly specified by users of these systems (for example, tasks added to to-do lists) or inferred from other data (such as commitments made in email). Supporting task retention addresses well-known limitations in human memory and can be combined with context-sensitive reminders and attention-sensitive alerts for prospective remembering.
Despite the advantages, users of intelligent systems that store and surface pending tasks face at least two challenges: (1) task lists can grow over time if new tasks get added and old tasks are not retired, making task list management a burden while lists also lose their utility; and (2) by ignoring task status, intelligent systems can notify users about tasks that they have already completed, impeding user performance on their current task. Although tasks can be set to expire after some time, this ignores task state, meaning tasks may still be active when they are marked by the system as complete. Methods to more intelligently flag and/or deprecate completed tasks are therefore desirable.
“Methods to automatically detect task completion can be used in intelligent systems to help people focus only on the tasks that need their attention.” – Ryen W. White, Partner Research Manager, MSR AI
In “Task Completion Detection (opens in new tab),” Microsoft researchers Ryen White, Ahmed Hassan Awadallah, and Robert Sim tackle the challenge of automatically determining if a pending task is complete. They focus on a notification scenario in a digital assistant, where the challenge is to only remind users about tasks they have not yet done. The researchers introduce this novel machine learning problem and show that the completion of pending tasks by users can be accurately detected via machine learning models trained on user data. Using millions of logged commitment tasks (for example, “I will send you the report by EOD”) found in email from consenting users of Microsoft Cortana, the researchers analyzed trends in task completion prior to the candidate notification time, per task priority, task intent, and timing (see Figure 1).

(opens in new tab) Figure 1: Percentage of tasks completed by the candidate notification time tn (i.e., task initiation (ti) + days passed since ti (d)). The following completion distributions are shown: (i) all tasks (solid line) and tasks with priority language (dashed line), (ii) three most common task intents: call, email, and investigate (top to bottom), and (iii) by the relative split of weekend days and weekdays between ti and tn (limited to cases where d=2 days). Error bars denote standard error of the mean (±SEM).
High priority commitment tasks are completed more quickly, as are telephone call tasks, and some that require emailing (the remainder may be more complex and require more time). Tasks requiring investigation typically take longer to complete. The distribution of weekdays and weekend days between task creation and the candidate notification time also affects the likelihood of task completion. The researchers use these and similar signals (such as words and phrases in the commitment text) to train deep learning models to automatically detect task completion, with prediction accuracy exceeding 80 percent.
The high accuracy of the models is promising for intelligent systems, which can be enhanced with task completion detection capabilities. These capabilities can be used in many applications to help people focus on tasks requiring user involvement (versus tasks that have already been done), ranging from suppressing notifications for completed tasks to task ranking and prioritization.
The researchers are exploring enhancements to the task completion detection models using more sophisticated algorithms, collecting new data from different sources and integration efforts to obtain more signals related to task completion, and expanding to other application scenarios and task types beyond commitments. Beyond log-based studies, designers of intelligent systems need to work directly with their users to understand how they will react to this new type of task support.
The researchers hope that these results pave the way toward enabling intelligent systems to work in tandem with their users to help them more efficiently manage their tasks.
Using context and understanding intent to improve the email experience
Email continues to be one of the most important means of online communication. People spend a significant amount of time sending, reading, searching and responding to email to manage tasks, exchange information, and more. Email is particularly popular for work-related communications. A recent survey (opens in new tab) showed 86 percent of professionals named email as their favorite mode of communication.
Understanding the intent behind email conversations is a very important problem since it could enable us to create new intelligent experiences to help people be more productive in how they handle their emails. Therefore, studying intent led researchers to a deep learning model for automatically inferring intents at a contextual level.
In ”Context-Aware Intent Identification in Email Conversations (opens in new tab)”, Microsoft researchers Wei Wang, Saghar Hosseini, Ahmed Hassan Awadallah, Paul Bennett, and Chris Quirk used a large-scale publicly available email dataset to characterize intents in enterprise email and propose methods for improving intent identification in email conversations, resulting in a deep learning model that does just that. They also studied how incorporating more context (such as the full message body, thread, or other metadata) could improve the performance of the intent identification models. To create a deep learning model, researchers first needed to gather more data on intents in email conversations.

(opens in new tab) Figure 2: Frequency of different intents in a sample of workplace emails
To better understand the different intents that occur in workplace communications, researchers employed annotators to label a large sample of workplace emails form a publicly available email collection. Figure 2 shows different intents and the frequency by which they appear in that sample. The figure shows that information exchange and task management are the most frequent intents in enterprise emails; followed by scheduling and planning and social communications.
Researchers also found that email messages usually contain more than one intent, and the intents are not mutually exclusive. For example, an email message could be sending a reminder about a deadline and requesting an action to be completed before the deadline. The analysis showed that approximately 55.2% of messages contain a single intent, 35.8% contain two intents, and 9.0% contain three or more intents.
“Understanding and detecting the purpose behind email conversations can enable intelligent systems to improve productivity by helping people process, respond to, and take actions on emails quickly and efficiently” – Ahmed Hassan Awadallah, Principal Research Manager, MSR AI
To better understand how to automate intent detection in emails, researchers studied the effect of having additional context (from the full email body or thread) on human annotators. They employed two sets of human annotators to identify the intent in the same set of email conversations. One of the groups had access to the additional context, and the other did not. The analysis showed that human annotators perform far better in intent detection when they are provided with contextual information. Similarly, the researchers argue that machine learning models for identifying intent can also benefit from the contextual information. The researchers propose a deep learning model (see Figure 3) that can leverage both the text where the intent was manifested and additional context to automatically detect the intent.
The model created uses several steps to extract intent at a contextual level. First, a sentence encoder analyzes words and encodes them into vectors at the sentence level. Next, a context encoder aims to encode each sentence in the context to a fixed vector space. Using a feature fusion layer, the researchers aim to augment every word in the sentence with the relevant information from the context. Finally, the target sentence representation generated by the fusion layer is fed to a classifier to perform the prediction.
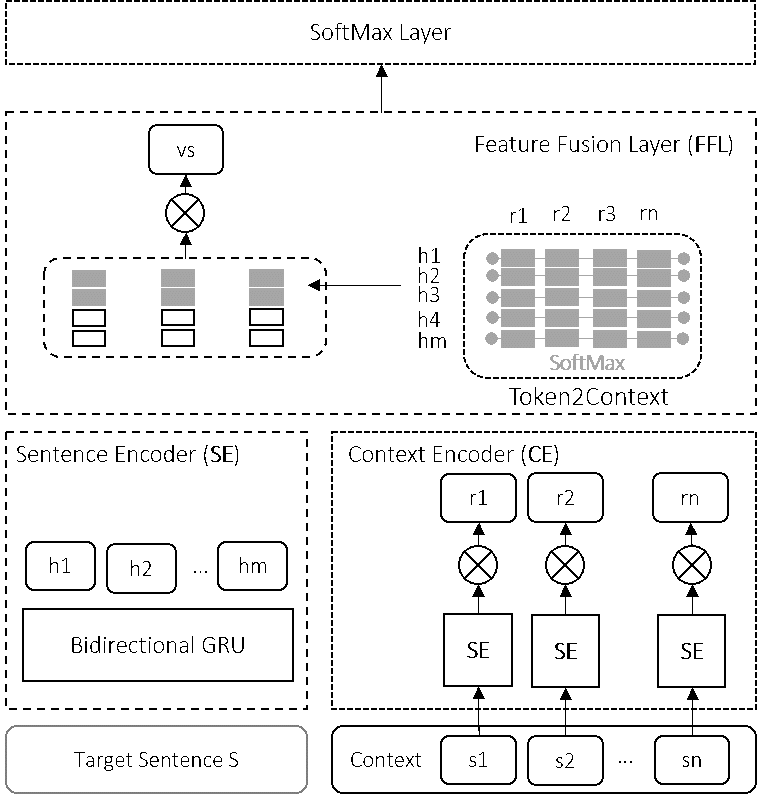
(opens in new tab) Figure 3: The proposed model consists of a Sentence Encoder (SE) to represent the sentence, a Context Encoder (CE) to represent the context, and a fusion layer to augment the sentence features with context features allowing the classifier access to features extracted from the context while maintaining separate feature spaces for the target sentence and the context.
Results (see Figure 4) show that incorporating the context can significantly help in automatic detection of intent and that the more context (in terms of number of sentences) that can be incorporated, the better the overall performance.
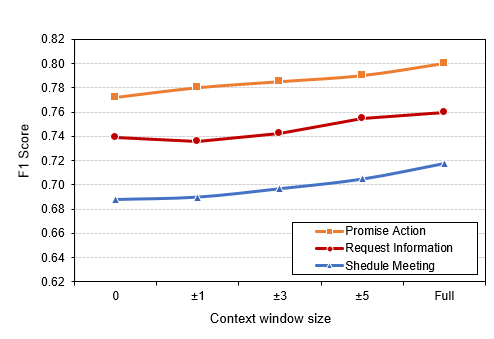
(opens in new tab) Figure 4: The performance of the proposed model for different context window sizes.
Studying and detecting these intents in enterprise communications enables us to integrate machine intelligence into email systems and build smart email clients to provide more value for email users. For instance, understanding intents (like intent to schedule a meeting) enables us to create new intelligent experiences that can offer to assist the user with scheduling the meeting.
Understanding that a user is making a commitment or a promise to perform a certain action allows the system to automatically add these tasks to a to-do list to help users track these tasks. Additionally, understanding the intent of requesting information could enable the system to find relevant documents and share them on the user’s behalf. Such actions could be recommended to users and performed on their behalf upon confirmation. They could be surfaced in email clients or offered by a digital assistant.
Optimizing crawl schedules under politeness constraints
When online information retrieval services such as Bing Search and Bing Q&A select results to return in response to a user’s query, they make these decisions based on pre-processed copies of the content of webpages stored in the service-side index. Downloading webpages from web hosts is the responsibility of a search engine’s crawler component. As the web is a dynamic corpus, crawlers constantly face the formidable challenge of providing information retrieval services with an up-to-date view of it.
To ensure that indexed URL content is in sync with its online source, the crawler must periodically revisit and download fresh data from hundreds of billions of URLs the index is aware of. While the crawler may want to revisit URLs arbitrarily often, this would be infeasible as well as irresponsible. Websites that host the pages are willing to dedicate only a small fraction of their network bandwidth to serving crawlers’ requests, and high rates of revisiting can violate these preferences. A host may stop returning content to a crawler altogether if the crawler sends its requests too often. This makes a crawler’s job even more difficult. When deciding which URLs to revisit and when it must respect tens of millions of politeness constraints, which limit the rate at which it may request content from various hosts.
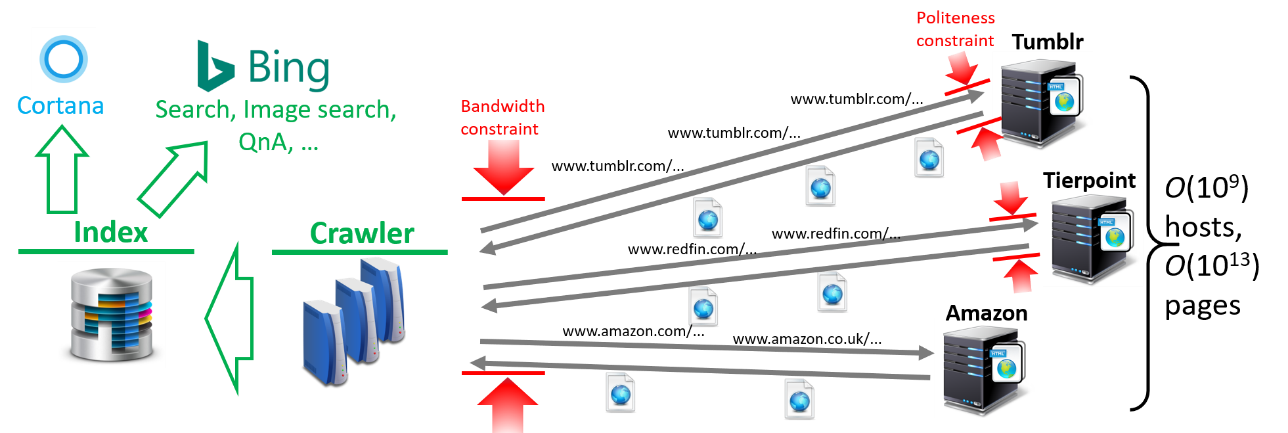
(opens in new tab) Figure 5: Web crawling overview
In the SIGIR paper titled “Optimal Freshness Crawl Under Politeness Constraints (opens in new tab),” Microsoft researchers Andrey Kolobov and Eric Horvitz, along with co-authors Eyal Lubetzky and Yuval Peres, present an efficient way to construct crawl schedules that obey politeness constraints and optimize for the freshness of online content cached in the index. Building on results from Microsoft Research’s 2018 PNAS paper on crawl scheduling (opens in new tab) that solved a version of this setting where the crawler is bound only by the limitations of its own infrastructure, this work casts crawling under politeness constraints as an inequality-constrained convex optimization problem.
In general, solving such problems can be exponentially expensive in the number of constraints. The SIGIR article’s main contribution is a low-polynomial optimal algorithm for the problem instance that models politeness-constrained freshness crawl scheduling. The approach relies on special properties of the widely studied “binary” freshness objective at the focus of many prior works including the aforementioned PNAS paper (opens in new tab).
“Optimal politeness-aware crawl scheduling will allow Bing to ensure fresh search results for its users while making full use of its computational resources and remaining a respectful citizen of the web at the same time.” – Andrey Kolobov, Principal Researcher, MSR AI
Continuing their exploration of efficient crawl scheduling jointly with Microsoft Bing in recent research presented at ICML 2019 Workshop on Reinforcement Learning for Real Life (opens in new tab), researchers at Microsoft Research have identified a broad class of freshness objectives that have the same properties as in the SIGIR and PNAS papers. Many of these objectives are more nuanced and induce better-behaved crawl scheduling policies than binary freshness. The implication of the work to be presented at SIGIR 2019 in Paris is that any of these objectives can be efficiently optimized in a politeness-aware way.
Along with the SIGIR paper describing the algorithmic side of crawl scheduling under politeness constraints, Microsoft Research and Microsoft Bing have released the dataset (opens in new tab) on which the proposed techniques were evaluated. It consists of change histories of approximately 18.5 million URLs observed by crawling these URLs daily for 14 weeks, allowing other researchers to assess scalability and efficiency of their own crawl scheduling approaches on real-world data.
The SIGIR paper’s evaluation shows that its algorithm, besides being optimal in theory, empirically outperforms the approach commonly used in practice, whereby crawl scheduling is done without regard to politeness and the crawl rates are adjusted at execution time to match the politeness constraint.
All three pieces of research will be presented in talks at the SIGIR 2019 conference. “Task Completion Detection” will be presented at 11:00am on July 23, 2019. “Optimal Freshness Crawl Under Politeness Constraints” will be presented at 1:50pm on July 23, 2019. Finally, “Context-Aware Intent Identification” will be presented at 5:40pm on July 23, 2019.