Computer vision has rapidly evolved over the past decade, allowing for such applications as Seeing AI (opens in new tab), a camera app that describes aloud a person’s surroundings, helping those who are blind or have low vision; systems that can detect whether a product, such as a computer chip or article of clothing, has been assembled correctly, improving quality control; and services that can convert information from hard-copy documents into a digital format (opens in new tab), making it easier to manage personal and business data. All this has been made possible by the evolution of convolutional neural networks (CNNs) and faster hardware that can run increasingly deeper architectures. And thanks to specialized neural accelerators for CNNs, computer vision applications that were limited to the realm of plugged-in power-hungry workstations just a few years ago can even be performed by mobile devices.
The next frontier in this natural progression is the edge. The very edge. Tiny devices that consume less power and are capable of collecting and analyzing data in a connected Internet of Things (IoT) world. Can we enable sophisticated vision intelligence on these devices? Vision on such devices could open up new scenarios. Imagine the walking stick of a person who is blind or has low vision outfitted with a small camera that can detect a dog, vehicle, or other object and provide feedback that would allow the person to avoid a potential accident or a retail system that can detect an empty shelf and alert a manager that a high-demand product needs to be restocked or reordered. This would not only enable users of such technology to understand their surroundings in new ways, but it would also give them more control over their data by retaining sensitive information on the edge instead of sending it over the network to the cloud for processing, which could compromise it.
But today’s vision architectures require large amounts of memory and compute, more than is available on typical IoT devices. To address this challenge, we introduce RNNPool, a pooling operator that can rapidly reduce the size of intermediate image representations to allow for the analysis of images on small memory- and compute-constrained devices. When used as a replacement for CNN blocks, RNNPool enables CNN models with much fewer layers, smaller intermediate representations, and hence lesser computational requirement while still ensuring state-of-the-art performance for small models. Because RNNPool is syntactically equivalent and semantically similar to existing pooling operators, it can easily be incorporated into standard CNN architectures. We’re presenting “RNNPool: Efficient Non-linear Pooling for RAM Constrained Inference” at the 34th Conference on Neural Information Processing Systems (NeurIPS 2020).
-
 EVENT
Microsoft at NeurIPS 2020
EVENT
Microsoft at NeurIPS 2020
on-demand event

Microsoft Research Forum Episode 4
Learn about the latest multimodal AI models, advanced benchmarks for AI evaluation and model self-improvement, and an entirely new kind of computer for AI inference and hard optimization.
Check out Microsoft at NeurIPS 2020, including all of our NeurIPS publications, the Microsoft session schedule, and open career opportunities.

The memory demands of convolutional neural networks
Most popular computer vision architectures are based on CNNs, which typically consist of interleaved convolution and pooling layers. Roughly speaking, a convolution layer extracts features from an input image, while a pooling layer combines the features to provide a more succinct representation of the image. An image moves through a network’s layers until we obtain a final representation of the image, which is passed through a standard linear classifier/regressor to get the prediction for the image. The output of each layer is called the activation map and is organized as a three-dimensional tensor—n rows × n columns × n channels—where the number of channels is in general the property of the layer itself, independent of the input size. To capture a large range of discriminative features, CNNs tend to have convolution layers with a larger number of output channels, leading to large activation maps. For example, the red block in the below figure of DenseNet-121, a standard CNN architecture, represents a 56 × 56 × 256 activation map, which requires 800 KB of RAM even if each number in the map is rounded to an 8-bit integer. In our paper, we rigorously show that rearranging the computation graph of a CNN network can’t reduce the working memory (RAM) requirement. This represents a significant roadblock in deploying accurate CNNs on typical tiny devices, as these devices are powered by microcontrollers with small amounts of RAM to limit the power consumption and die area. Most Arm Cortex-M4 microcontrollers, for example, house less than 256 KB of RAM.
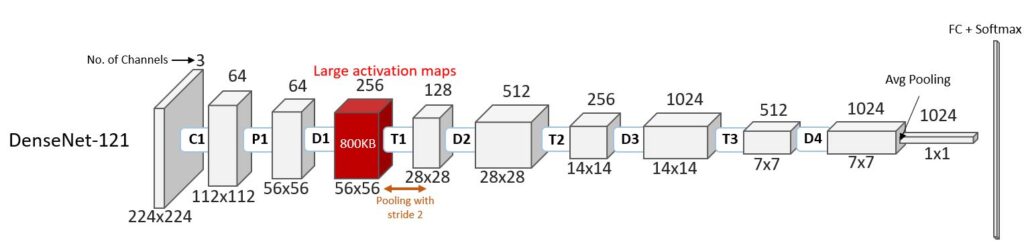
A natural approach to reducing the activation map size is to decrease the number of output channels, but that can lead to drastically lower accuracy. Another approach is to downsample the number of rows/columns of the map aggressively. For example, if we had a 28 × 28 × 256 activation map instead of the 56 × 56 × 256 map in the above example, then an image could be stored in just 200 KB. Pooling operators and strided convolutions are the standard approaches to downsampling activation maps, but they rely on relatively simple and lossy aggregation and so can lead to significant loss in accuracy if applied to a large receptive field, or patch of the image, for more aggressive downsampling. Hence, as evident in the figure of DenseNet-121, and in most standard CNN architectures, such operators are restricted to 2 × 2 receptive fields only, to ensure good accuracy. But the 2 × 2 pooling provides only a four-time reduction in activation map size, which is not sufficient for our purpose. We need to find a pooling operator that can summarize large patches of the activation map and bring down the size of the activation map in one shot. RNNPool is exactly that.
RNNPool: Applying recurrent neural networks to computer vision
RNNPool consists of two learnt recurrent neural networks (RNNs) that sweep across each patch of an activation map horizontally and vertically to summarize each patch into a single vector. We use RNNs because they tend to have significant modeling power and hence can summarize/aggregate patches well. But, unlike typical CNNs, they can still be executed with a small amount of working memory. Not only does RNNPool allow us to get rid of entire blocks of layers without losing accuracy, but we can use it in place of existing pooling layers anywhere in the network and get accuracy improvements.
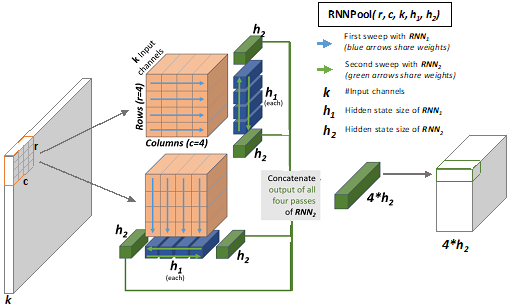
RNNPool takes a patch of an activation map and summarizes it into a 1 × 1 voxel and then strides by s steps to summarize the next patch. RNNPool can support patch sizes of 8 × 8 and even 16 × 16 and can be strided by s = 4 or s = 8 steps without significant loss in accuracy. Thus, unlike standard pooling operators, it can downsample activation maps significantly without loss in accuracy. To summarize a patch into a voxel, RNNPool uses four RNN runs: The first RNN goes over each row and column and summarizes all of them into 1 × 1 vectors of dimension h1, while the second RNN goes over these summarizations bidirectionally and produces a final 1 × 1 × 4h2 vector, where h2 is the size of the hidden state size of the second RNN.
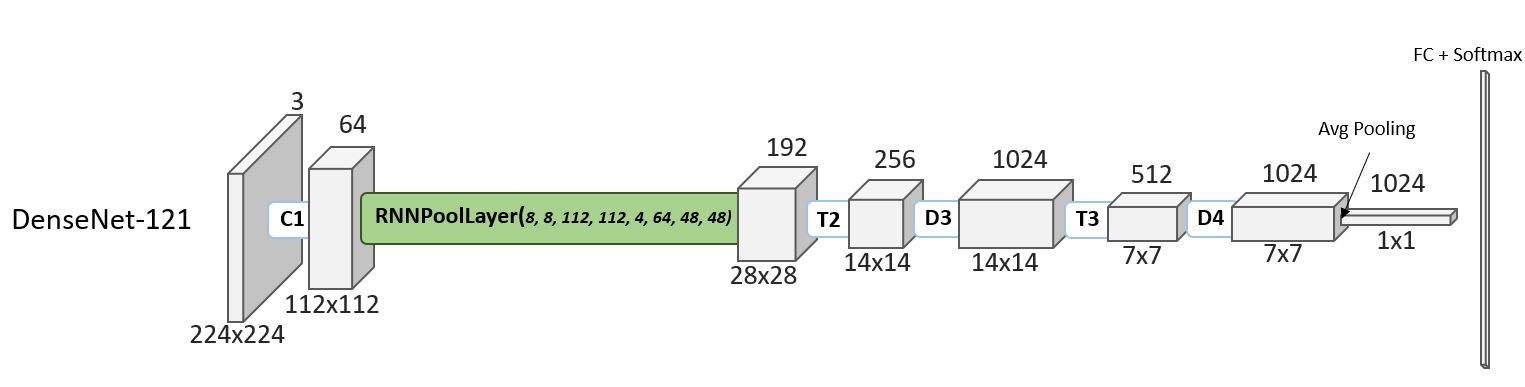
Since RNNPool is syntactically equivalent to a pooling operator, it can be used to replace any pooling operator in a CNN. But placing RNNPool in the beginning of the CNN architecture allows us to rapidly downsample the activation map, bringing down the peak RAM requirement and also skipping several layers, which provides further computational gains.
RNNPool can be used for a variety of tasks and with a variety of base architectures. The vision tasks we evaluated RNNPool on include image classification and the Visual Wake Words challenge, in which a model has to determine the presence or absence of an individual. In most of the cases, we observe that RNNPool-based models require eight to 10 times less RAM and two to three times less compute than the base models while still ensuring almost the same accuracy.
Achieving state-of-the-art in face detection
In a third evaluation, we incorporate our operator into an S3FD architecture with a MobileNetV2 backbone—a standard face detection architecture—and achieve a state-of-the-art face detection model for tiny devices. Face detection models are designed to determine if and where people are in the frame of an image or video without identifying any specific individual. In particular, the RNNPool-based model, which we call RNNPool-Face-M4, is significantly more accurate than the existing state-of-the-art model in this domain with far fewer parameters. More importantly, by using a quantization and code generation tool developed at Microsoft Research called SeeDot, we were able to ensure that the working memory of our model fit within the RAM of an Arm Cortex-M4 device. RNNPool-Face-M4 processes a single image in 10.45 seconds on an Arm Cortex-M4 microcontroller–based STM32F439-M4 device clocked at 168 megahertz. It has a peak RAM requirement of only 188 KB and model size of 160 KB.
| Method | RAM | #Params | MAdds | MAP | ||
| E | M | H | ||||
| EagleEye | 1.17MB | 0.23M | 0.1G | 0.74 | 0.70 | 0.44 |
| Rpool-Face-Quant | 225KB | 0.07M | 0.1G | 0.80 | 0.78 | 0.53 |
Such a model could be used for operational planning. For example, a system powered by RNNPool-Face-M4 could be deployed in an office’s conference rooms to facilitate better management of these spaces. Instead of an office manager physically walking the building to observe which rooms are being used at any given time, the system could provide a head count, helping to identify space that had been reserved but isn’t actually being used. Entertainment venues, such as sports stadiums, could employ a similar system to more efficiently staff its customer-services booths, directing staff members to and from booths depending on how long a line the system detects.
As mentioned earlier in the post, the local processing enabled by RNNPool can offer users of such systems, as well as any people who might be in photos taken by the system, significantly more protection of their data, as images captured by the system won’t be transferred over any networks. The images can be processed completely on the device deploying the system, after which they can be deleted from the device. Because such systems as those described above are counters, the only information being transferred off the device would be the number of people in a frame, not the images.
For the RNNPool code (opens in new tab) and code for the face detection and Visual Wake Words applications (opens in new tab), check out our GitHub repo.
Machine learning for all
Computer vision is enhancing how people go about their lives and how companies conduct their business, and bringing the technology onto the devices themselves—moving the intelligence from the cloud to the device—opens new application avenues. It also has the potential to bring the technology to even more people and scenarios.
The RNNPool operator is part of a larger effort to enable not only computer vision on resource-constrained IoT devices, but machine learning in general. RNNPool is part of EdgeML, a growing open-source library of efficient ML algorithms. Our goal with EdgeML is to democratize machine learning. The power-intensive hardware used to send data to the cloud for processing and the inferencing itself can be expensive. Microcontrollers processing data locally offer a more affordable option—intelligence at a lower cost—for businesses and individuals. Additionally, on-device processing can help in scenarios in which latency is critical. It can contribute to lowering energy demands, as well. These small devices use less power, and the energy required to transfer images to the cloud—which tends to be significantly more energy expensive than the inference itself—is also saved. The EdgeML team has been developing algorithms and architectures in the domains of speech and initial measurement unit (IMU) sensors, so RNNPool represents our initial work in the domain of computer vision. To further explore our work, visit the EdgeML project page (opens in new tab) and EdgeML GitHub page (opens in new tab).