This paper has been accepted at the 1st ACM International Conference on AI-powered Software (opens in new tab) (AIware 2024), co-located with FSE 2024 (opens in new tab). AIware is the premier international forum on AI-powered software.

Generative AI has redefined the landscape of AI assistants in software development, with innovations like GitHub Copilot providing real-time, chat-based programming support. As these tools increase in sophistication and domain specialization, assessing their impact on user interactions becomes more challenging. Developers frequently question whether modifications to their AI assistants genuinely improve the user experience, as indicated in a recent paper.
Traditional feedback mechanisms, such as simple thumbs-up or thumbs-down ratings, fall short in capturing the complexities of interactions within specialized settings, where nuanced data is often sparse. To address this issue, we introduce RUBICON: Rubric-based Evaluation of Domain Specific Human-AI Conversations,” presented at AIware 2024. RUBICON is an automated assessment technique that transforms a minimal dataset into an extensive array of domain-specific rubrics, helping ensure that updates not only modify but meaningfully improve user interactions.
Foundational communication principles
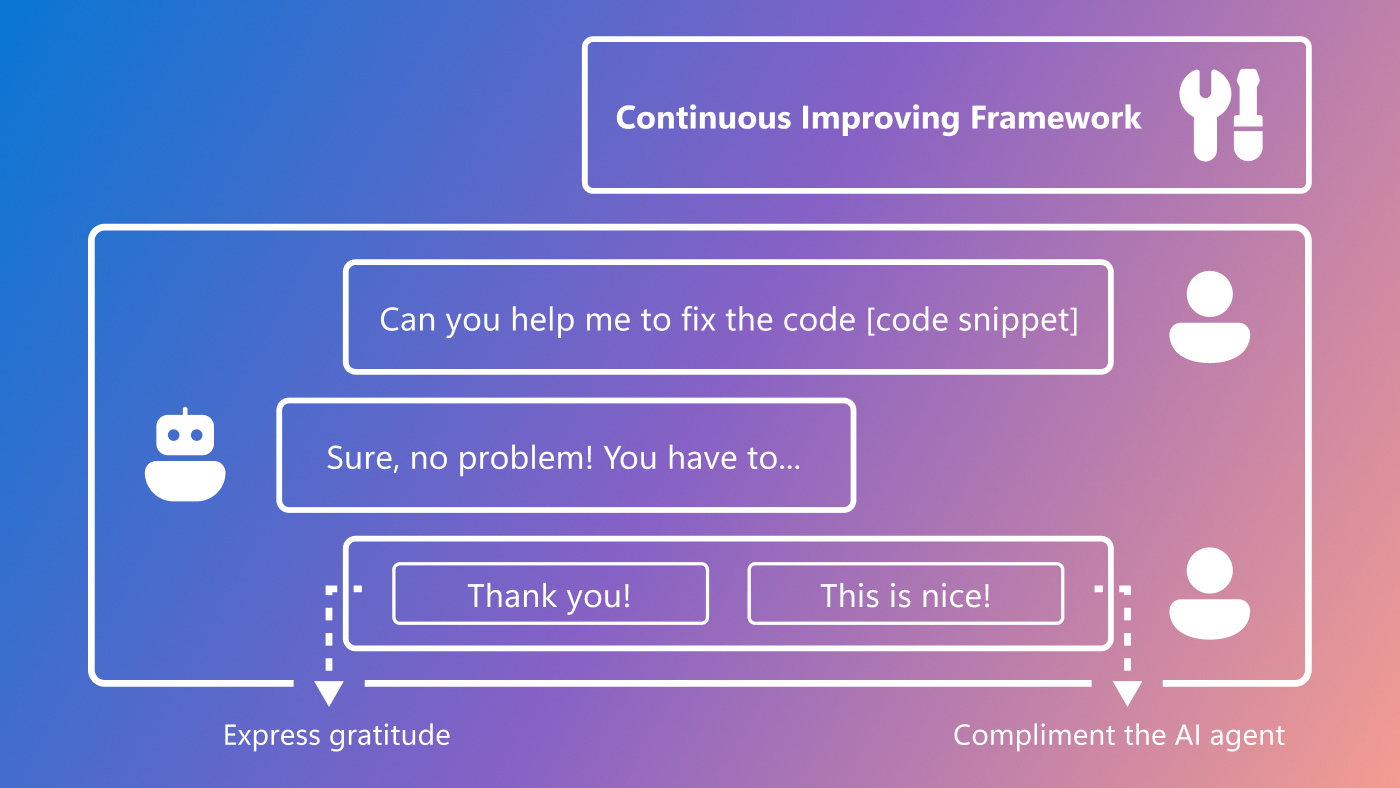
Effective conversation, whether human-to-human or human-to-AI, adheres to four maxims (opens in new tab) outlined by philosopher Paul Grice: quantity, quality, relation, and manner, ensuring that communication is concise, truthful, pertinent, and clear. In AI applications, they help create interactions that feel natural and engaging, fostering trust and empathy. Within domain-specific settings, RUBICON adapts these principles to ensure they are context-aware, improving the utility and clarity of interactions. For example, in Visual Studio, the AI helps the developer debug a program by providing detailed explanations and relevant code examples, shown in Figure 1. In Figure 2, its responses reflect that it’s guided by context.


In task-oriented environments, it’s important to assess how well a conversation aligns with user expectations and assists in achieving their goals. Conversations are only useful if they advance the user’s interests, and challenges can arise when users have misaligned expectations of the AI’s capabilities or when the AI directs the conversation too forcefully, prioritizing its methods over the user’s preferences. RUBICON balances the interaction dynamics between the AI and developer, promoting constructive exchanges without overwhelming or under-engaging. It calibrates the extent to which the AI should hypothesize and resolve issues versus how much it should leave to the developer.

GigaPath: Whole-Slide Foundation Model for Digital Pathology
Digital pathology helps decode tumor microenvironments for precision immunotherapy. In joint work with Providence and UW, we’re sharing Prov-GigaPath, the first whole-slide pathology foundation model, for advancing clinical research.
RUBICON’s rubric-based method and evaluation
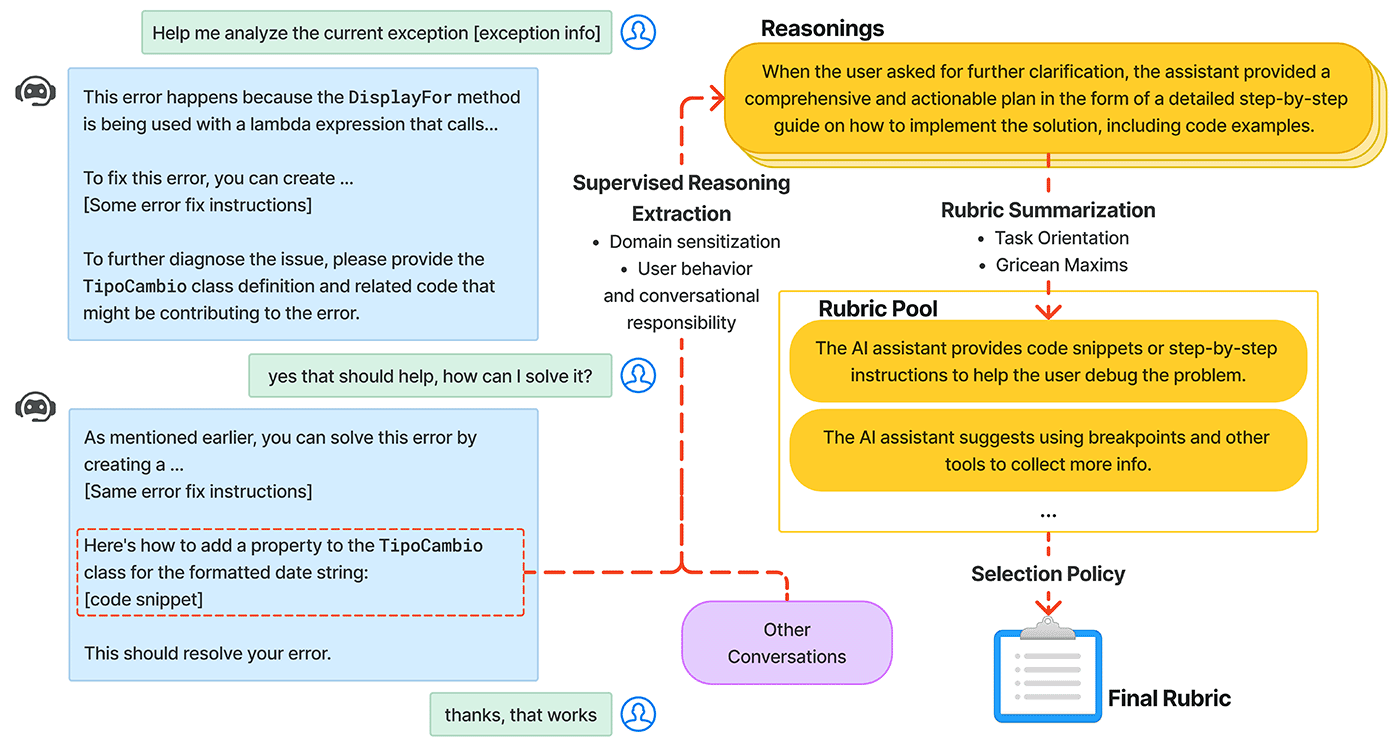
RUBICON is built on the foundational work of SPUR—the Supervised Prompting for User Satisfaction Rubrics framework that was recently introduced—increasing its scope and crafting a broad spectrum of potential rubrics from each batch of data. Using a language model to create concise summaries that assess the quality of conversations, emphasizing communication principles, task orientation, and domain specificity. It identifies signals of user satisfaction and outlines the shared responsibilities of the user and the AI in achieving task objectives. These summaries are then refined into rubrics.
RUBICON’s novel selection algorithm sifts through numerous candidates to identify a select group of high-quality rubrics, enhancing their predictive accuracy in practical applications, as illustrated in Figure 3. The technique doesn’t require human intervention and can be trained directly on anonymized conversational data, helping to ensure customer data privacy while still extracting the important features for analysis.
The effectiveness of RUBICON’s method is evidenced by its rubrics, which show an 18% increase in accuracy over SPUR in classifying conversations as positive or negative, as shown in Figure 4. Additionally, RUBICON achieves near-perfect precision in predicting conversation labels in 84% of cases involving unlabeled data.
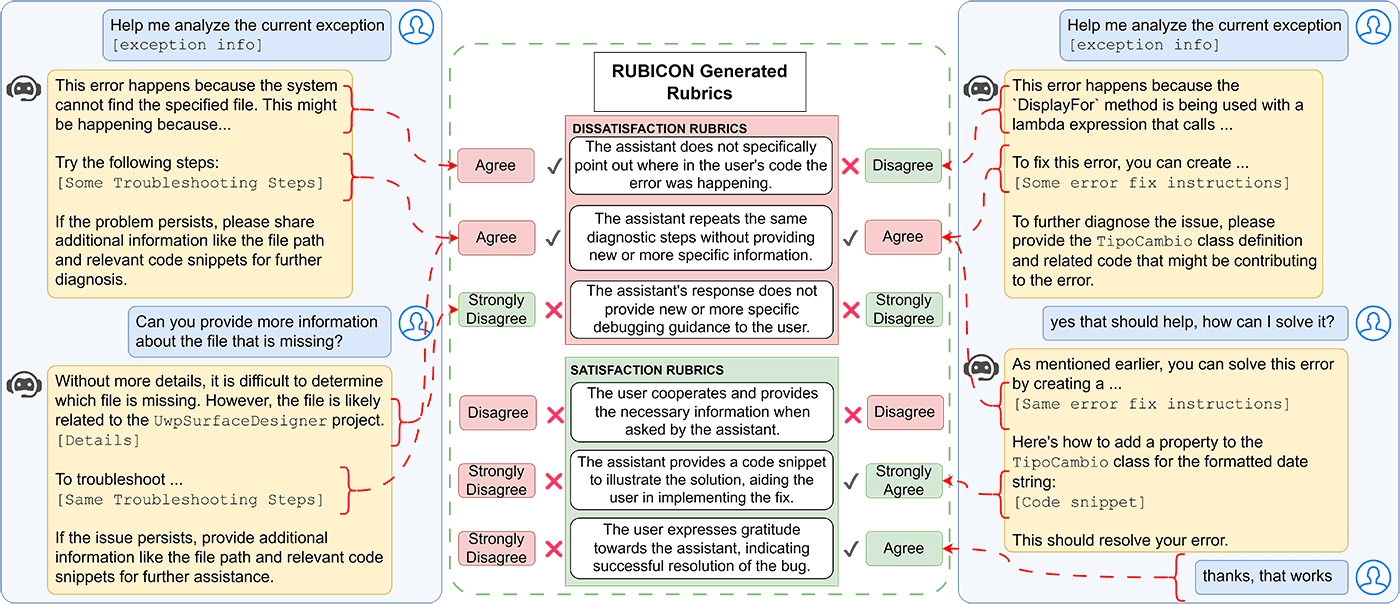
RUBICON-generated rubrics
RUBICON-generated rubrics serve as a framework for understanding user needs, expectations, and conversational norms. These rubrics have been successfully implemented in Visual Studio IDE, where they have guided analysis of over 12,000 debugging conversations, offering valuable insights into the effectiveness of modifications made to the assistant and facilitating rapid fast iteration and improvement. For example, the rubrics “The AI gave a solution too quickly, rather than asking the user for more information and trying to find the root cause of the issue,” or “The AI gave a mostly surface-level solution to the problem,” have indicated issues where the assistant prematurely offered solutions without gathering sufficient information. These findings led to adjustments in the AI’s behavior, making it more investigative and collaborative.
Beyond conversational dynamics, the rubrics also identify systemic design flaws not directly tied to the conversational assistant. These include issues with the user interface issues that impede the integration of new code and gaps in user education regarding the assistant’s capabilities. To use RUBICON, developers need a small set of labeled conversations from their AI assistant and specifically designed prompts that reflect the criteria for task progression and completion. The methodology and example of these rubrics are detailed in the paper.
Implications and looking ahead
Developers of AI assistance value clear insights into the performance of their interfaces. RUBICON represents a valuable step toward developing a refined evaluation system that is sensitive to domain-specific tasks, adaptable to changing usage patterns, efficient, easy-to-implement, and privacy-conscious. A robust evaluation system like RUBICON can help to improve the quality of these tools without compromising user privacy or data security. As we look ahead, our goal is to broaden the applicability of RUBICON beyond just debugging in AI assistants like GitHub Copilot. We aim to support additional tasks like migration and scaffolding within IDEs, extending its utility to other chat-based Copilot experiences across various products.