

|
“This is a game changer for the big data community. Initiatives like Microsoft Research Open Data reduce barriers to data sharing and encourage reproducibility by leveraging the power of cloud computing” —Sam Madden, Professor, Massachusetts Institute of Technology |
An open and collaborative research culture has always been central to research at Microsoft – as a researcher, it’s part of your job description to exchange ideas and share work among researchers, product engineers and developers at Microsoft, as well as the broader academic community.
Microsoft researchers and their collaborators have published tens of thousands of peer-reviewed papers since Microsoft Research’s founding in 1991. In the course of that research, they have created a wealth of tools and datasets that have been shared with the world to help advance the state of the art across all disciplines. They are available to be used by researchers and practitioners alike – not only in computer science and software development, but also in research across a wide variety of fields.
Spotlight: blog post

GraphRAG auto-tuning provides rapid adaptation to new domains
GraphRAG uses LLM-generated knowledge graphs to substantially improve complex Q&A over retrieval-augmented generation (RAG). Discover automatic tuning of GraphRAG for new datasets, making it more accurate and relevant.
Below is a selection of those tools and datasets; visit our researcher tools page to see hundreds more, including code and data that can be used to reproduce the results of research papers.
Read our blog, listen to our podcast, and subscribe to our newsletter to stay up to date on all things research at Microsoft.
See sections on: MSR Open Data | AI and Machine Learning | Sound, Vision, Visualization and Interaction | Accessibility and Inclusion | Privacy and Security | Systems and Programming
MSR Open Data
Microsoft Research Open Data is a data repository that makes available datasets that researchers at Microsoft have created and published in conjunction with their research. Our goal is to provide a simple platform to Microsoft’s researchers and collaborators to share datasets and related research technologies and tools. The site has been designed to simplify access to these data sets, facilitate collaboration between researchers using cloud-based resources, and enable the reproducibility of research. Visit Microsoft Open Data for the latest datasets and related research assets.
Explore more
- Blog: Announcing Microsoft Research Open Data – Datasets by Microsoft Research now available in the cloud
- Blog: Microsoft Research Open Data Project: Evolving our standards for data access and reproducible research
AI and Machine Learning
AI Fairness Checklist
AI fairness checklists can help teams mitigate potential sources of unfairness in their products by providing organizational infrastructure for formalizing ad-hoc processes and empowering individual advocates of fairness. Through a series of semi-structured interviews and co-design workshops, we co-designed an AI fairness checklist and identified desiderata and concerns for AI fairness checklists in general. This checklist can help you prioritize fairness when developing AI systems.
Explore more
- Paper: Co-Designing Checklists to Understand Organizational Challenges and Opportunities around Fairness in AI
- Checklist: AI Fairness Checklist (PDF)
AirSim
Microsoft AirSim (Aerial Informatics and Robotics Simulation) is an open-source robotics simulation platform. From ground vehicles, wheeled robotics, aerial drones, and even static IoT devices, AirSim can capture data for models without costly field operations. AirSim works as a plug-in to Epic Games’ Unreal Engine 4 editor, providing control over building environments and simulating difficult-to-reproduce, real-world events to capture meaningful data for AI models.

Using AirSim, researchers can capture data for machine learning models in a virtual environment, without costly field operations.
Explore more
- Download: AirSim Drone Racing VAE Imitation
- Blog: Game of Drones at NeurIPS 2019: Simulation-based drone-racing competition built on AirSim
- Podcast: Autonomous systems, aerial robotics and Game of Drones with Gurdeep Pall and Dr. Ashish Kapoor
Backward Compatibility ML
The Backward Compatibility ML library is an open-source project for evaluating AI system updates in a new way, to help increase system reliability and human trust in AI predictions for actions. This project’s series of loss functions provides important metrics that extend beyond the single score of accuracy. These support ML practitioners in navigating performance and tradeoffs in system updates, and they integrate easily into existing AI model-training workflows. Simple visualizations, such as Venn diagrams, further help practitioners compare models and explore performance and compatibility tradeoffs for informed choices.
Explore more
- Download: Backward Compatibility ML
- Paper: Updates in Human-AI Teams: Understanding and Addressing the Performance/Compatibility Tradeoff
- Paper: An Empirical Analysis of Backward Compatibility in Machine Learning Systems
- Paper: Towards Accountable AI: Hybrid Human-Machine Analyses for Characterizing System Failure
Datasheets for Datasets Template
Inspired by datasheets for electronic components, datasheets for datasets can be used to document characteristics of a dataset, including its motivation, composition, collection process, pre-processing, labeling, intended uses, distribution, and maintenance. Datasheets help dataset creators uncover potential sources of bias or hidden assumptions in their datasets. They help dataset consumers determine if a dataset meets their needs. Consider these questions to help prioritize transparency by creating a datasheet for your own dataset.
DeepSpeed / ZeRO
Part of Microsoft’s AI at Scale initiative, DeepSpeed is a PyTorch-compatible library that vastly improves large model training by improving scale, speed, cost and usability – unlocking the ability to train models with more than 100 billion parameters. One piece of the DeepSpeed library, ZeRO 2, is a new parallelized optimizer that greatly reduces the resources needed for model and data parallelism while massively increasing the number of parameters that can be trained.
Explore more
- Download: DeepSpeed
- Blog: ZeRO 2 & DeepSpeed: Shattering barriers of deep learning speed & scale
- Paper: ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
DialoGPT: Large-Scale Pretrained Response Generation Model
The DialoGPT project establishes a foundation for building versatile open-domain chatbots that can deliver engaging and natural conversational responses across a variety of conversational topics, tasks, and information requests, without resorting to heavy hand-crafting. These bots are enabled in part by the advent of large-scale transformer-based pretraining methods such as GPT-2 and BERT.
DialoGPT adapts pretraining techniques to response generation using hundreds of gigabytes of colloquial data. Like GPT-2, DialoGPT is formulated as an autoregressive (AR) language model, and uses a multi-layer transformer as model architecture. Unlike GPT-2, which trains on general text data, DialoGPT draws on 147M multi-turn dialogues extracted from Reddit discussion threads.
This project aims to facilitate research in large-scale pretraining for conversational data, and to facilitate investigation of issues related to biased or offensive output; accordingly it is released as a model only. This is a joint project between MSR AI and Microsoft Dynamics 365 AI Research team.
Explore more
DiCE: Diverse Counterfactual Explanations for Machine Learning
Explanations are critical for machine learning, especially as machine learning-based systems are being used to inform decisions in societally critical domains such as finance, healthcare, and education. Most explanation methods, however, approximate an ML model to create interpretable explanations. DiCE is a Python package that relies on counterfactuals to provide explanations that are always consistent with the ML model. Essentially, it provides «what-if» explanations to help explore how a model reacts to different inputs and what input changes are required to change the model’s output. Under the hood, DiCE optimizes the feasibility and diversity of generated explanations.
Explore more
- Download: DiCE
- Blog: Open-source library provides explanation for machine learning through diverse counterfactuals
- Project: DiCE: Diverse Counterfactual Explanations for Machine Learning Classifiers
DoWhy: A Python Package for Causal Machine Learning
DoWhy is an end-to-end library for causal inference that allows data scientists to build causal models based on data and domain assumptions. Consider the problem of finding out why customers churn out of a service, deciding which drugs may work best for a patient, or recommending a financial or marketing strategy: all these questions require causal reasoning and cannot be addressed by predictive modeling alone. DoWhy systematizes the best practices for causal inference in a 4-step process: modeling the assumptions, identifying the correct estimand, estimating the effect, and finally checking robustness to violation of assumptions. While prior frameworks have focused on statistical estimation alone, DoWhy recognizes the criticality of formalizing domain assumptions and uses recent research in machine learning to validate assumptions as much possible.
Fairlearn
For those who wish to prioritize fairness in their AI systems, Microsoft researchers, in collaboration with Azure ML, have released Fairlearn—an open-source Python package that enables developers of AI systems to assess their systems’ fairness and mitigate any negative impacts for groups of people, such as those defined in terms of race, gender, age, or disability status. Fairlearn, which focuses specifically on harms of allocation or quality of service, draws on two papers by Microsoft researchers on incorporating quantitative fairness metrics into classification settings and regression settings, respectively.
Guidelines for Human-AI Interaction
Advances in AI are fundamentally changing how modern-day technologies behave and creating new challenges for developing intuitive, impactful, and responsible AI user experiences. The Guidelines for Human-AI Interaction synthesize and validate more than two decades of research and thinking on human-AI interaction into a set of 18 best practices for designers and developers of AI-based systems.
The Guidelines prescribe how an AI system should behave to set the right expectations, appropriately leverage a person’s social and environmental contexts, help a person recover when the AI is wrong, and carefully learn and improve over time. They are being used by interdisciplinary teams at Microsoft to create effective AI users experiences from the start when designing and planning as well as to evaluate existing experiences and identify opportunities for improvement.
HAX Playbook
The Human-AI eXperience (HAX) Playbook is an interactive tool for generating interaction scenarios to test when designing user-facing AI systems. The Playbook helps you test AI interaction designs before building out a fully functional system. By answering a few questions about your planned system, you can generate a list of likely success and failure scenarios to design for. The tool also provides practical guidance and examples on how to inexpensively simulate system behaviors for early user testing.
Explore more
- Download: HAX Playbook
- Paper: Planning for Natural Language Failures with the AI Playbook
InterpretML
Interpretability is essential for debugging machine learning models, detecting bias, gauging regulatory compliance, and using models in high-risk applications such as healthcare and finance. InterpretML is an open-source Python package for training interpretable machine learning models and explaining blackbox systems.
Historically, the most interpretable machine learning models were not very accurate, and the most accurate models were not very interpretable. Microsoft Research has developed an algorithm called the Explainable Boosting Machine (EBM), which has both high accuracy and interpretability. EBMs use modern machine learning techniques like bagging and gradient boosting to breathe new life into traditional GAMs (Generalized Additive Models). This makes them as accurate as random forests and gradient boosted trees, and also enhances their intelligibility and editability. EBMs allow users to learn more from their data, to deploy safer, more accurate models, and to detect and correct bias that might otherwise have remained hidden.
Explore more
- Download: InterpretML
- Blog: Creating AI glass boxes – Open sourcing a library to enable intelligibility in machine learning
- Podcast: Making intelligence intelligible with Dr. Rich Caruana
MMLSpark
Microsoft ML for Apache Spark expands the distributed computing framework Apache Spark in several new directions. MMLSpark adds several machine learning frameworks to the SparkML Ecosystem, including LightGBM, Vowpal Wabbit, OpenCV, Isolation Forest, and the Microsoft Cognitive Toolkit (CNTK) . These tools allow users to craft powerful and highly-scalable models that span multiple ML ecosystems.
MMLSpark also brings new networking capabilities to the Spark ecosystem. With the HTTP on Spark project, users can embed any web service into their SparkML models and use their Spark clusters for massive networking workflows. In this vein, MMLSpark provides easy to use SparkML transformers for a wide variety of Microsoft Cognitive Services. Finally, the Spark Serving project enables high throughput, sub-millisecond latency web services, backed by your Spark cluster.
Explore more
- Download: MMLSpark
- Website: Microsoft Machine Learning for Apache Spark
- Podcast: MMLSpark: empowering AI for Good with Mark Hamilton
Project Malmo
Project Malmo sets out to address the core research challenges of developing AI that learns to make sense of complex environments, learns how to interact with the world, learns transferable skills and applies them to new problems. Malmo is an AI experimentation platform built on top of Minecraft that is designed to support fundamental research in AI. It taps into Minecraft’s endless possibilities – from simple tasks like walking around looking for treasure, to complex ones like building a structure with a group of teammates. It consists of a mod for the Java version of Minecraft, and code that helps AI agents sense and act within that environment. These components can run on Windows, Linux or MacOS, and researchers can program their agents in any language they’re comfortable with.
Explore more
- Download: Malmo
- Blog: Project Malmo, which lets researchers use Minecraft for AI research, makes public debut
TensorWatch
TensorWatch is a debugging and visualization tool designed for data science, deep learning and reinforcement learning from Microsoft Research. It works in Jupyter Notebook to show real-time visualizations of your machine learning training and perform several other key analysis tasks for your models and data. TensorWatch is designed to be flexible and extensible so you can also build your own custom visualizations, UIs, and dashboards. Besides traditional «what-you-see-is-what-you-log» approach, it also has a unique capability to execute arbitrary queries against your live ML training process, return a stream as a result of the query and view this stream using your choice of a visualizer (we call this Lazy Logging Mode).
Explore more
- Download: TensorWatch
- Blog: Microsoft makes AI debugging and visualization tool TensorWatch open source
- Paper: A System for Real-Time Interactive Analysis of Deep Learning Training
TextWorld
Text-based games may seem primitive next to the beautifully rendered graphics of today, but to succeed at even the simplest such game, humans use a special set of skills. We seamlessly and simultaneously comprehend language descriptions, plan our next moves, visualize the environment, remember important information, and generalize past experiences to new situations. AI agents don’t yet possess these capabilities, but they are key to general intelligence. Microsoft TextWorld is an open-source, extensible platform that both generates and simulates text-based games. It is a popular testing ground for AI, used by researchers to train, evaluate, analyze, and improve reinforcement learning (RL) agents that learn from and interact with the world through language.
Explore more
- Download: TextWorld
- Blog: TextWorld: A learning environment for training reinforcement learning agents, inspired by text-based games
- Blog: First TextWorld Problems, the competition: Using text-based games to advance capabilities of AI agents
- Video: Getting started with TextWorld
XGLUE
Recently, pre-trained models such as Unicoder, M-BERT, and XLM have been developed to learn multilingual representations for cross-lingual and multilingual tasks. By performing masked language model, translation language model, and other bilingual pre-training tasks on multilingual and bilingual corpora with shared vocabulary and weights for multiple languages, these models obtain surprisingly good cross-lingual capability. However, the community still lacks benchmark datasets to evaluate such capability. To help researchers further advance language-agnostic models and make AI systems more inclusive, the XGLUE dataset helps researchers test a language model’s zero-shot cross-lingual transfer capability – its ability to transfer what it learned in English to the same task in other languages.
Explore more
- Download dataset: XGLUE
- Example code: Unicoder
- Paper: XGLUE: A New Benchmark Dataset for Cross-lingual Pre-training, Understanding and Generation
- Blog: XGLUE: Expanding cross-lingual understanding and generation with tasks from real-world scenarios
XT
eXperiment Tools (XT) is an command line interface (CLI) and API for running, managing, and analyzing ML experiments. The goal of XT is to enable users to effortlessly organize and scale their ML experiments with a common run model across multiple compute platforms.
Sound, Vision, Visualization and Interaction
Phonetic Matching Library
Automatic Speech Recognition (ASR) systems tend to have trouble in noisy environments, when encountering unfamiliar accents, or when processing out-of-vocabulary words such as proper nouns and domain-specific words. Phonetic matching – comparing strings on a phoneme level rather than a character level – can help improve the accuracy and performance of these systems. Originally developed as a component of Maluuba’s natural language understanding platform, this library of phonetic string comparison utilities has been open sourced by Microsoft Research Montreal. It allows upstream systems to utilize personalized and contextual information that the Automatic Speech Recognition (ASR) systems may not have access to, in order to correct the ASR.
Explore more
- Download: Phonetic Matching Library
- Download: Phonetic Matching
- Blog: A phonetic matching made inˈhɛvən
Project Rocket
Rocket is a Microsoft Research open-source platform that allows rapid construction of video pipelines for efficiently processing live video streams – with the goal of making it easy and affordable for anyone with a camera to benefit from video analytics. This highly extensible software stack empowers developers to build practical real-world applications for object detection and counting/alerting with cutting-edge machine learning algorithms. It features a hybrid edge-cloud video analytics pipeline (built on C# .NET Core), which allows TensorFlow, Darknet, ONNX and custom DNN model plug-in, GPU/FPGA acceleration, Docker containerization/Kubernetes orchestration, and interactive querying for after-the-fact analysis. Rocket’s pipelined architecture can be easily configured to execute over a distributed infrastructure, potentially spanning specialized edge hardware (e.g., Azure Stack Edge) and the cloud (e.g., Azure Machine Learning and Cognitive Services).
Explore more
- Download: Microsoft Rocket Video Analytics Platform
- Blog: Project Rocket platform—designed for easy, customizable live video analytics—is open source
- Podcast: Live video analytics and research as Test Cricket with Dr. Ganesh Ananthanarayanan
- Project: Edge Computing
- Webinar: Microsoft Rocket: Hybrid Edge + Cloud Video Analytics Platform
RocketBox Avatar Library
To empower research and academic institutions around the world to further investigate the relationship between people and their avatars and how it affects interactions with others in the virtual world, Microsoft is making the Microsoft Rocketbox Avatar Library—a collection of 115 avatars representing humans of different genders, races, and occupations—a publicly available resource for free research and academic use. Microsoft Rocketbox can be downloaded from GitHub. The release of the library coincides with last week’s celebration of the 2020 IEEE Conference on Virtual Reality and 3D User Interfaces (IEEE VR) and the presentation of our latest in avatar research, an active area here at Microsoft Research.
Explore more
- Download: RocketBox Avatar Library
- Blog: Microsoft Rocketbox avatar library now available for research and academic use
- Video: Microsoft RocketBox Avatar Library
RoomAlive Toolkit
RoomAlive Toolkit is an open source SDK that transforms any room into an immersive, augmented, magical entertainment experience. RoomAlive Toolkit presents a unified, scalable approach for interactive projection mapping that dynamically adapts content to any room. Users can touch, shoot, stomp, dodge and steer projected content that seamlessly co-exists with their existing physical environment.
SandDance
SandDance is open-source software that enables you to more easily explore, identify, and communicate insights about your data. It provides easy to use, yet powerful, dynamic, data visualizations on large datasets, which enable pattern, trend, and outlier identification. These, in turn, provide better communication and decision making capabilities through an interface that can be embedded in your tool of choice: a custom visual in PowerBI, as extensions in Visual Studio Code and Azure Data Studio, as a stand-alone web-based application, or a react based control in a custom web application.
SandDance showcases Microsoft Research data visualization innovations and novel natural user interaction techniques and makes them available where you need them.
SandDance is available as a web-based application, as a custom visual in PowerBI, and as extensions in Visual Studio Code and Azure Data Studio.
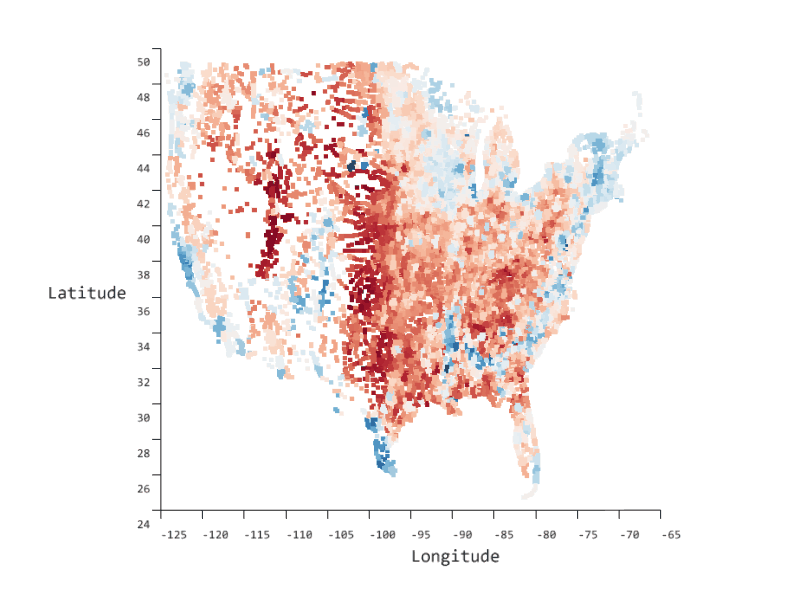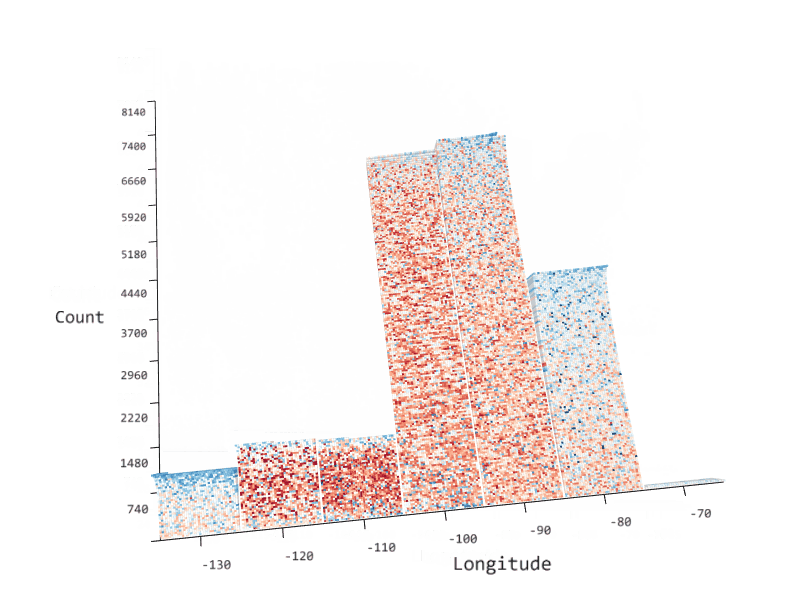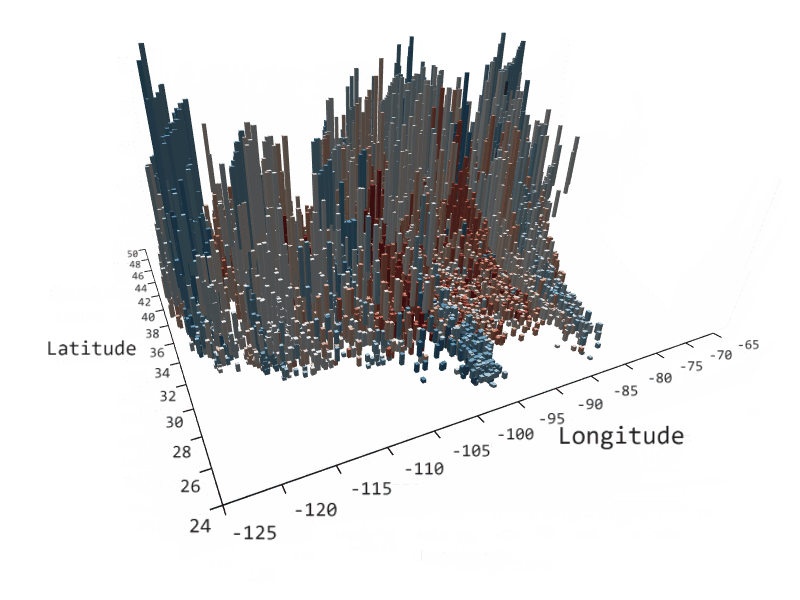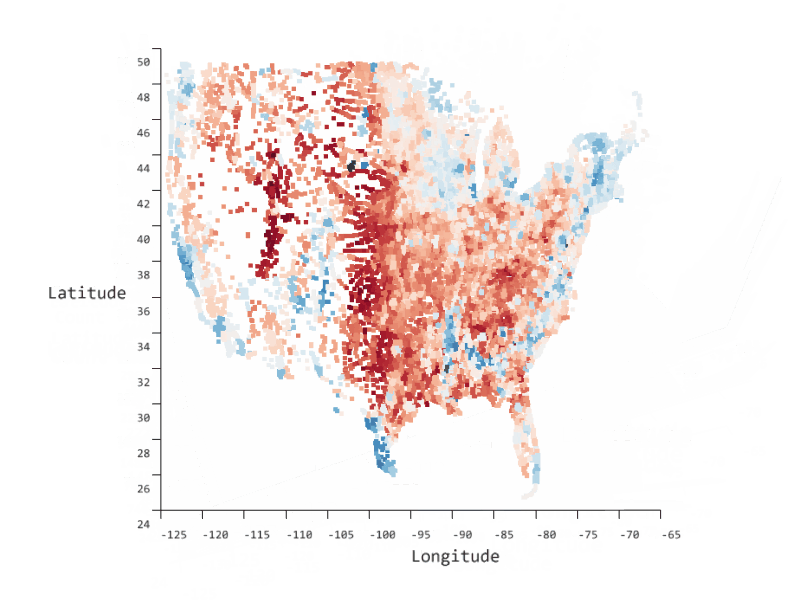
SandDance enables powerful and easy to use visualizations for large datasets.
Explore more
- Download: SandDance
- Webinar: Data Visualization: Bridging the Gap Between Users and Information
- Website: SandDance
Triton
Project Triton renders immersive acoustics that responds to the shape and materials of 3D environments in games and augmented/virtual reality (AR/VR). It is unique in modeling the true wave physics of sound, including diffraction, producing natural effects like smooth occlusion and scene-dependent reverberation. Detailed simulation is performed offline, yielding a lightweight runtime that scales from desktop to mobile phones. Incubated over a decade in Microsoft Research, Project Triton ships in major game titles like Gears of War, Sea of Thieves, and Borderlands 3. Plugin integrations for Unity and Unreal Engine are available as part of Project Acoustics.
Explore more
- Download: Project Acoustics Unity plugin and samples
- Documentation: Project Acoustics
- Podcast: Project Triton and the physics of sound with Dr. Nikunj Raghuvanshi
Accessibility and Inclusion
Caption Crawler
Caption Crawler is a plug-in for the Edge and Chrome web browsers that provides additional information about images for screen reader users. Many images on the web lack captions (i.e., alt text). When a webpage loads, Caption Crawler identifies images that are missing captions and checks if it is captioned elsewhere on the web; if so, the discovered captions are made available to the screen reader.
Explore more
- Download: Caption Crawler for Edge, Caption Crawler for Chrome
- Blog: Alt text that informs: Meeting the needs of people who are blind or low vision
Eyes First
Developed by Microsoft researchers, designers, and engineers, the Eyes First games help familiarize people with the basic skills of using eye tracking devices, which can be applied to other gaze-enabled assistive technologies. The games are designed to optimize the experiences for eye gaze input, but they are also mouse and touchscreen friendly and can be played by anyone with a compatible Windows 10 device.
The collection is powered by Windows 10 eye tracking APIs and can be used with or without Windows 10 Eye Control, a key accessibility feature that enables people with speech and mobility disabilities, including people living with ALS, to use their eyes to control an on-screen mouse, keyboard and text-to-speech experience.
The games are available for free from the Microsoft Store. The Microsoft Enable Experiences R&D team also mentors student groups on the development of additional eyes first apps and is actively expanding the Eyes First collection to include creativity experiences centered around inclusive music, art, and personal expression. This combination of research, human-centered design, empathy and creativity can help restore and redefine the experience of technology for people who are “locked in” or otherwise affected by severe speech and mobility impairment.
SeeingVR
SeeingVR is a research toolkit for making virtual reality more accessible to people with low vision – moderate to severe visual impairments that cannot be corrected fully by glasses. It includes a number of enhancements that provide visual and audio augmentations to existing VR experiences – including magnification, edge enhancement, brightness and contrast adjustment, text augmentation and text-to-speech. The toolkit also enables VR developers to add capabilities such as object descriptions and object labeling and highlighting. SeeingVR is designed to be used with the Unity VR development platform.
SeeingVR includes enhancements that help developers make VR more accessible to people with low vision.
Explore more
- Download: SeeingVR Toolkit
- Podcast: Inclusive design for all, or ICT4D and 4U! with Dr. Ed Cutrell
- Paper: SeeingVR: A Set of Tools to Make Virtual Reality More Accessible to People with Low Vision
- Video: SeeingVR: A Set of Tools to Make Virtual Reality More Accessible to People with Low Vision
Soundscape
Microsoft Soundscape is a research project that explores the use of innovative audio-based technology to enable people, particularly those with blindness or low vision, to build a richer awareness of their surroundings, thus becoming more confident and empowered to get around. Soundscape provides information about your surroundings with synthesized binaural audio, creating the effect of 3D sound. Unlike step-by-step navigation apps, Soundscape uses audio cues to enrich ambient awareness and provide a new way to relate to the environment. It allows users to build a mental map and make personal route choices while being more comfortable within unfamiliar spaces.
Learn more about Microsoft Soundscape >
Explore more
- Download: Soundscape app
- Podcast: Soundscaping the world with Amos Miller
- Podcast: Hearing in 3D with Dr. Ivan Tashev
- Project: Soundscape
Privacy and Security
ElectionGuard
ElectionGuard is an open source software development kit (SDK) that allows voters to verify for themselves that their votes have been correctly counted. The ElectionGuard SDK provides tracking codes that can be used by voters to ensure that their votes are properly encrypted and recorded, and it leverages homomorphic encryption to ensure that votes can be verifiably tallied by the public without compromising their privacy.
Explore more
- Download: ElectionGuard
- Podcast: Securing the vote with Dr. Josh Benaloh
- Webinar: Microsoft ElectionGuard—enabling voters to verify that their votes are correctly counted
EverCrypt
EverCrypt is a no-excuses, industrial-grade, fully verified cryptographic provider. EverCrypt provides the same convenience and performance as popular existing cryptographic libraries. Thanks to formal verification, EverCrypt eliminates many of the bugs that leave protocols and applications vulnerable. Usable by verified and unverified clients alike, EverCrypt emphasizes both multiplatform support and high performance. Parts of EverCrypt have been integrated in Windows, the Linux Kernel, Firefox, the Wireguard VPN and the Tezos blockchain.
EverCrypt is part of Project Everest, a multi-year collaborative effort focused on building a verified, secure communications stack designed to improve the security of HTTPS, a key internet safeguard.
Explore more
- Download: Project Everest
- Blog: EverCrypt cryptographic provider offers developers greater security assurances
- Podcast: Scaling the Everest of software security with Dr. Jonathan Protzenko
Post-Quantum Crypto VPN
Quantum computing will help us solve some of the world’s most complex challenges. However, this same computing power will also break some of today’s most commonly used cryptography.
The search for new cryptographic algorithms that cannot be attacked efficiently even with the aid of quantum computer is underway, but it will be several years before the new standards are finalized. We know it will take time to migrate all of today’s existing services and applications to new post-quantum public-key algorithms – replacing cryptographic algorithms in widely deployed systems can take years and we will need a solution that can provide protection while that work is ongoing.
One approach Microsoft Research is exploring is applying the new post-quantum cryptography to network VPN tunnels. By using both current algorithms and post-quantum algorithms simultaneously – what we call a “hybrid” approach – we comply with regulatory requirements such as FIPS (Federal Information Processing Standards) while protecting against both today’s classical attackers and tomorrow’s quantum-enabled ones.
This research project takes a fork of the OpenVPN application and combines it with post-quantum cryptography, so researchers can evaluate the functionality and performance of that cryptography. (Note: This is an experimental project and should not be used to protect sensitive data or communications.)
Explore more
- Download: Post-quantum Cryptography VPN
- Podcast: Cryptography for the post-quantum world with Dr. Brian LaMacchia
SEAL
Homomorphic Encryption allows for computation to be done on encrypted data, without requiring access to a secret decryption key. The results of the computation are encrypted and can be revealed only by the owner of the key. Among other things, this technique can help to preserve individual privacy and control over personal data.
Microsoft researchers have been working to make Homomorphic Encryption simpler and more widely available, particularly through the open-source SEAL library.
Explore more
- Download: Microsoft SEAL
- Webinar: Microsoft Research Webinar: Homomorphic Encryption with Microsoft SEAL
- Project: Microsoft SEAL
Systems and Programming
Bosque
The Bosque programming language is an experiment in regularized programming language design for a machine-assisted rapid and reliable software development lifecycle. It is a ground-up language and tooling co-design effort focused on investigating the theoretical and practical implications of:
- Explicitly designing a code intermediate representation language (or bytecode) that enables deep automated code reasoning and the deployment of next-generation development tools, compilers, and runtime systems.
- Leveraging the power of the intermediate representation to provide a programming language that is both easily accessible to modern developers and that provides a rich set of useful language features for developing high reliability & high performance applications.
- Taking a cloud-development-first perspective on programming to address emerging challenges as we move into a distributed cloud development model based around microservices, serverless, and RESTful architectures.
This project welcomes community contributions including issues, comments, pull requests and research based on or enhancing the Bosque language.
Explore more
- Download: Bosque Programming Language
- Webinar: Expanding the possibilities of programming languages with Bosque
Coyote
Mission-critical cloud services require more than 99.9 percent uptime—developers face extreme challenges in this unpredictable, high-stakes environment. Coyote provides developers with a programming library and tools for confidently building reliable asynchronous software on the .NET platform.
 Coyote allows developers to express the high-level asynchronous design directly in the code. It automatically finds deep non-deterministic safety and liveness bugs through intelligent systematic testing; and reproduces these non-deterministic bugs, facilitating easier debugging and quick fixes. It also supports both actor- and task-based programming.
Coyote allows developers to express the high-level asynchronous design directly in the code. It automatically finds deep non-deterministic safety and liveness bugs through intelligent systematic testing; and reproduces these non-deterministic bugs, facilitating easier debugging and quick fixes. It also supports both actor- and task-based programming.
Coyote is being used by several teams in Azure to build and test their distributed services.
Read more about the research behind Coyote >
Explore more
- Download: Coyote
- Blog: Coyote: Making it easier for developers to build reliable asynchronous software
- Webinar: Better design, implementation, and testing of async systems with Coyote
Project Verona
Project Verona is a collaboration between researchers Microsoft Research and Imperial College London, exploring language and runtime design for safe scalable memory management and compartmentalization. This project has been open-sourced in its early stages, to invite collaboration with academic partners on the language design; the repository linked below covers the memory management aspects of the research. (Note: This prototype is not ready to be used outside research.)
Q#
Q# (Q-sharp) is a domain-specific programming language designed for quantum application development. It is a high-level language that can express the full range of current and future quantum applications. Q# allows users to build hardware agnostic, reusable components intended for execution on a quantum processor. For debugging and development purposes, Q# programs can be executed on a simulator.



