
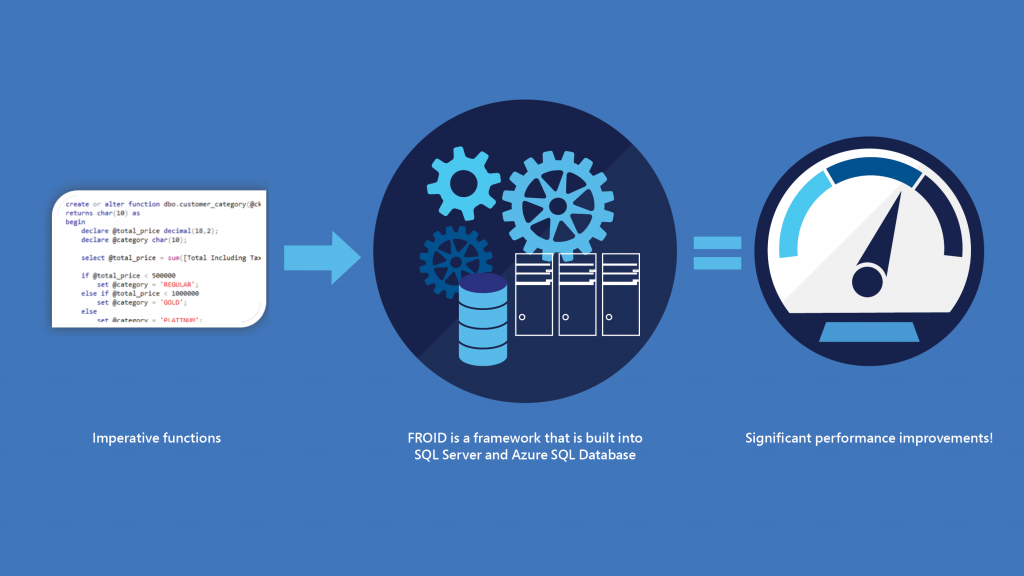
For decades, databases have supported declarative SQL as well as imperative functions and procedures as ways for users to express data processing tasks. While the evaluation of declarative SQL has received a lot of attention resulting in highly sophisticated techniques, improvements in the efficient evaluation of imperative programs have remained elusive.
Imperative User-Defined Functions (UDFs) and procedures offer several benefits over SQL, including code modularity, reusability and readability. Because of these benefits, imperative programs often are preferred by users and are widely used. Unfortunately, their poor performance discourages and even prohibits their use in many situations. Recognizing the importance of this problem and how little attention it has received, a team of computer scientists at Microsoft’s Gray Systems Lab (opens in new tab) resolved to rethink the way imperative functions are evaluated in databases.
Microsoft research podcast

Collaborators: Silica in space with Richard Black and Dexter Greene
College freshman Dexter Greene and Microsoft research manager Richard Black discuss how technology that stores data in glass is supporting students as they expand earlier efforts to communicate what it means to be human to extraterrestrials.
The outcome of their efforts is Froid, an extensible framework for optimizing imperative programs in relational databases. This work first appeared in a paper at PVLDB (opens in new tab) titled, “Froid: Optimization of Imperative Programs in a Relational Database (opens in new tab)” and is going to be presented at VLDB 2018 (opens in new tab). The purpose of Froid is to enable developers to use the abstraction of UDFs without compromising on performance. Froid introduces a radically different approach to evaluating imperative functions that results in performance improvements of up to multiple orders or magnitude over the existing state of the art.
The root cause of poor performance of UDFs can be attributed to what is known as the impedance mismatch between two distinct programming paradigms at play – the declarative paradigm of SQL and the imperative paradigm of procedural code. Reconciling this mismatch is crucial in order to address this problem and forms the crux of this work.
At the core of Froid is a novel technique that automatically can transform an entire multi-statement UDF into an equivalent relational algebraic expression. This form is now amenable to cost-based optimization and results in highly efficient, set-oriented, parallelizable execution strategies as opposed to inefficient, iterative, serial execution of UDFs.
Today’s database systems are very good at optimizing SQL queries – essentially relational algebraic expressions. One of the key advantages of Froid’s approach is that it leverages existing query optimization rules and techniques by transforming the imperative program into a form that the database query optimizer already understands. In other words, Froid reconciles the declarative-imperative impedance mismatch by transforming imperative programs into a declarative form.
Imperative programs typically go through a compiler that performs several transformations and optimizations. It can be argued that we could use well-known compiler optimization techniques to optimize UDFs as well. However, UDFs executing in a relational database present a different set of challenges and opportunities. For instance, relational operations such as JOINs and GROUP BYs could be implicit in a UDF, and a traditional compiler will not be able to infer such operations.
Froid’s approach not only infers such implicit relational operations but it also automatically brings the benefits of many of these compiler optimizations to UDFs. The relational algebraic transformations built into Froid can be used to arrive at the same result as that of applying compiler optimizations (such as dead code elimination, program slicing and constant folding) to imperative code.
Users prefer to write imperative functions and procedures in a language of their choice, the popular ones being T-SQL, C#, Python, R, Java, and so on. Although Froid’s current focus is on T-SQL UDFs, the underlying technique is language-agnostic; extending it to other imperative languages is quite straightforward.
Based on an experimental evaluation on several real workloads, we demonstrate that Froid can optimize a fairly large subset of UDFs in the wild and it can result in significant benefits in both improving performance and reducing resource (CPU and IO) utilization. Figure 1 shows the factor of improvement observed thanks to Froid on one of the customer workloads. This workload had 93 UDFs and Froid was able to optimize 86 of them. UDFs are plotted along the x-axis, ordered by the observed improvement with Froid (in descending order). The y-axis shows the factor of improvement (in log scale). You can see that the UDFs run about 5x to 1000x faster due to Froid. More details and evaluations can be found in our paper.

Figure 1 –An impressive optimization of UDFs thanks to Froid.
We believe this work will enable and encourage wider use of UDFs to build modular, reusable and maintainable applications without compromising on performance and we’re looking forward to discussing the possibilities with you in person in Rio de Janeiro at VLDB 2018! (opens in new tab)



