Humans perceive the world through many channels, such as images viewed by the eyes or voices heard by the ears. Though any individual channel might be incomplete or noisy, humans can naturally align and fuse the information collected from multiple channels to grasp the key concepts needed for a better understanding of the world. One of the core aspirations in artificial intelligence is to develop algorithms that endow computers with an ability to effectively learn from multi-modality (or multi-channel) data, similar to sights and sounds attained from vision and language that help humans make sense of the world around us. For example, computers could mimic this ability by searching the most similar images for a text query (or vice versa) and describing the content of an image using natural language.
Recently, vision-and-language pre-training (VLP) has shown great progress toward addressing this problem. The most representative approach is to train large Transformer-based models on massive image-text pair data in a self-supervised manner, such as predicting the masked elements based on their context. The cross-modal representations of the pre-training models can be fine-tuned to adapt to various downstream vision-and-language tasks. However, existing VLP methods simply concatenate image region features and text features as input to the model for pre-training and use self-attention to learn image-text semantic alignments in a brute-force yet implicit manner, leaving the model to figure out the cross-modal alignment from scratch.
Microsoft research podcast

Collaborators: Silica in space with Richard Black and Dexter Greene
College freshman Dexter Greene and Microsoft research manager Richard Black discuss how technology that stores data in glass is supporting students as they expand earlier efforts to communicate what it means to be human to extraterrestrials.
In this blog post, we introduce Oscar (Object-Semantics Aligned Pre-training) to highlight our observation that objects can be naturally used as anchor points to ease the learning of semantic alignments between images and texts. This discovery leads to a novel VLP framework that creates new state-of-the-art performance on six well-established vision-and-language tasks. Please check out our paper on this technology, “Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks,” and explore the code for more details.
Object tags as anchor points
Though the observed data varies among different channels (modalities), we hypothesize that important factors tend to be shared among multiple channels (for example, dogs can be described visually and verbally), capturing channel-invariant (or modality-invariant) factors at the semantic level. In vision-and-language tasks, salient objects in an image can be mostly detected by modern object detectors, and such objects are often mentioned in the paired text. For example, on the MS COCO dataset, the percentages that an image and its paired text share at least 1, 2, or 3 objects are 49.7%, 22.2%, and 12.9%, respectively.

Figure 1: Illustration showing the process by which Oscar represents an image-text pair into semantic space. (a) An example of input image-text pair. (b) The object tags are used as anchor points to align image regions with word embeddings of pre-trained language models. (c) The word semantic space is more representative than image region features.
An example image-text pair is shown in Figure 1a. By utilizing a pre-trained object detector such as Faster R-CNN, the image can be represented as a set of visual region features, each of which is associated with an object tag. Accordingly, the sentence can be represented as a sequence of word embeddings using pre-trained language models such as BERT. Importantly, in Oscar we construct the representations of the object tags using their corresponding word embeddings from a pre-trained BERT.
As conceptually illustrated in Figure 1b, this explicitly couples images and sentences in a shared space, allowing objects to play the role of anchor points to align the semantics of vision-and-language. The word embedding space of BERT is semantically well structured after massive pure-text pre-training—this would further provide good initialization for the shared space. In this example, dog and couch are similar in the visual feature space due to the overlap regions, but they are distinctive in the word embedding space, as illustrated in Figure 1c.
Oscar learning pipeline
With object tags introduced as a new component, Oscar differs from existing VLP in two ways:
-
- Input representation. As outlined in Figure 2 below, we define each image-text sample as a triplet, consisting of a word sequence, a set of object tags, and a set of image region features.
- Pre–training objective. Depending on how the three items in the triplet are grouped, we view the input from two different perspectives: a modality view and a dictionary view. Each allows us to design a novel pre-training objective: 1) a masked token loss for the dictionary view, which measures the model’s capability of recovering the masked element (word or object tag) based on its context; 2) a contrastive loss for the modality view, which measures the model’s capability of distinguishing an original triple and its “polluted” version (that is, where an original object tag is replaced with a randomly sampled one).
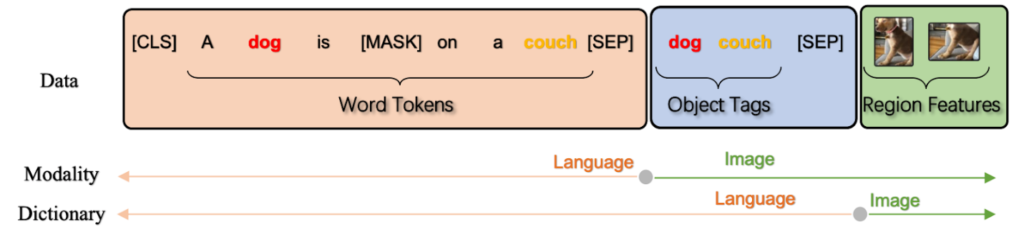
Figure 2: Illustration of Oscar input. We represent the image-text pair as a triplet [word tokens in orange, object tags in blue, region features in green], where the object tags (in this case, dog or couch) are proposed to align the cross-domain semantics; when removed, Oscar reduces to previous VLP methods. The input triplet can be understood from two perspectives: a modality view and a dictionary view.
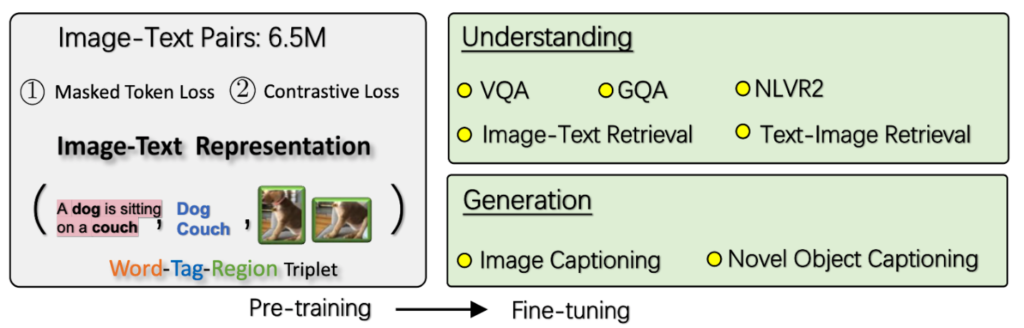
Figure 3: Oscar takes a triple as input, is pre-trained with two losses (a masked token loss over words and tags and a contrastive loss between tags and others), and it is then fine-tuned for five understanding and two generation tasks.
State-of-the-art performance
To account for parameter efficiency, we compare models of different sizes in Table 1 below. Oscar achieves new state-of-the-art performance on six tasks. Our base model outperforms previous large models on most tasks, often by a significantly large margin. It demonstrates that Oscar is highly parameter efficient, partially because the use of object tags significantly eases the learning of semantic alignments between images and texts. Here, the VLP baseline methods are collected from UNITER, VilBERT, LXMERT, VLP, VL-BERT, Unicoder-VL, and 12-in-1. Note that Oscar is pre-trained on 6.5 million pairs, which is less than the 9.6 million pairs used for UNITER and the 9.18 million pairs for LXMERT.

Table 1: Oscar achieves the best performance on six established vision-and-language tasks. SoTA (state of the art) with subscript S, B, and L indicates the best performance achieved by small, base, and large models (sizes are measured by BERT). Blue indicates the best result for a task, and rows with a grey background indicate results produced by Oscar.
Improved image-text alignment
We visualize the learned semantic feature space of image-text pairs of the COCO test set on a 2D map using t-SNE. For each image region and word token, we pass it through the model and use its last-layer output as features. Pre-trained models with and without object tags are compared. The results in Figure 4 reveal some interesting findings. The first finding is intra-class: with the aid of object tags, the distance of the same object between two modalities is substantially reduced. For example, the visual and textual representations for person in Oscar is much closer than that in the baseline method, represented as red curves in Figure 4. The second finding is inter-class: object classes of related semantics are getting closer (but still distinguishable) after adding tags, while there is some mix in the baseline, such as animals (zebra, elephant, sheep, and so on) represented as grey curves in Figure 4. This verifies the importance of object tags in alignment learning: it plays the role of anchor points in linking and regularizing the cross-modal feature learning.
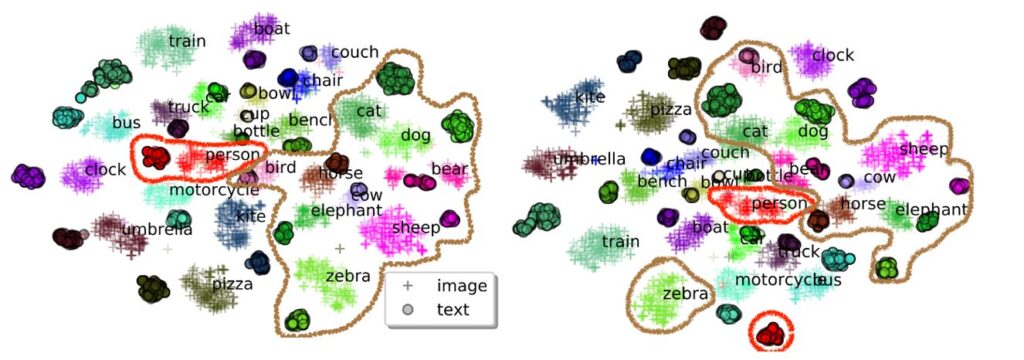
Figure 4: 2D visualization using t-SNE. The points from the same object class share the same color. Oscar (left) improves the cross-domain alignment over the baseline without object tags (right). Red and grey curves cover the objects of the same and related semantics, respectively.
Looking forward
Oscar has demonstrated the power of using objects as anchor points in aligning the image and language modalities. Interesting directions of future work include generalizing Oscar to incorporate more modalities, such as speech or multilingual abilities, and using objects as a natural bridge to distill the knowledge from images to improve natural language tasks.
Acknowledgments
This research was conducted by Xiujun Li, Xi Yin, Chunyuan Li, Pengchuan Zhang, Xiaowei Hu, Lei Zhang, Lijuan Wang, Houdong Hu, Li Dong, Furu Wei, Yejin Choi, and Jianfeng Gao. Additional thanks go to the entire Project Philly team inside Microsoft, who provided us the computing platform for our research. The implementation in our experiments depends on open source GitHub repositories; we acknowledge all the authors who made their code public, which tremendously accelerates our project progress.