Consider for a moment what it takes to visually identify and describe something to another person. Now imagine that the other person can’t see the object or image, so every detail matters. How do you decide what information is important and what’s not? You’ll need to know exactly what everything is, where it is, what it’s doing in relation to other objects, and note other attributes like color or position of objects in the foreground or background. This exercise shows there’s no question that translating images into words is a complex task—one humans do so often and innately it seems automatic at times—requiring a wide range of knowledge about many unique things.
In order to translate this skill into artificial intelligence (AI), we need to carefully consider and adapt models to the deep relationships between words and objects, the way they interrelate in expected and unexpected ways, and how contexts like environment and pose of an object affect the subtleties of associating and understanding new objects within categories. In AI, this means exploring new ways of training models, untethered to traditional annotation-reliant methods that require sentence-image pairs. To this aim, researchers from the Microsoft Azure Cognitive Services team and Microsoft Research have created VIVO (Visual Vocabulary Pretraining), an image-captioning milestone that performs pretraining in the absence of caption annotations and results in new state-of-the-art performance on novel object captioning.
Refining vision and language pretraining for novel object captioning
Novel object captioning (NOC) aims to generate image captions capable of describing novel objects that are not present in the caption training data. NOC can add value to a variety of applications, such as human-computer interaction and image-language understanding. However, NOC is a challenging problem as it requires a visual system to recognize novel objects, and it also needs a language model to generate fluent sentences describing the objects.
Recently, researchers have developed the novel object captioning challenge (nocaps) (opens in new tab) to evaluate NOC. In this challenge, existing computer vision techniques can be leveraged to recognize novel objects. For example, prior studies have proposed generating template sentences that are filled in with the recognized visual concepts from object detectors (opens in new tab). However, the captioning capability is limited by object detection vocabulary, and the context of objects can hardly be well described by pre-defined templates.
Vision and language pretraining (VLP) has shown to be effective for cross-modal representation learning. Prior works have explored training Transformer-based models on large amounts of image-sentence pairs. The learned cross-modal representations can be fine-tuned to improve the performance on image captioning, such as VLP and OSCAR. However, these prior works rely on large amounts of image-sentence pairs for pretraining. When it comes to the nocaps challenge, where no additional paired image-sentence training data is allowed, none of the prior VLP techniques are readily applicable.
This blog post introduces VIVO, developed by the Microsoft Azure Cognitive Services (opens in new tab) team and Microsoft Research, which performs pretraining in the absence of caption annotations. By breaking the dependency of paired image-sentence training data in VLP, VIVO can leverage large-scale vision datasets with image-tag pairs in pretraining to learn cross-modality alignment, building a rich visual vocabulary at scale. Our discovery leads to a new captioning framework that creates new state-of-the-art performance on the nocaps benchmark (opens in new tab) and surpasses human performance for the first time.
Please check out our paper, titled “VIVO: Surpassing Human Performance in Novel Object Captioning with Visual Vocabulary Pre-Training (opens in new tab),” for more details, and gain further insight into the researchers’ perspectives on how this breakthrough impacts caption generation in Azure AI and accessibility in this blog post (opens in new tab) from The AI Blog.
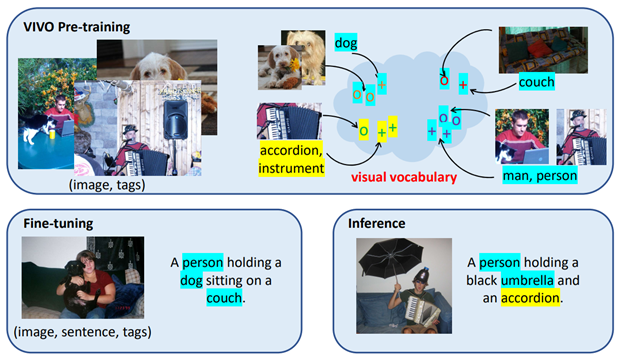
As shown in Figure 1, we define visual vocabulary as a joint embedding space where the image region features and tags of the semantically similar objects are mapped into feature vectors that are close to each other, for example “person” and “man” or “accordion” and “instrument.” Once the model is pretrained, a fine-tuning using image-caption pairs is conducted to learn caption generation. Note that the fine-tuning dataset only covers a subset of the most common objects in the learned visual vocabulary. Nevertheless, our model can still generalize to test images that contain a similar scene (like the people sitting on couches in Figure 1) with novel objects unseen in the fine-tuning dataset (like “accordion”), thanks to the visual vocabulary learned in the pretraining stage.
Our VIVO pretraining learns to ground the image regions to the object tags. In fine-tuning, our model learns how to compose natural language captions. The combined skill achieves the compositionality generalization, allowing for zero-shot captioning on novel objects.
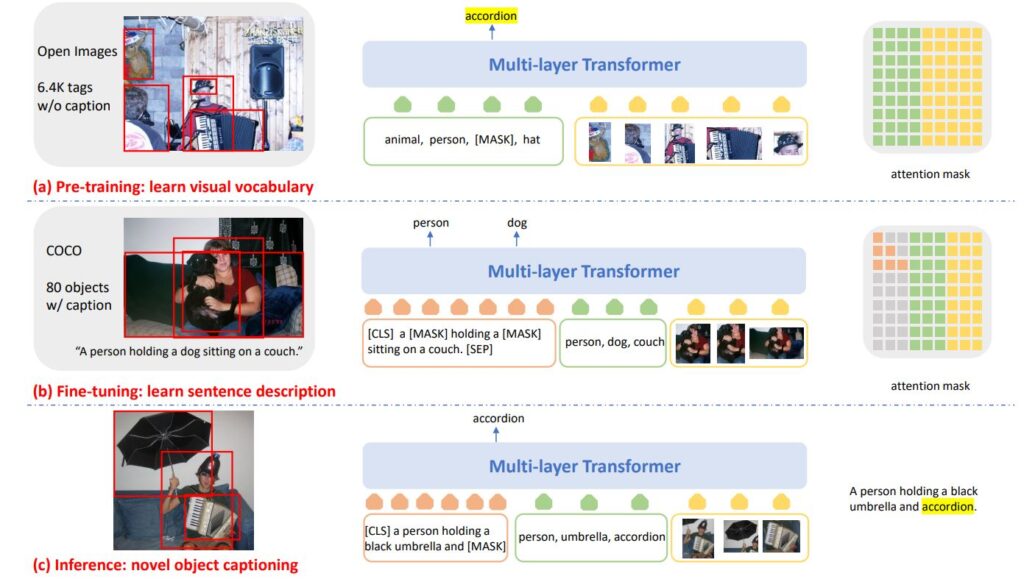
Our training scheme consists of three main stages as shown in Figure 2. In pretraining, we feed to a multi-layer Transformer model, with the input consisting of the image region features and the paired image-tag set. In these sets of tags, single images can have multiple tags associated with them. We then randomly mask one or more tags, and we ask the model to predict these masked tags, conditioned on the image region features and the other tags. Given that tags are not ordered, we develop a Hungarian matching loss for tag prediction.

About Microsoft Research
Advancing science and technology to benefit humanity
After pretraining, the Transformer model is fine-tuned on a dataset where both captions and tags are available, like the COCO dataset (opens in new tab) with 80 object classes and caption annotations. The tags can also come from prediction of a tagging or detection model.
In the inference stage, given the input image and the detected tags, our model generates a set of word tokens in an auto-regressive manner to form the final output caption.
State-of-the-art performance and exceeding human CIDEr scores
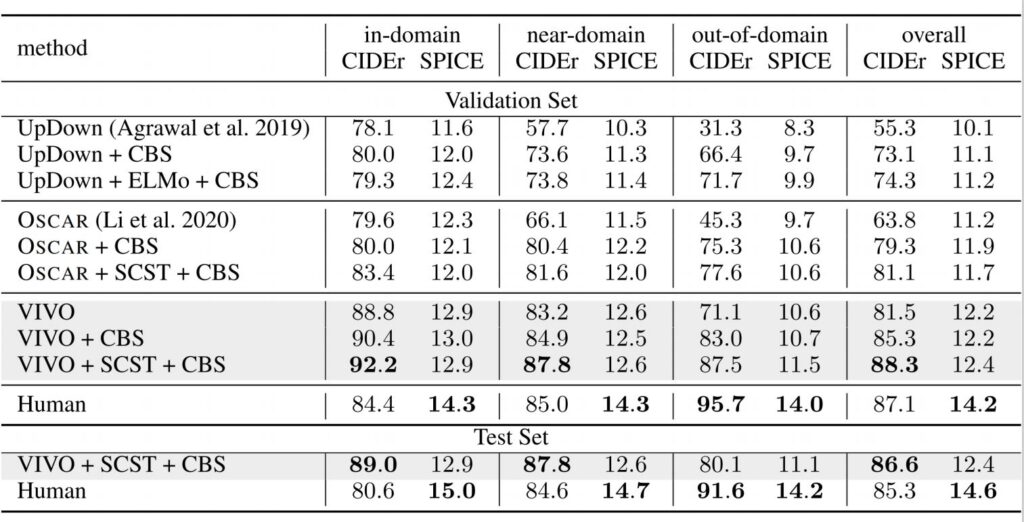
We compare our method with UpDown (opens in new tab)and OSCAR (opens in new tab), which represent the state of the art on nocaps benchmark. The training data for the baselines is the COCO dataset. Following prior settings, we also add the results after using SCST (opens in new tab)and Constrained Beam Search (CBS) (opens in new tab).
The evaluation results on nocaps validation and test sets are shown in Table 1. Our method has achieved significant improvement compared with prior works. Our plain version (VIVO) already outperforms UpDown+ELMo+CBS and OSCAR by a large margin. Our results have achieved new state-of-the-art results and surpassed human CIDEr scores (opens in new tab) on the overall dataset.
Visual-text alignment: precise localization of novel objects

To further understand the effects of VIVO pretraining in learning visual vocabulary, that is aligning image regions with object tags, we show how the novel object tags can be grounded to image regions. We estimate the similarity between the representations of each image region and object tag pair. We highlight the pairs with high scores in Figure 3. The results show that our model can precisely localize these novel objects.
Looking forward: High potential for performance improvements
We have demonstrated the power of learning visual vocabulary for novel object captioning. As the first VLP method that does not rely on paired image-sentence data, VIVO can leverage a large-scale vision dataset with image-tag pairs in pretraining. It is worth noting that using machine-generated image tags rather than human-written captions makes it possible to utilize potentially unlimited training images for improving the performance, which we will pursue in our future work.
We will have more updates in the coming months. Please check out our project page to learn more about our technology and future updates.
This research was conducted by Xiaowei Hu, Kevin Lin, Lijuan Wang, Lei Zhang, Jianfeng Gao, and Zicheng Liu from the Microsoft Azure Cognitive Services team in collaboration with Microsoft Research. This research is part of our Azure Florence research initiative on vision and language, sponsored by Microsoft Azure Cognitive Services.